

[SIGMOD 07] Execution strategies for SQL subqueries --SQL Server去相关子查询学习3

导读
本文描述了SQL Server 2005中用于高效计算包含子查询的查询的大量策略。下面是这些策略的摘要以及描述它们的章节编号。
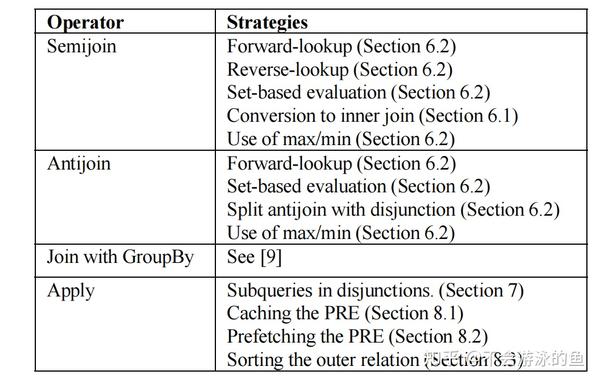
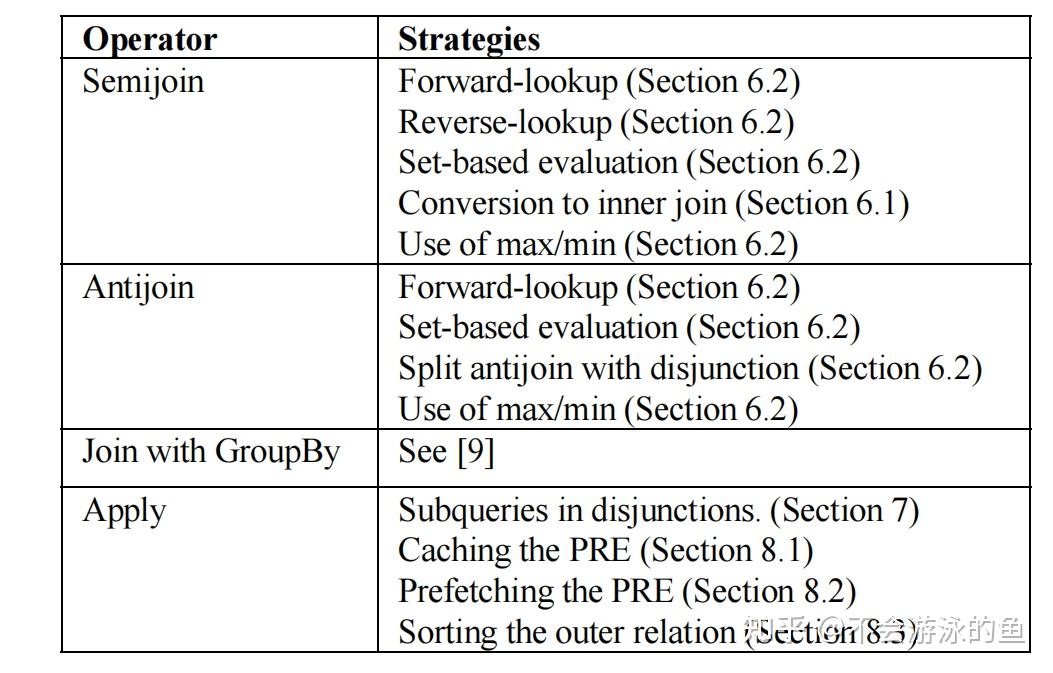
论文从必不可少的先决条件开始,例如子查询的相关性检测和删除。然后确定了一系列基本的子查询执行策略,例如正向查找和反向查找,以及set-based的方法,解释了在SQL Server中实现的子查询的不同执行策略,并将它们与当前的技术状态联系起来。
实验评价对论文进行了补充。它量化了不同方法的性能特征,并表明在不同的情况下确实需要不同的执行策略,这使得基于成本的查询优化器对于提升查询性能必不可少。
注:
- 文献9[Orthogonal Optimization of Subqueries and Aggregation,sigmod 01]中,Join和GroupBy的优化的解读见
- 文献9中提出了去除相关子查询的8个rule,本文是在这个基础上,对Apply算子向semijoin/antijoin的转换的进一步延展,并增加了Apply算子在实现层的优化
1.简介
1.1 子查询基础知识
子查询也称为内部查询或内部选择,而包含子查询的语句也称为外部查询或外部选择。
嵌套在外部 SELECT 语句中的子查询包括以下组件:
- 包含常规选择列表组件的常规SELECT 查询
- 包含一个或多个表或视图名称的常规FROM 子句
- 可选的WHERE 子句
- 可选的GROUP BY 子句
- 可选的HAVING 子句
关于子查询的详细介绍可参见 https:// learn.microsoft.com/zh- cn/sql/relational-databases/performance/subqueries?view=sql-server-ver16
1.2 子查询的处理流程
子查询的处理框架如图1所示。
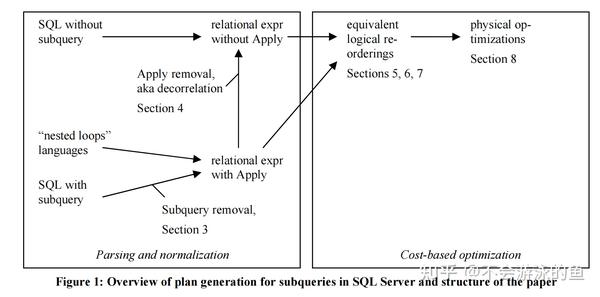
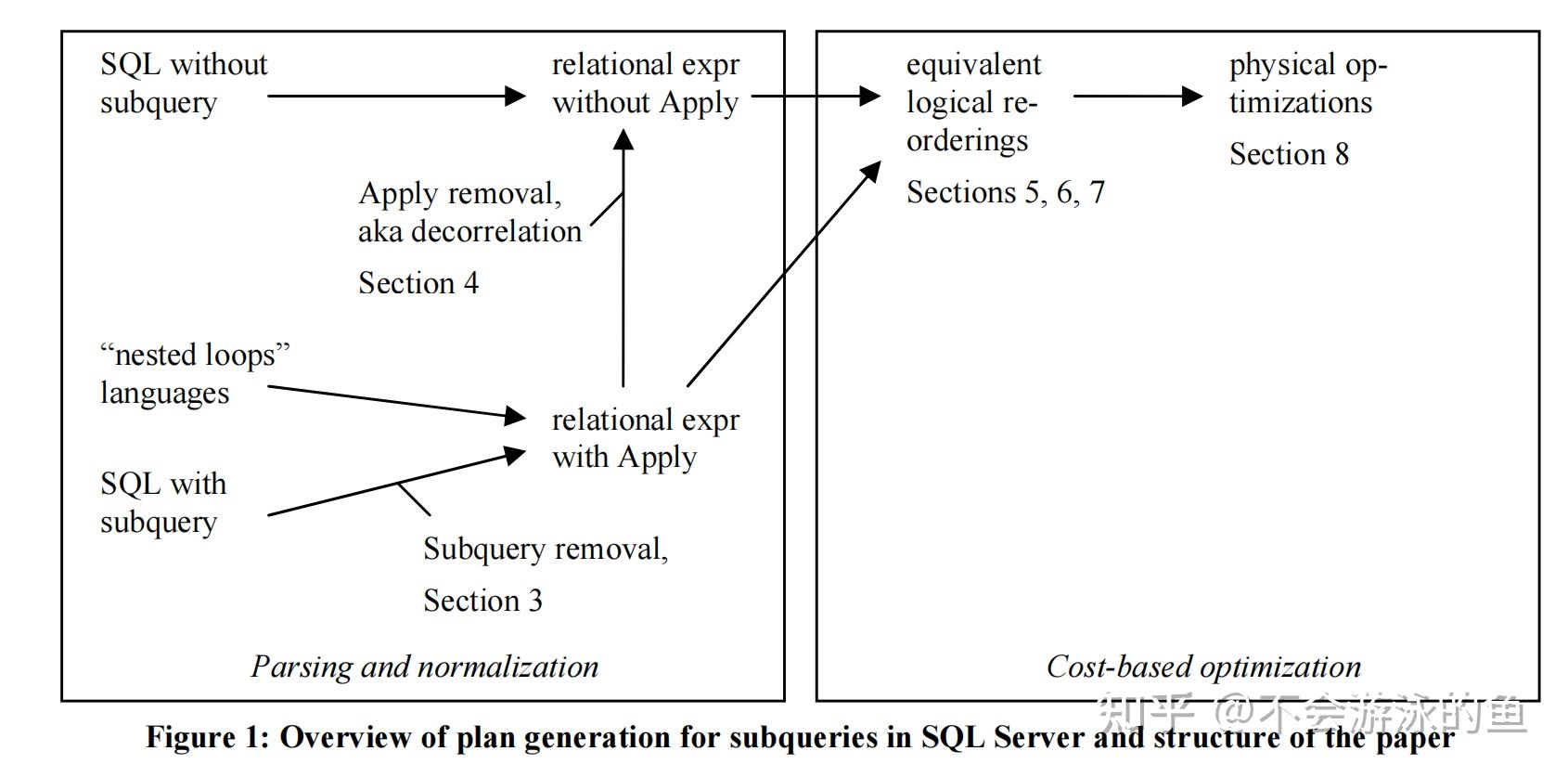
子查询处理框架分为2个环节:
(1)Parsing and normalization
这个环境是将SQL转换为AST语法树,基于CBO规则,将这个AST语法树转换为 一个 operator树。子查询的来源有三种,SQL中的相关子查询、SQL中的非相关子查询、“nested loops” languages。
(2)Cost-based优化
以上一步中的operator树作为输入,基于等价转换规则(transform rules),生成多个逻辑等价的plan,结合代价评估,选出最佳的plan。
(3)整体处理过程
- subquery removal:主要是将AST转换为基于Apply算子的operator tree, nested loop language也可以解析成为这种方式。本步骤的详细讨论见第3节
- apply算子转join算子,本步骤基于转换公式,将apply算子转换为join算子,实现子查询去关联(decorrelating),具体要根据apply算子的特征,生成相应的join,例如leftouter join、antijoin等,详见本文第4节
