

深度学习编译器整理

结合知乎帖子,对AI编译器相关提问进行整理。 帖子内容均来自于知乎大佬们,只是按照自己的思路做了梳理。如有遗漏链接,或者错误,烦请指正。
如有侵犯,会删除
知乎大佬: 陈天奇 、 蓝色 、 金雪锋 、 袁进辉 、 杨军 、 高洋 、 Tim Shen 、 郑怜悯 、 Frank Wang 、 opencore 、 HONG 、 陈清扬 、 BBuf 、 x35f 、 工藤福尔摩
一、深度学习编译器背景
早期神经网络部署的侧重点在于框架和算子库,与编译器关系相对较弱。神经网络可以由数据流图表示,图上的节点就是算子,如 Conv2D、BatchNorm,节点之间的连接代表 Tensor。由于数据流图很直观,很多框架的 Runtime 采用了类似 Caffe 的方式,运行时通过一定的顺序分配 Tensor、调用算子库。因此早期优化重点对于框架的修改和算子库的性能。但随着时间的发展这种直观的部署方式也逐渐暴露出一些问题:
- 越来越多的新算子被提出,算子库的开发和维护工作量越来越大;
算子的新增加,不仅需要实现,还需要结合硬件特点优化和测试,尽量做到将硬件的性能压榨到极致。以卷积运算为例,深度学习框架将卷积转换为矩阵乘法,然后在BLAS库中调用GEMM函数。此外,硬件供应商还发布了特别的优化库(例如MKL-DNN和CUDNN)。但是专用硬件,需要提供开发类似的优化库,导致过于依赖库无法有效利用深度学习芯片。
- 由于硬件多样性,重要的工作就是如何将计算有效地映射,能可移植性成为一种刚需;
大多数 NPU 作为一种 ASIC 在神经网络场景对计算、存储和 data movement 做了特殊优化,使得它们对能效比相对 CPU、GPU 要好很多。同时 NPU 的 ISA (Instruction set architecture)千奇百怪,一般也缺乏 GCC 、 LLVM 等工具链,使得已有的针对 CPU 和 GPU 优化的算子库很难短期移植到 NPU 上并充分利用硬件的能力达到较好的性能。
为了应对这些问题,深度学习编译器技术路线一般指在优化过程中采用了自动或者半自动的代码生成用以替代人工优化,近年来这个领域也异常地活跃。
二、深度学习 编译器比较
现阶段的深度学习编译器有
TensorFlow XLA
、
TVM
、
Tensor Comprehension
、
Glow
,以及最近呼声很高的
MLIR
,可以看到不同的公司、社区在这个领域进行着大量的探索和推进。下表是一些DL编译器的对比:
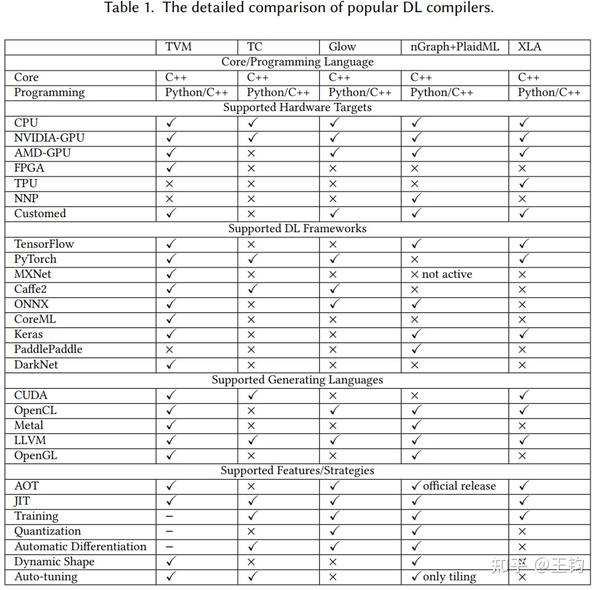

