


python爬虫之爬虫第一步:获取网页源代码

在笔者爬取了上百个网站总结发现爬虫其实就2项工作:1.获取网页源代码;2.解析网页源代码提取所需内容,如果要给这两项工作分配一个权重,在笔者这里权重为7:3。为什么这第一项工作尤为重要呢,因为获取网页源代码是一切爬虫的核心,若能够获取到网页源代码,那么这项爬虫项目其实就基本算完成了,因为有了源代码之后,有很多种方法可以解析出所需的内容。
如何进行解析网页源代码将在下一章进行讲解,这一章主要来讲解下爬虫的第一步也是最重要的一步:如何获取网页源代码,获取网页源代码有2个核心库:requests库和selenium库,这两个库能够获取95%的网站源代码,剩下5%的网站可能存在IP反爬、验证码反爬等限制,这些内容我们放到第8章之后进行讲解。
本章内容和笔者编写的《Python金融大数据挖掘与分析全流程详解》部分内容有重复,不过由于是爬虫的核心内容必须得讲一下,已经熟悉本章内容的读者可以跳过本章节阅读下一章。
1、爬虫核心库1:requests库
学习爬虫其实并不太需要了解太多的网页结构知识,作为初学者只需要知道1点:所有想要获取的内容(例如新闻标题/网址/日期/来源等)都在网页源代码里,所谓网页源代码,就是网页背后的编程代码,这一小节我们首先来讲解下如何查看网页源代码,以及通过两个案例快速体验下如何通过requests库获取网页源代码。
1.1 如何查看网页源代码
在进入正式爬虫实战前,我们首先来了解下如何查看网页源代码。
网络爬虫首先得有一个浏览器,这里强烈推荐谷歌浏览器(百度搜索谷歌浏览器,然后在官网 https://www. google.cn/chrome/ 下载,谷歌浏览器默认是谷歌搜索,直接在网址输入框里输入内容可能搜索不到内容,可以在网址栏上输入baidu.com进行访问,或者可以点击浏览器右侧的设置按钮->选择界面左侧的搜索引擎->选择百度搜索引擎)。当然用别的浏览器,比如火狐浏览器等都是可以的,只要它按F12(有的电脑要同时按住左下角的Fn键)能弹出网页源代码即可。