- equivalent logical reorderings,在逻辑优化层次进行处理,主要是基于CBO规则,生成多个逻辑上等价的plans,在第5-7节中,进行了详细的讨论,包括join和groupby的处理场景
- 代价评估,对步骤3中的多个plans,计算代价,选择最优解,期间可以通过动态剪枝的方法进行优化
(4)本文的贡献
根据外部查询和子查询的基数(cardinalities)以及数据库的物理设计,不同的子查询执行策略的性能特征可能有很大差异。这使得查询优化成为一个具有挑战性的主题。本文的讨论不局限于子查询与groupby的关系,将涵盖计划生成的逻辑层和物理层。在第10节中,我们用Microsoft SQL Server 2005对不同的子查询执行策略进行了实验评估,从定量的角度研究了不同的计划选择。实验还评估了存在子查询时基于成本的优化方法的有效性。
2.子查询的代数表示
2.1 符号
- U/UA:union all
- GA,FR:对关系R的columns A进行了GroupBy,然后执行agg函数F
- π[S]R :表示对关系R的进行投影,投影columns为S
- σ[p]R:表示对关系R执行选择,谓词为p,是对R中rows的过滤条件
- CT(1):表示一个常量表,仅返回1行,且无columns
- PRE:parameterized relational expression,可以理解为其左节点为参数列表,右节点为一个函数,遍历左节点的参数列表,对每一个参数执行右节点的函数,返回一个结果
- Apply:调用PRE,执行子查询。R是子查询中的外部查询表,Apply一次从R中读取一条数据作为其右节点执行函数的参数。E(r)表示其右节点的表达式函数。JN表示一种join类型,例如 inner, outer, semijoins
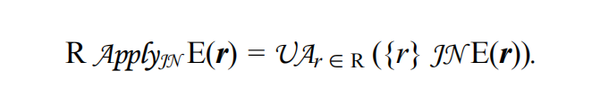
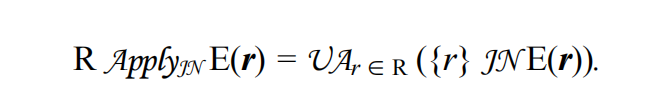
- R JNp S:inner join
- R LOJp S,R与S执行left outer join,join谓词为p,以R为主,对于S中的unmatched row,全部填充为NULL
- R SJp S:semijoin
- R ASJp S:antijoin,(R SJp S) UA (R ASJp S) = R
一些规则:
- 如果子查询的结果为NULL,那么对于标量子查询来说,返回值也是NULL
- 如果标量子查询的结果为single row{a},那么返回a
- 如果标量子查询的结果为多个rows,那么返回run-time error,标量子查询必须满足max1row
2.2 Language surface
子查询可以位于SQL语句中的SELECT、FROM、WHERE子句:
- 如果子查询位于FROM子句,称之为“derived table”
- 如果子查询位于SELECT、WHERE子句,称为“subquery”。如果subquery具有相关性,那么它需要由外部查询提供参数,与“derived table”不同,“subquery”需要跨越关系域和标量域
标量子查询类型
- Existential test.使用关键字“EXISTS”和“NOT EXISTS”,用来测试子查询的结果是否为空。结果是bool类型,true或false
EXISTS(SELECT * FROM ORDERS