可以看到深度学习编译器的特点主要表现五个方面: (1)核心/编程语言;(2)支持的硬件平台;(3)支持的DL框架;(4)支持的生成语言;(5)支持的功能/策略。
三、深度学习 编译器架构
AI模型结构的快速演化,底层计算硬件的层出不穷,用户使用习惯的推陈出新。单纯基于手工优化来解决AI模型的性能和效率问题越来越容易出现瓶颈,因此,为解决依赖库和工具的缺点,减轻手动优化每个硬件运行模型的负担。通过编译器试图去解决框架的灵活性和性能之间的矛盾。
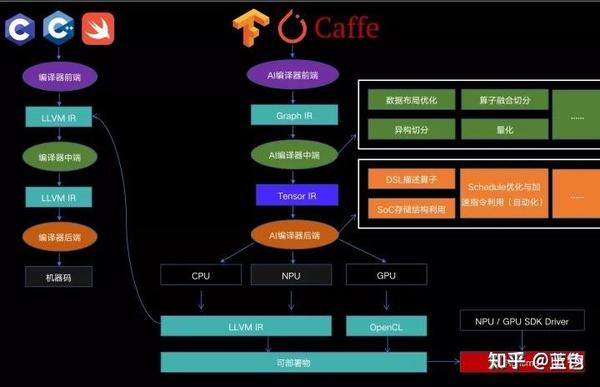

DL编译器主要目的是将深度学习框架描述的模型在各种硬件平台上生成有效的代码实现,其完成的模型定义到特定代码实现的转换将针对模型规范和硬件体系结构高度优化。具体来说,它们结合了面向深度学习的优化,例如层融合和操作符融合,实现高效的代码生成。此外,现有的编译器还采用了来自通用编译器(例如LLVM、OpenCL)的成熟工具链,对各种硬件体系结构提供了更好的可移植性。与传统编译器类似,深度学习编译器也采用分层设计,包括前端、中间表示(IR)和后端。但是,这种编译器的独特之处在于多级IR和特定深度学习模型实现优化的设计。
四、深度学习通用设计
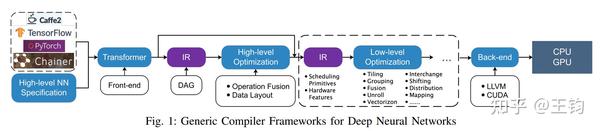
DL编译器的通用设计主要包括两部分:编译器前端和编译器后端,中间表示(IR)分布在前端和后端。通常,IR是程序的抽象,用于程序优化。具体而言,AI模型在DL编译器中转换为多级IR,其中高级别IR位于前端,低级IR位于后端。基于高级IR,编译器前端负责与硬件无关的转换和优化。基于低级IR,编译器后端负责特定硬件的优化、代码生成和编译。
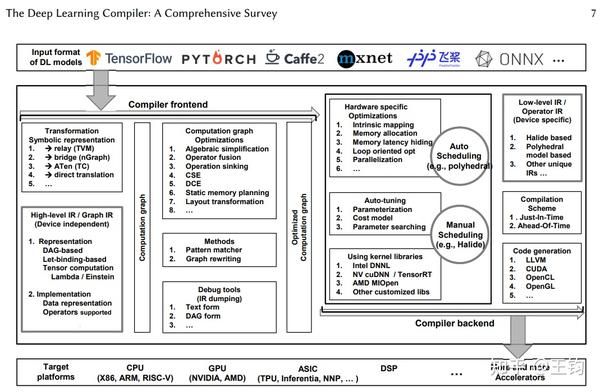

4.1 IR处理
传统编译器里分为前端,优化和后端,其中前端和语言打交道,后端和机器打交道,现代编译器的的前端和后端分的很开,而他们之间的共同桥梁就是IR。IR可以说是一种胶水语言,注重逻辑而去掉了平台相关的各种特性,这样为了支持一种新语言或新硬件都会非常方便。