以谷歌浏览器为例来演示下F12的强大作用,百度搜索“阿里巴巴”,然后 按一下F12(有的电脑还得同时按住Fn) ,弹出如下页面,其中点击右侧设置按钮可以切换布局样式。
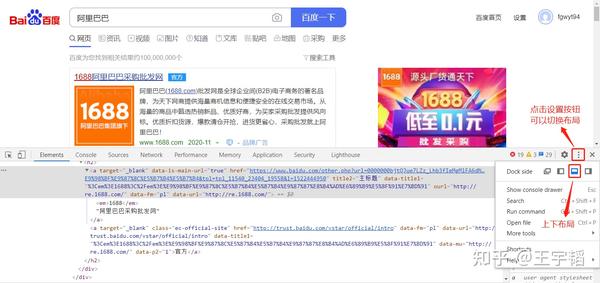
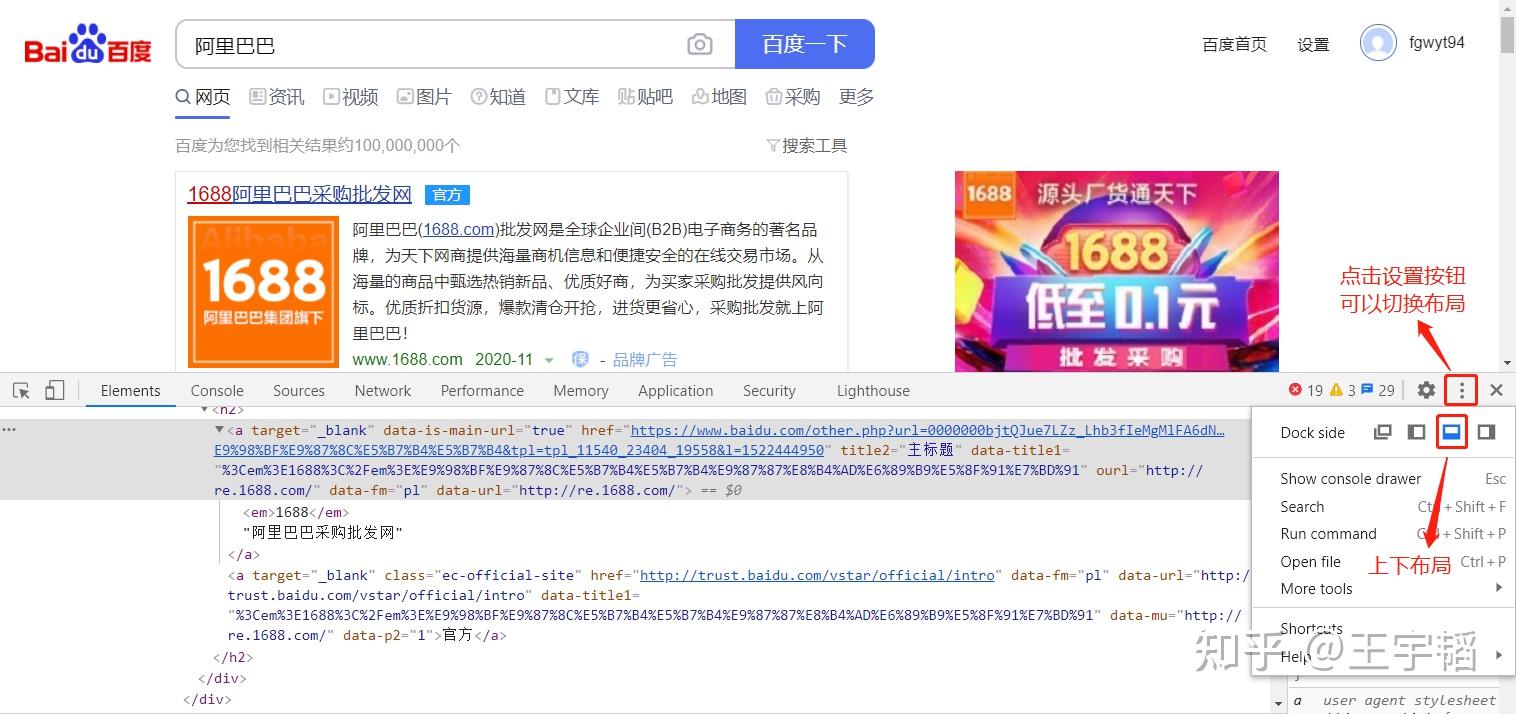
这个按住F12弹出来的东西叫做开发者工具,是进行数据挖掘的利器,对于爬虫来说,大多数情况下只需要会用下图的这两个按钮即可。


第一个按钮箭头形状按钮为 选择 按钮,第二个Elements按钮为 元素 按钮。
(1) 选择按钮

:
点击一下它,发现它会变成蓝色,然后把鼠标在页面上移动移动,会发现页面上的颜色机会发生改变。如下图所示,当 移动鼠标 的时候,会发现界面上的颜色会发生变化,并且Elements里的内容就会随之发生变化。
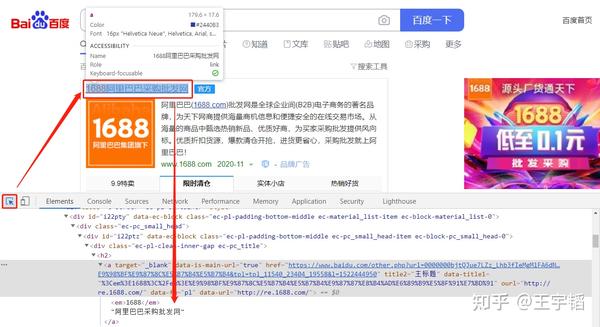
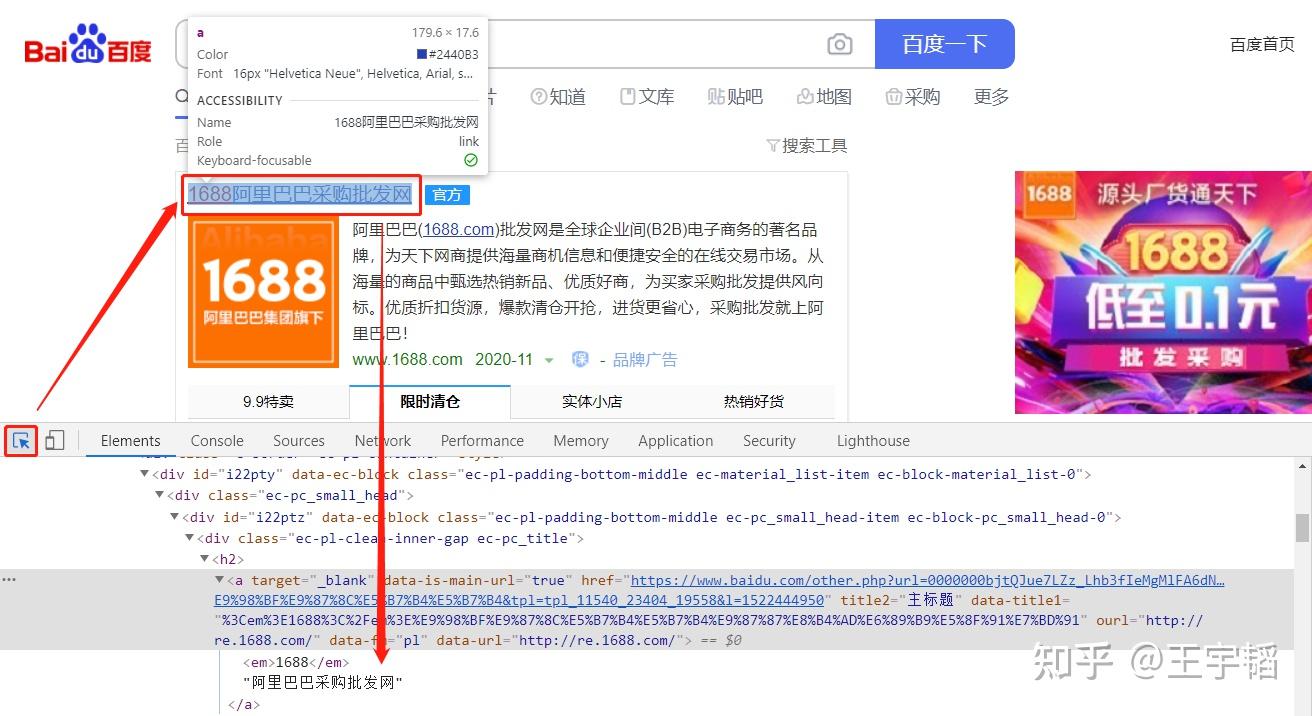
下面当选择按钮处于蓝色状态的时,点击一下第一个链接的标题,这时候选择按钮再次变成灰色,而Elements里的内容也将不再变动,此时便可以观察具体的网页源代码内容了,如下图所示,我们一般只关心里面的所需要的中文内容,如果没有看到中文文本,店家下图所示的三角箭头,即可展开内容,看到中文文本。


(2) Elements元素按钮 :
Elements元素按钮里面的内容可以理解为 就是网站的源码 ,最后爬虫爬到的内容大致就是长这个样子的。下面就要接着完成一些“神奇”的操作。
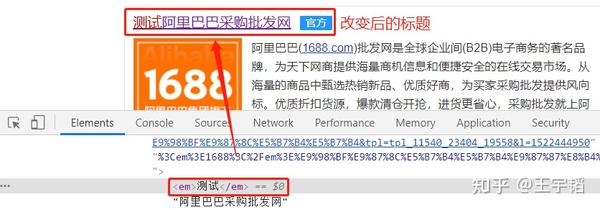
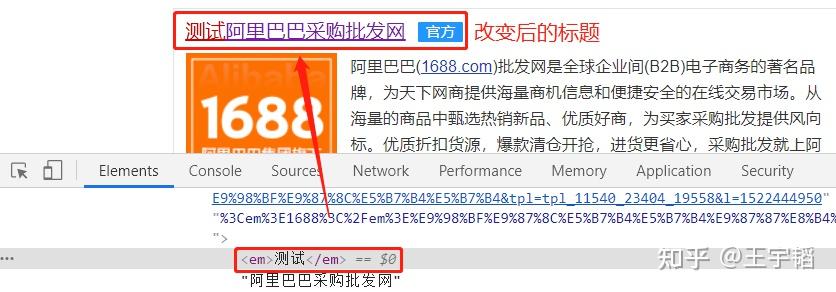
在下图“ 1688” 那个地方鼠标双击俩下,这两个字变成可编辑的格式。