WHERE L_SHIPDATE < O_ORDERDATE). - Quantified comparison. ANY、ALL,返回结果true、false或unknown。
L_SHIPDATE > ANY(
SELECT O_ORDERDATE
FROM ORDERS
WHERE L_ORDERKEY = O_ORDERKEY). - IN / NOT IN
- IN 等价于 = ANY
- NOT IN 等价于 <> ALL 。
- Scalar-valued,返回非bool值标量
(SELECT C_NAME FROM CUSTOMER
WHERE C_CUSTKEY = O_CUSTKEY).在SQL Server语法中,支持Apply操作符处理子查询。常见的使用场景是调用参数化表值函数,这是PREs的一种特殊情况。例如, 假设您有一个表值函数,它接受一个字符串并将其分割成单词, 每个单词输出一行 。 你可以使用下面的方法对MYTABLE中的COL列的值调用这个函数:
SELECT *
FROM MYTABLE
OUTER APPLY CHOP_WORDS(MYTABLE.COL) 上述SQL中,类似于nestloop join。外部查询从MYTABLE表中查出1条数据,子查询中,对这个数据中的COL列值执行CHOP_WORDS函数,将COL值分割成单词,每个单词输出一行,返回多行结果。然后用外部查询中输出的1个row与这个子查询结果(多row)执行outer join。理解上,当然,SQL Server对于这种apply算子还会有进一步的优化,最终转换为效率最高的join查询。但如果CHOP_WORDS函数结果为空,则由于使用了OUTER,该行仍然被保留。
3.子查询去相关性
3.1 Mapping multi-row relational results to a single scalar value
对于一个标量子查询E(r),子查询的计算形式如下:
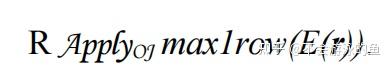
max1row是一个特殊的关系操作符,其输入和输出是相同的。如果其输入超过1行,则返回run-time异常。如果经过静态分析,能够检查出E(r)最多返回1行,也就是说E(r)计算结果与输入的参数和数据库当前的状态无关,此时可以移除max1row算子。例如,子查询中仅是简单计算了sum。如果子查询中采用了sum+groupby的方式,有可能返回多条结果,这是不可以移除max1row。
3.2 Filtering through existential test
existential test,个人理解为 EXIST或NOT EXIST,返回结果为TRUE或FALSE。
如果在E(r)中直接使用了EXISTS和NOT EXISTS作为过滤条件,我们将过滤操作与子查询的求值结合在一起,描述如下:
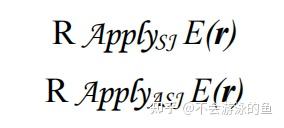
在上面描述的通用重写过程中,如果满足EXISTS或NOT EXISTS,子查询返回常量TRUE,否则为FALSE。这时EXISTS子查询与SQL WHERE子句中的其他条件一起被使用。
3.3 Conditional scalar execution
SQL支持case when条件表达式,可以通过apply算子实现这个表达式,这时需要apply算子能够提供probe和passthrough功能,示例说明如下:
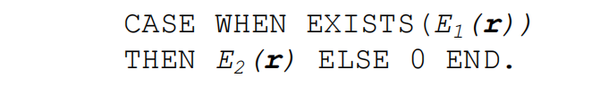