4.1.1 高级IR
为了克服传统编译器采用的IR限制了AI模型中使用的复杂计算的表达的问题,现有的DL编译器利用图IR和经过特殊设计的数据结构来进行有效的代码优化。
4.1.2 低级IR
相比高级IR,低级IR以更细粒度的表示形式描述了AI模型的计算,该模型通过提供接口来调整计算和内存访问,从而实现了与目标有关的优化。它还允许开发人员在编译器后端使用成熟的第三方工具链,例如Halide和多面体模型。将低级IR可分为三类:基于Halide的IR,基于多面体模型的IR和其他独特的IR。如果感兴趣深度学习框架中的IR处理,可以阅读金雪峰老师的 AI框架中图层IR的分析 。
4.2 前端优化
构造计算图后,前端将应用图级优化。因为图提供了计算的全局概述,所以更容易在图级发现和执行许多优化。这些优化仅适用于计算图,而不适用于后端的实现。因此,它们与硬件无关,这意味着可以将计算图优化应用于各种后端目标。
前端优化分为三类:
1)节点级优化(如零维张量消除、nop消除)
2)块级优化(如代数简化、融合)
3)数据流级优化(如CSE、DCE)。
前端是DL编译器中最重要的组件之一,负责从AI模型到高级IR(即计算图)的转换以及基于高级IR的独立于硬件的优化。尽管在不通过在DL编译器上前端的实现在高级IR的数据表示形式和运算符定义上有所不同,但与硬件无关的优化在节点级别,块级别和数据流级别这三个级别上相似。
4.3 后端优化
4.3.1 特定硬件的优化
在DL编译器的后端,针对硬件的优化(也称为依赖于目标的优化)用于针对特定硬件体系结构获取高性能代码。应用后端优化的一种方法是将低级IR转换为LLVM IR,以便利用LLVM基础结构生成优化的CPU/GPU代码。另一种方法是使用DL域知识设计定制的优化,这可以更有效地利用目标硬件。
4.3.2 自动调整
由于在特定硬件优化中用于参数调整的搜索空间巨大,因此有必要利用自动调整来确定最佳参数设置。 Halide /TVM允许程序员首先定义特定硬件的优化(调度),然后使用自动调节来得出最佳参数设置。这样,Halide/TVM编程人员可以通过反复检查特定参数设置的性能来更新或重新设计规划。另外,自动调整也可以应用多面体模型进行参数调整。
4.3.3 优化的内核库
目前还有几个高度优化的内核库,广泛用于各种硬件上的加速DL训练和推理。当特定的高度优化的原语可以满足计算要求时,使用优化的内核库可显著提高性能,否则可能会受到进一步优化的约束,并且性能较差。
五、深度学习编译器细节优化
传统编译器是以高层语言作为输入,避免用户直接去写机器码。传统编译器比如GCC,Clang的编译范围更广,输入是一段完整的代码,经过了词法分析,语法分析,语义分析,中间代码生成,优化,最后到机器代码。传统编译器面向的程序更加general,前端也比较厚重,都是以编程语言为输入来生成IR。
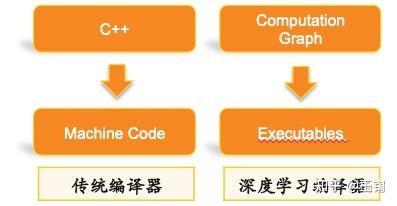
DL编译器的目标是针对计算任务,对应用做了很多很强的假设,而且主要以嵌套循环的计算为主,所以可以针对性的进行优化。让用户可以专注于上层模型开发,降低用户手工优化性能的人力开发成本,进一步压榨硬件性能空间。
DL编译器,针对的都是神经网络模型推理阶段的优化,是从神经网络模型到机器代码的编译。一般过程是 神经网络模型->图优化->中间代码生成(如Halide)->中间代码优化(如TC/Tiramisu使用多面体模型进行变换)->机器代码。DL 编译器的改进主要表现在以下方面:
5.1 性能上的优化(XLA/TVM/TC)
性能上的优化思路其实比较统一,就是打开图和算子的边界,进行重新组合优化。
XLA:
基本上的思路是把图层下发的子图中的算子全部打开成小算子,然后基于这张小算子组成的子图进行编译优化,包括buffer fusion、水平融合等,这里的关键是大算子怎样打开、小算子如何重新融合、新的大的算子(kernel)怎样生成,整体设计主要通过HLO/LLO/LLVM层层lowering实现,所有规则都是手工提前指定。
TVM:
分为Relay和TVM两层,Relay主要关注图层,TVM主要关注算子层,总体思路与XLA是类似的,也是拿到前端给一张子图进行优化,Relay关注算子间的融合、TVM关注新的算子和kernel的生成,区别在于TVM是一个开放的架构,Relay目标是可以接入各种前端,TVM也是一个可以独立使用的算子开发和编译的工具(基于Halide IR,最新演进到自己定义的TIR),TVM在算子实现方面采用了compute和schedule分离的方案,开发人员通过compute来设计计算的逻辑,通过schedule来指定调度优化的逻辑。
TC
(Tensor Comprehensions):开发者发现算子的计算逻辑的开发是比较容易的,但是schedule的开发非常困难,既要了解算法的逻辑又要熟悉硬件的体系架构,更重要的是,前面提到图算边界打开后,小算子融合后,会生成新的算子和kernel,这些新的算子compute是容易确定的(小算子compute的组合),但是schedule却很难生成,所以传统的方法就是事先定义一大堆schedule模板,万一组合的新算子不在模板之内,性能就可能比较差,甚至出错;那TC则希望通过Polyhedra model实现auto schedule,降低开发门槛,当然这个项目基本已经停更了,但是类似的工作在MLIR、MindSpore上还在不停发展。
5.2 图层和算子层的IR表达
优化本身是一个无止境的工作,也是考验技术功底和能力的工作。由于本文内容偏向概念性质的内容,这里暂时不做过多的说明, 建议阅读相关书籍 ,进行体系化的学习。
- 风辰 大佬的《并行算法设计与性能优化》
- 《计算机体系结构:量化研究方法》,讲解请点击 视频链接
- 《计算机组成与设计:硬件/软件接口》
- 《Hacker's Delight2》,中文版《算法心得-高效算法的奥秘》,如是有疑问,可以 再此issue上提问
六、深度学习编译器 区别
(1)优化的目的
传统编译器注重于优化寄存器使用和指令集匹配,其优化往往偏向于局部。而深度学习编译器的优化往往需要涉及到全局的改写,包括之前提到的内存,算子融合等。目前深度学习框架的图优化或者高层优化(HLO)部分和传统编译的pass比较匹配,这些优化也会逐渐被标准的pass所替代。但是在高层还会有开放的问题,即高层的抽象如何可以做到容易分析又有足够的表达能力。TVM的Relay,XLA和Glow是三个在这个方向上的例子。
(2)优化的需求
在自动代码生成上,传统编译器的目标是生成比较优化的通用代码。而深度学习编译器的目标是生成接近手写或者更加高效的特定代码,如:卷积,矩阵乘法等。相对的,在一些情况下深度学习编译器可以花费更多的时间,去寻找这些解决方案。
七、深度学习编译器优势
深度学习编译器和传统编译器的一大区别是出了编译器之外还有很多周边的架构用于支持编译和部署。这些架构包括快速的远程部署,不同前端的转化,灵活的运行时设计等。能否有比较好的周边架构也是会决定深度学习编译器易用性的关键。
目前虽初具雏形,但仍然可以看到非常多的提升空间。在更多backend硬件支持,Fusion/CodeGen性能,Buffer管理优化,稀疏化算子支持,运行时调度优化等等诸多环节还存在很大提升空间。
涉及DL编译器公司
知乎里给的链接比较旧,仅供参考, 具体还要根据实际经济市场决定。
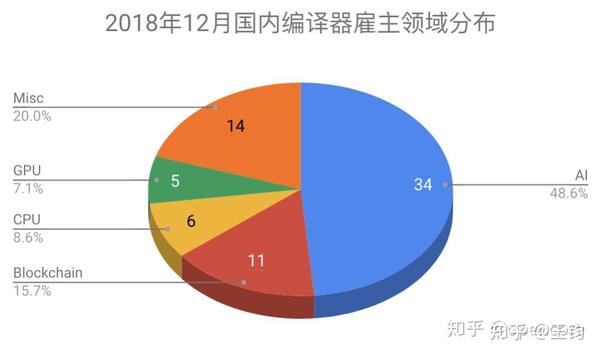
7.1 分布领域