将其改成“测试”,可以看到第一个的标题发生了改变,如下图所示:
还可以用同样的操作,修改页面上的其他信息,如股价等。
还可以用同样的操作,先选择 选择 按钮,点击下面的阿里股价:
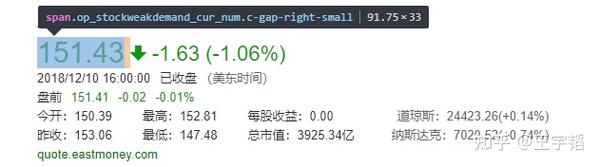

用同样的方法可以在Elements里将这个数字改成所想改的数据,如下图所示:


通过F12启动开发者工具,我们可以对网页结构有一个初步的认识,并可以利用选择按钮和“Elements”元素按钮观察我们想获取的内容在源码中的文本格式以及所在位置。
补充知识点1:查看网页源码的另一个方式
除了F12,另一个获取网页源码的方式是在网页上右击选择“ 查看网页源代码 ”,就可以获取这个网址的源代码,这个基本就是Python爬取到的最终信息。用鼠标上下滚动,就能看到很多内容,同样初学者不需要关心那些英文或者网页框架,只需要知道想获取的中文在哪里即可。
这个方法比F12观察源码的方式更加真实,因为F12观察到的源码可能是被网页修饰过的,通过Python获取到内容可能和F12看到的不一致。通过该方法查看到的源码就是通过Python程序能够获取到的网页源代码。实战中常将两种方法联合使用:通过F12进行初步了解,然后右击查看网页源代码,看看所需内容到底在网页源代码的什么位置,其中可以通过Ctrl + F快捷键搜索所需要的内容。
此外,如果F12看到的内容和通过右击查看网页源代码看到的内容很不一样,这是因为网站做了动态渲染的处理(这是一种反爬处理),这时候就需要用到2.2节selenium库的相关知识点来获取真正的网页源代码。
补充知识点2:http与https协议
有的时候我们理解的网址是: http://www. baidu.com ,但其实在编程里或者它真实的名字其实是: https://www. baidu.com ,它前面有个“https://”这个叫做https协议,是网址的固定构成形式,某种程度表明这个网址是安全的,有的网址前面则为http://。如果在Python里输入 www.baidu.com 它是不认识的,得把“https://”加上才行,如下面所示。