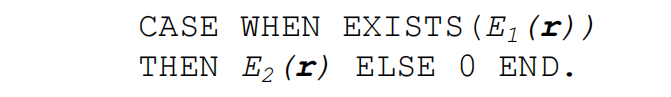
这里,EXISTS子查询并不是直接作用于对rows的过滤上,而是用来决定到底采用哪个标量表达式计算结果的。可以用如下的apply算子表达:
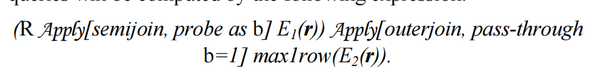
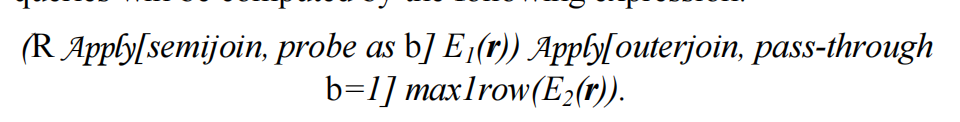
- Apply with probe以关系R的行r作为参数,并添加一个新列b,当E1(r)非空时,b为1
- Apply with passthrough有一个守卫谓词b=1,只有当b=1为TRUE时才执行它的子查询,这实现了所需的条件求值
假设标量值子查询E2(r)的结果留在列e2中,原始标量表达式被替换为:
CASE WHEN p = 1 THEN e2 ELSE 0 END.
3.4 Disjunctions of subqueries
OR条件中的子查询,示例如下:
Example 1 Disjunction of uncorrelated EXISTS and IN subqueries:
SELECT COUNT(*)
FROM supplier
WHERE s_suppkey IN (SELECT MAX(l_suppkey)
FROM lineitem
GROUP BY l_linenumber)
OR EXISTS (SELECT p_brand
FROM part
WHERE p_brand = ‘Brand#43’);
Example 2 Disjunction of uncorrelated EXISTS subqueries:
SELECT COUNT(*)
FROM supplier
WHERE EXISTS (SELECT l_suppkey
FROM lineitem
WHERE l_suppkey = 12345)
OR EXISTS (SELECT p_brand
FROM part
WHERE p_brand = ‘Brand#43’);
Example 3 Disjunction of uncorrelated scalar or IN subquery predicates:
SELECT COUNT(*)
FROM supplier
WHERE s_acctbal*10 > (SELECT MAX(o_totalprice)
FROM orders
WHERE o_custkey = 12345)
OR substring(s_name, 1, 6) IN (SELECT c_name
FROM Customers
WHERE c_nationkey = 10);
Example 4 Disjunction of correlated/uncorrelated quantified comparison subqueries:
SELECT COUNT(*)
FROM lineitem
WHERE l_suppkey > ANY (SELECT MAX(s_suppkey)
FROM supplier
WHERE s_acctbal >100
GROUP BY s_nationkey)
OR l_partkey >= ANY (SELECT MAX(p_partkey)
FROM part
GROUP BY p_mfgr);
Example 5 Disjunction of any correlated subquery predicates:
SELECT COUNT(*)
FROM supplier S
WHERE EXISTS (SELECT l_suppkey
FROM lineitem
WHERE l_suppkey = S.s_suppkey)
OR EXISTS (SELECT p_brand FROM part
WHERE p_brand = ‘Brand#43’
AND p_partkey > S.s_suppkey);OR中的子查询难以使用Apply算子转换为Join。论文提出使用union的方式进行处理。其实,核心思想就是将or转成了union。
假设存在一个标量过滤条件:p(r) OR EXISTS(E1(r)) OR EXISTS(E2(r)),p(r) 是不含子查询的标量谓词,将其映射为如下Apply算子。
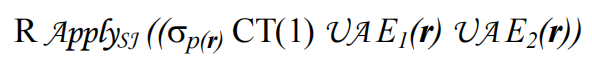
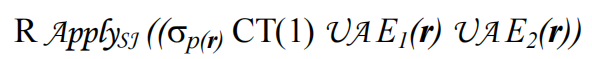
- 标量谓词p对常量表CT(1)求值,CT(1)返回一行,不返回列。例如count(*) > 100,此时CT(1)就是count(*)返回的常量
- 上述公式中Apply的右表达式中,三个条件取union all,表示只要有1个表达式为TRUE,则返回R中的一行
- 上述Apply算子可以使用如下规则6->规则2->join的方式优化


3.5 Dealing with quantified comparisons
本节主要描述对于存在NULL值的情况下,如果将ALL、ANY转换为 existential test (EXIST、NOT EXIST),进而转换为JION。
quantified comparisons是指ALL、ANY。我们通过将ALL、ANY映射到我们已经讨论过的 existential test 来处理。但对于NULL值情况,要特殊处理。
例如谓词p 5 NOT IN S,等价于5 <> ALL(S),根据不同类型的S,p的结果如下:
1. If S = {} then p is TRUE.
2. If S = {1} then p is TRUE.
3. If S = {5} then p is FALSE.
4. If S = {NULL, 5} then p is FALSE.
5. If S = {NULL, 1} then p is UNKNOWN.
同样,NULL NOT IN S is UNKNOWN for any S <> {}.
Case 5中,从直觉上看,5 NOT IN {NULL, 1} 应该返回TRUE。但在数据库实现中,其返回了UNKNOWN(个人理解为NULL)。这是源于SQL中的three-valued logic
- value NULL is UNKNOWN;
- UNKNOWN AND TRUE is UNKNOWN
Three-valued logic中IS运算符的结果为TRUE或FALSE,其余运算符还包括了NULL,规则如下:
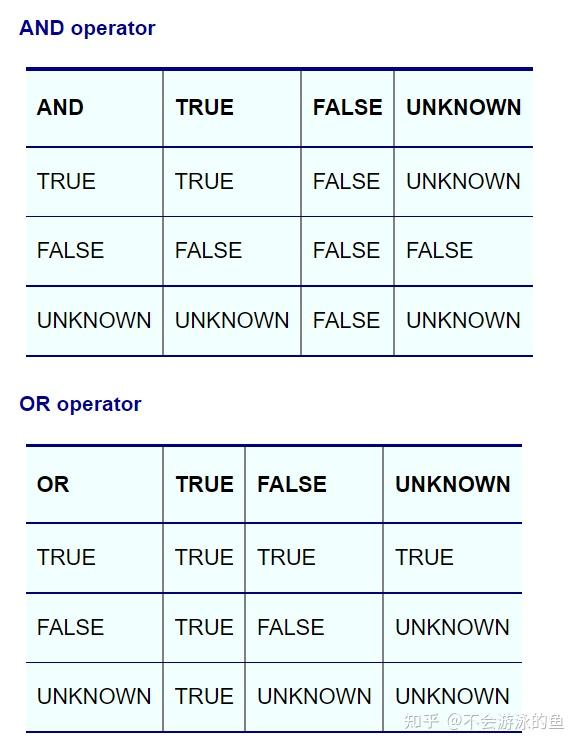
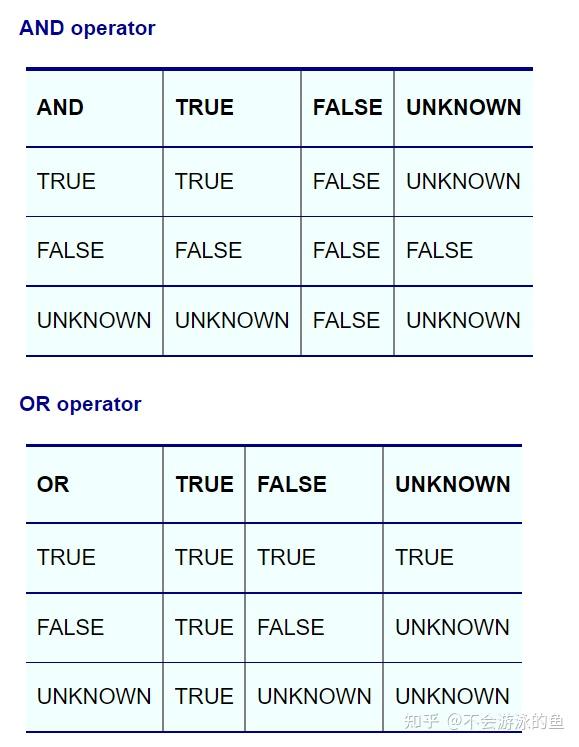


<> 或 = ALL、<> 或 = ANY运算符返回TRUE、FALSE或UNKNOW,我们希望把这种场景转换为EXIST或NOT EXIST,但此时仅返回TRUE、FALSE,那么如何处理ALL、ANY中的NULL情况?