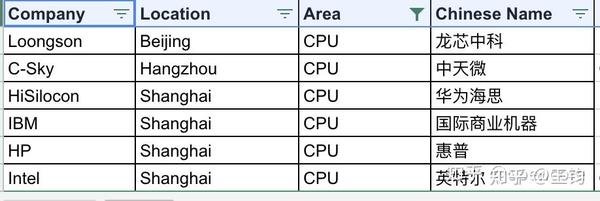
7.2 CPU

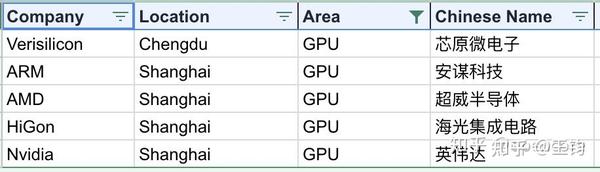
7.3 GPU
现阶段GPU中创业公司较多,具体根据招聘网站浏览统计。

7.5 AI
现在阶段AI方面的公司较多,根据招聘网站检索
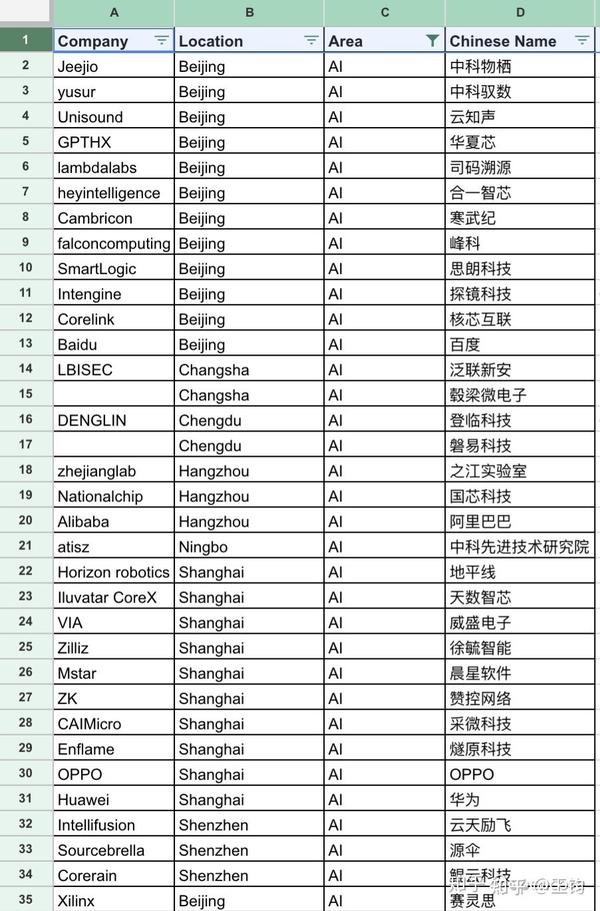

2021年名单


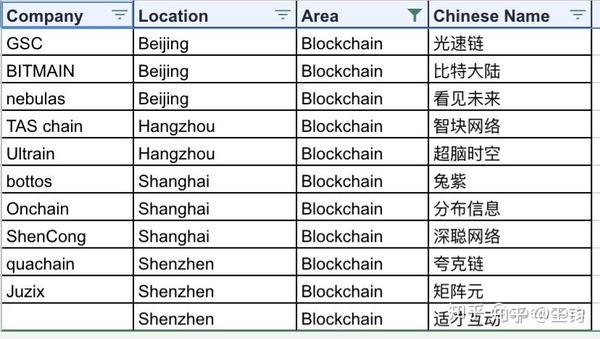
7.7 区块链

八、 资源
8.1 刷题网站
流水线处理器题库 ,现在CSDN会员才能看:
编译器设计面试问答:
https://www. wisdomjobs.com/e-univer sity/compiler-design-interview-questions.html
编译器问答: 1000 多个编译器 MCQ(多项选择题和答案)专注于编译器的所有领域,涵盖 100 多个主题。
1000 Compiler MCQs - Sanfoundry
编译器设计问题:
Engineering Interview Questions.com
代码生成和优化:
Code Generation and Optimization - GeeksforGeeks
Computer Science:
Quiz Listing - Online Test - Avatto
8.2 B站视频
北京邮电大学 黄雍陶 TVM讲解视频
视频链接: Yongtao_Huang的个人空间_哔哩哔哩_Bilibili
华盛顿大学 TVM视频
视频链接:
【TVM】TVM Conference 2018 Program_哔哩哔哩_bilibili
8.3 GitHub资源

郑怜悯老师整理
merrymercy/awesome-tensor-compilers
Wang Zheng老师整理
zwang4/awesome-machine-learning-in-compilers
AI芯片相关论文
参考链接
[1] T he Deep Learning Compiler: A Comprehensive Survey
[2] An In-depth Comparison of Compilers for Deep Neural Networks on Hardware
[3] MLIR: A Compiler Infrastructure for the End of Moore's Law --涉及MLIR所有的设计idea
[4] TVM: An Automated End-to-End Optimizing Compiler for Deep Learning
[5] TASO: Optimizing Deep Learning Computation with Automatic Generation of Graph Substitutions --深度学习框架可以通过对计算图进行等价变换来减少运算时间。本文想自动寻找在特定体系结构&特定框架上,最优的等价变换
[6] Tvm. https:// tvm.apache.org/
[7] XLA. https://www. tensorflow.org/xla
[9]TensorComprehensions. https:// github.com/facebookrese arch/TensorComprehensions
[9] Polyhedral Compilation. https:// polyhedral.info . Accessed February 4, 2020.
[10] MindSpore. https:// gitee.com/mindspore/min dspore
[11] AI编译优化--总纲
[12] AI编译优化--Dynamic Shape Compiler
[13]
针对神经网络的编译器和传统编译器的区别和联系是什么
[14]
金雪锋:AI框架中图层IR的分析
[15] 深度学习编译技术的现状和未来
[16] 有哪些编译器刷题网站?
[17] opencore:2018年12月国内编译器雇主汇总
[18] 一文吃透AI芯片技术路线,清华尹首一教授演讲全文:GTIC2020
[19] Deep Learning Compiler 之自我理解
[20] 为什么现在的芯片公司都在急需做编译器的人