url = 'https://www.baidu.com/'其实最简单的办法, 就是直接浏览器访问该网址,然后把链接复制下来就行 。
补充知识点3:网址构成及网址简化
有的时候我们在浏览器上看到的网址非常长,例如在百度上搜索“阿里巴巴”,在网页上显示的网址如下所示:


如果复制这样一长串的网址会让代码非常臃肿(虽然这样并不影响代码运行结果),那有没有办法简化网址呢?答案是有的,可以看到在网址中有一个问号“?”,问号后面跟了很多内容,这些内容通过“&”符合连接,这些通过“&”符号连接的内容叫作网址的参数,而网址中的很多参数都不是必须的,如何判断是否必须,可以将“&”及其连接的内容删掉,看看网页是否还可以访问,如果还可以访问,则说明该参数不是必须的,可以删去该参数以简化网址。
例如通过尝试,如下图所示,上面的网址就可以简化成如下内容: https://www.baidu.com/s?wd= 阿里巴巴(其实wd参数就是word参数的缩写)。


补充知识点4:如何解决“复制网址后中文变成了英文和数字”的问题
在上一补充知识点中,我们将网址进行了简化,但是当我们将网址从浏览器中Ctrl + C复制下来再粘贴时,发现网址变成了如下内容: https://www. baidu.com/s? wd=%E9%98%BF%E9%87%8C%E5%B7%B4%E5%B7%B4 ,原来中文的阿里巴巴,变成了一堆字母数字加百分号的内容,这是怎么回事呢?这是因为浏览器是国外发明的,中文需要转换下才可以识别,这一堆英文和数字可以理解为浏览器的“翻译语言”。对于爬虫实战而言,无需对其研究太深,可以直接将其换成中文即可: https://www.baidu.com/s?wd= 阿里巴巴。
1.2 爬虫初尝试 - requests库获取百度新闻源代码