应用场景
对于selecting rows,很难区分 FALSE 和 UNKNOWN,例如使用谓词p过滤rows,如果p的结果为FALSE或UNKNOWN,结果相同,均过滤掉。在CASE WHEN中,CASE遇到 FALSE 和 UNKNOWN,处理方式也是相同的。
对于一个bool表达式P(X1,X2,...,Xn)=Y,仅适用了逻辑连接符AND和OR,假设Xi的值为UNKNOWN,如果将Xi的值从UNKNOWN改为FALSE,Y的值或不变,或从UNKNOWN改为FALSE。所以,对于用于过滤行或CASE WHEN的布尔表达式,将量化比较的结果从三值(TRUE、FALSE或UNKNOW)更改为两值(TRUE、FALSE)是有效的。
等价变换步骤
变换目标:NOT EXISTS -> antijoin
(FOR ALL s ∈ S: p) = (NOT EXISTS s ∈ S: NOT p)
然而,这个等式只适用于二值逻辑,而不适用于SQL的三值逻辑(根本原因在于 NOT UNKNOWN的结果仍为UNKNOWN)。因此,mapping过程分为2个步骤:
- 改变通用量化表达式σ,使其不涉及UNKNOWN值
- 对谓词取否
对于谓词 p = A B
- 将其改写为p‘ = A B AND A IS NOT NULL AND B IS NOT NULL,因为,如果A或B为NULL,p的结果也是NULL。所以可以将其改为2值谓词,当A和B为TRUE时,p‘ 返回TRUE。当A或B为FALSE或NULL时,返回FALSE。同样适用于CASE WHEN
- 对谓词p’取否创建NOT EXIST谓词,A B OR A IS NULL OR B IS NULL, cmp’是有原来的cmp变换而来,当然,如果A或B是非空字段,可以在预处理阶段移除A IS NULL OR B IS NULL,因为二者为FALSE,即A B OR FALSE OR FALSE。
示例
以子查询A NOT IN S为例
- 等价变换为A <> ALL S
- 再次等价变换为NOT EXISTS子查询,即,NOT EXISTS(σ[A = s OR A IS NULL OR s IS NULL] S)
- 再次等价变换为含有OR的antijoin,利用antijoin的优化规则进一步优化
4. REMOVING APPLY
在SQL Server的优化器处理流程:
- query text - > operator tree
- RBO,对operator tree执行normalize,例如检测并删除冗余条件,normalize的结果是一个唯一的,经过RBO规则简化处理的operator tree
- CBO,对RBO阶段输出的operator tree,基于等价变换规则+代价评估模型,生成最佳查询计划
5. OPTIMIZING SUBQUERIES USING MAGIC SETS(semijoin、antijoin)
5.1 The magic set technique
magic set是一种古老的子查询优化技术,应用于演绎数据库(deductive database),即具有推演能力的数据库。
演绎数据库是在传统的数据库(关系型数据库)上增加一组规则以及建立一个推理机制,使之能在现有的数据库数据上演泽出新数据的功能。演绎数据库的推理机制是演绎数据库库的核心,它的主要内容是一些演绎推理算法,其中主要是递归查询算法,这些算法可以分为自顶向下和由底向上两类。 来自:《计算机科学百科全书》
magic set子查询优化技术首先将子查询表示为函数,这点类似于Apply算子。
本节以下内容不是很理解,待学习相关开源源码后,再更新
一个关键的观测点是,如果外表R中参与子查的rows很少,那么这个函数可以扩展地表示为一个表。这个扩展表会额外增加列,包含预先计算过的函数的参数值。再将函数转换成join:
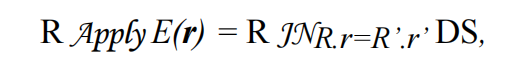
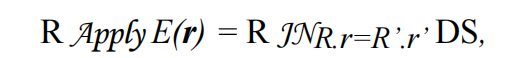
上面的公式基于magic set对apply算子(semijoin、antijoin)进行优化
- Apply -> R inter join R.r,应用了图4中的公式2,将Apply转换为inter join
- R inter join R.r -> R'.r'DS
DS,称为“decoupled query”,存储R中的每个r执行E(r)的结果的union,DS计算公式如下:
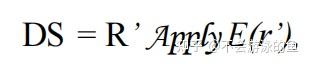
R‘称为magic set,是R的一个子集,这个集合中的每个row都是E(r')的参数,R’的一个可能结果为distinct[R.r] R。当然,这两个方程可以放在一起,这样就不需要显式地存储DS的值。该结果可以看作是分布式系统中使用的半连接减少不需要参与计算的rows的策略的推广。
5.2 Magic on join / group by scenarios
未理解,先略
6.优化 SEMIJOIN 和 ANTIJOIN
去除相关性子查的过程中会生成包含semijoins、antijoins和outerjoins的树。因此,需要对其进行优化。在本节中,我们将集中讨论semijoins和antijoins。
6.1 Reordering semijoins and antijoins
【semijoins 和 antijoins的下推上拉优化,最终转outer join】
从reordering的角度看,semijoins 和 antijoins与fliters的优化非常相似,都可以上拉或下推。例如,在一个SQL查询中,如果filter不需要使用agg的结果作为判定条件,那么这时filter是可以下推到GroupBy算子下的。同理,如果semijoins 和 antijoins的join谓词中没有使用agg结果,那么semijoins 和 antijoins也可以下推到GroupBy算子下。
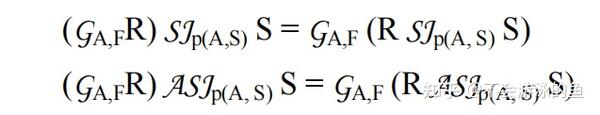
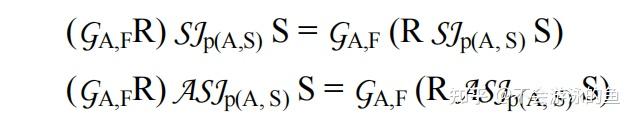
将semijoins 和 antijoins重新排序,就像它们是过滤器一样,这是一个强大的工具,但如果S中包含多个表,那么上述等式中,仍然将关系S中的表作为一个多表JOIN后的块保存在一起。如果我们想对S中的各个表重新排序(join次序),我们必须注意结果中重复的行和可见的列。对于这个问题,有一个恒等式可以给出一个简单的通解:
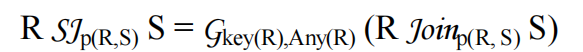
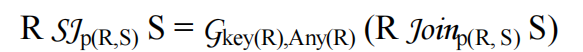
上式将semijoin转换为outerjoin,主要是增加了基于R主键的agg函数(Any),用于去重,这样就可以使用outerjoin的reorder技术,进一步优化。
【不进行semijoin 转 inner join的低效示例】
SQL:查找1995年1月1日的订单数量(ORDERS表), 需要满足条件:在同一个城市,至少有一个供应商(SUPPLIER表)和客户(CUSTOMER表)在同一个国家,并且产品(LINEITEM表)在订单后7天内发货。
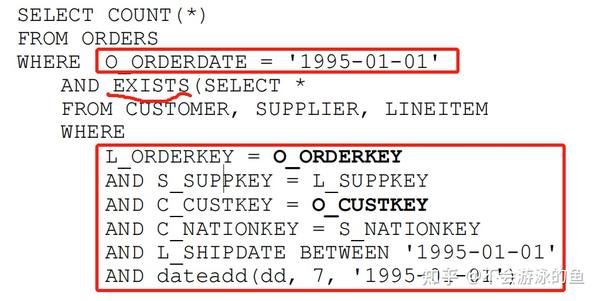
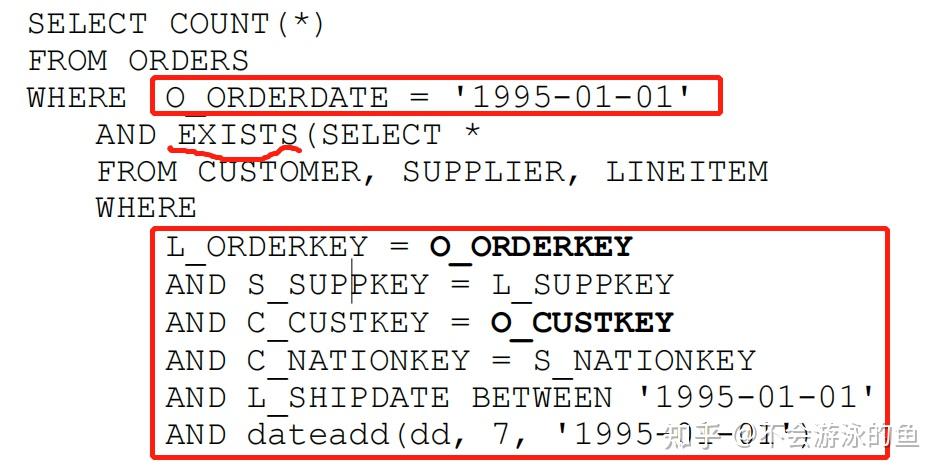
将EXIST子查询转换为semijoin,如下
ORDERS SJ (CUSTOMER JN SUPPLIER JN LINEITEM)
semijoin的右侧是CUSTOMER、SUPPLIER、LINEITEM三表inner join,不能对这三个表与ORDERS表使用join reorder技术,因为使用后,count(*)有可能返回错误结果。因此,在执行过程中,我们不得不采用如下的做法:
- 策略1:hash join或merge join,先执行CUSTOMER、SUPPLIER、LINEITEM三表inner join,生成result,在执行ORDERS semijoin result
- 策略2:nestloop join或index join,依次从ORDERS读取1条数据,作为条件,执行CUSTOMER、SUPPLIER、LINEITEM三表inner join。
这两种策略都是低效的。因为,ORDERS和LINEITEMS上的谓词都能过滤掉大量无关数据,因此最好先join ORDERS和LINEITEMS,然后再将这个join结果与其余表连接。这正是将semijoin转换为join所要做的。
【semijoin 转 outer join 转 inner join】
将semijoins转为innerjoins后,可以充分利用inner join的join reorder规则,生成等价plans,结合代价评估选择最优解。因此,有动机在normalization阶段(RBO)将semijoin等价变换为inner join。但问题是,对semijoins转换为innerjoins过程中需要为每个semijion创建GroupBy(distinct)操作符,但GroupBy的增加位置不是一项容易的任务,可能会增加编译时间。因此,最好是将semijoin转换为innerjoin放置在CBO阶段。
【ansijoins 转outer join 转inner join】