了解了如何查看网页源代码后,这一小节我们讲解下如何通过requests库爬取百度新闻的网页源代码。百度新闻目前改版为“资讯”版块,如下图所示,直接在“资讯”里便可搜索相关新闻。
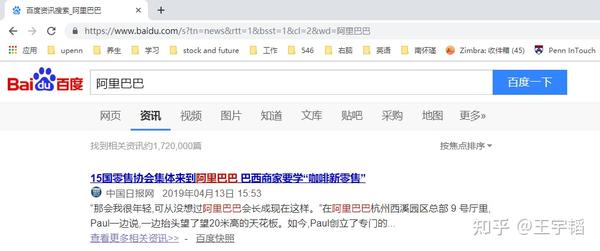
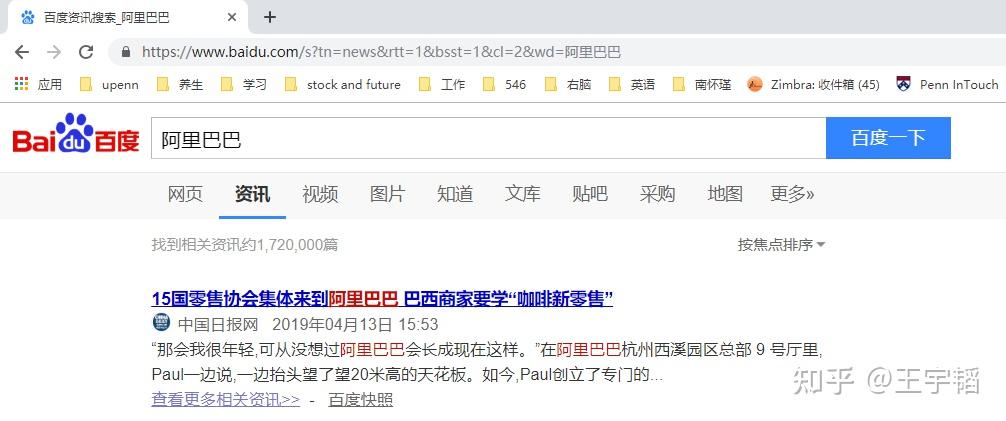
其网址为 https://www.baidu.com/s?rtt=1&bsst=1&cl=2&tn=news&word=阿里巴巴 。在上一节的补充知识点中也讲过,如果直接从网址上进行复制的话,阿里巴巴四个中文会显示成 %E9%98%BF%E9%87%8C%E5%B7%B4%E5%B7%B4 这样的字母数字加百分号的内容,处理方法是直接将其换成“阿里巴巴”中文即可;此外,网址中的一些参数是可以删掉的,例如将网址中的“&bsst=1”以及“&cl=2”这2个参数删除掉也并不会影响网站的访问, 精简后的网址为 : https://www.baidu.com/s?rtt=1&tn=news&word=阿里巴巴 。
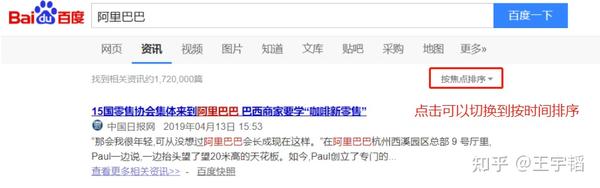
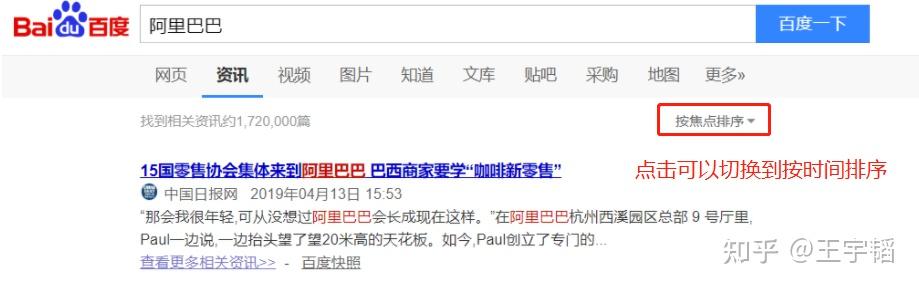
这里再补充介绍下,百度新闻默认是按焦点排序,如果点击上图中的“按焦点排序”可以选择切换到“按时间排序”,会发现此时网址变为: https://www.baidu.com/s?rtt=4&tn=news&word=阿里巴巴 (该网址已经进行了精简,其主要改变的参数就是rtt参数,由1变成了4),本书之后主要以按时间排序的网址来进行演示,感兴趣的读者也可以使用默认的按焦点排序的网址。
(1) 获取网页源代码
通过第一章最后介绍的requests库来尝试获取下百度新闻的网页源代码,代码如下:
import requests
url = 'https://www.baidu.com/s?rtt=4&tn=news&word=阿里巴巴'
res = requests.get(url).text