ansijoins两侧的表不能以 【semijoin 转 outer join 转 inner join】 方式混合,因为没有简单的标识可以将它们转换为 inner joins。
6.2 semijoin和ansijoin效率评估
semijoin和ansijoin可以使用所有标准join实现进行计算,即nested loop join, hash join, merge join 和index lookup join。
- 计算semijoin时,可以使用这些jion算法,不需要任何特殊操作
- 计算antijoins时,使用标准join时,需要一些特殊的条件。
- 基于hashjoin算法实现,如果对R建立hash表,需要标记并重新扫描哈希表,这样可以读取S中的row后,进行匹配,以决定输出哪些行
- 基于nestloop join算法实现,需要R做为外表
(1)Forward-lookup
计算semijoin(R SJp S)或ansijoin(R ASJp S)时,使用R作为外表,基于index-lookup join算法,实现比较容易。我们取关系R的一行,并在关系S的索引中查找它。对于semijoin,如果索引查找得到匹配的行,则输出该行。对于ansijoin,如果索引查找未能找到匹配,则输出该行。
(2)Reverse-lookup
取关系S中的一行,在关系R的索引中进行查找。其余同自上而下方法。 但这种方法在使用中需要非常注意,容易引起结果不一致的问题 。
【一个结果不一致的例子】
- SQL示例 :我们想要找出从ORDERS表中找出紧急订单的数量,这个紧急订单还要满足在1995年1月1日发货但在1994年12月31日提交。查询如下所示:


- 选择率分析 :这是一个ORDERS表和LINEITEM表的semijoin查询(ORDERS sj LINEITEM),指定了发货时间和订单提交时间。LINEITEM和ORDERS都存在谓词条件,但LINEITEM的谓词比ORDERS谓词具有更高的选择率,并且可以使用索引。选择率是 count(distinct column) / count(*),选择率越接近 1 则越适合创建索引,例如主键和唯一键的选择率都是 1。
- 常规方法 :一种常规的方法是,使用索引查找LINEITEM满足谓词的rows,然后再从ORDERS表中,基于O_ORDERKEY索引进行谓词查找。
- 无效原因 : 这种常规方式对semijoin无效 。如果在LINEITEM表中,同一订单(L_ORDERKEY相同)有2个items在1994年12月31日提交订单,在1995年1月1日发货。这是,需要对ORDERS表扫描2次,如果L_ORDERKEY与O_ORDERKEY相同,则对于这个L_ORDERKEY来说,ORDERS表的COUNT(*)返回为2,但真实结果应该为1.
【semijoin Forward-lookup/Reverse-lookup/Set-based】
可以使用前一节 【semijoin 转 outer join 转 inner join】 中方法,将示例中的semijoin转为innerjoin来解决这一问题。
- 理论依据: 对于inner join来说,采用Forward-lookup(R index/nest loopup S)或Reverse-lookup(S index/nest loopup R),结果都是一样的。因此,将semijoin转换为innerjoin后,就可以利用这个性质,获得收益。具体来说,可以自由选择lookup table。
- Forward-lookup: 如果ORDERS表的谓词选择率高,则先读取ORDERS表满足谓词条件的记录,然后再重LINEITEM中查找匹配的记录。
- Reverse-lookup: 如果LINEITEM表的谓词选择率高,则先读取LINEITEM表满足谓词条件的记录,然后再重ORDERS中查找匹配的记录。
- 转换成inner join或outerjoin后,也可以使用set-based join方法,即hash join、merge join
【ansijoin Reverse-lookup】
6.1节已经讨论过了,ansijoin不能转换为join,因此不能执行reverse lookup。
【 ansijoin Forward-lookup 】
更糟糕的是,子查询去关联后产生的asnijoin有时都很难执行forward lookup。原因在于SQL中的NULL。考虑这样一个查询,该查询获取在没有下订单的某一天发货的所有LINEITEMS的数量。 假设我们有一个修改过的TPCH版本,其中未发货的LINEITEM用L_SHIPDATE标识为NULL。
SELECT COUNT(*)
FROM LINEITEM