print(res)获取到的源代码如下图所示:
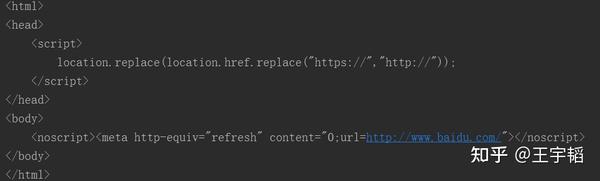
可以看到其并没有获取到真正的网页源代码,这是因为这里的百度资讯网站只认可浏览器发送过去的访问,而不认可直接通过Python发送过去的访问请求,那么该如何解决该问题呢?这时就需要设置下requests.get()中的headers参数,用来模拟浏览器进行访问。
Headers参数记录的其实就是网站访问者的信息,headers中的User-agent(中文叫作用户代理)就是反映是用什么浏览器登录的,其设置方式如下所示,User-agent的获取稍后会讲。
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36'}设置完headers之后,在通过requests.get()请求的时候需要加上headers信息,这样就能模拟是通过一个浏览器在访问网站了,代码如下:
res = requests.get(url, headers=headers).text完整代码如下所示:
import requests
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36'}
url = 'https://www.baidu.com/s?rtt=4&tn=news&word=阿里巴巴'
res = requests.get(url, headers=headers).text
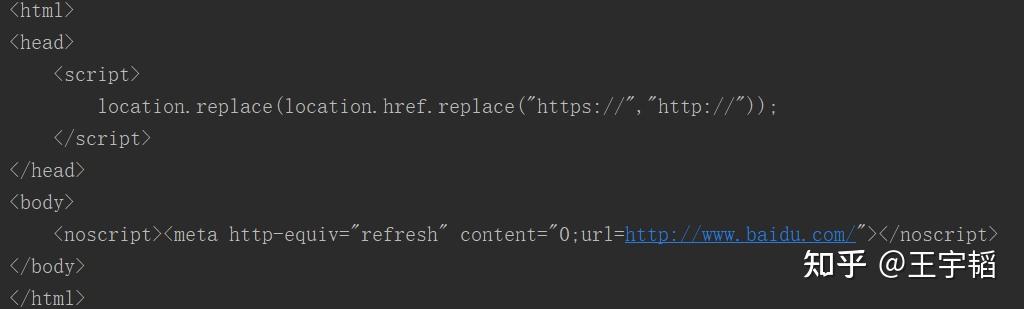
print(res)运行结果如下图所示,可以发现此时已经获取到网页的源代码了。
这里的headers是一个字典,它的键名为:'User-Agent',它的值为:'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36',User-Agent其实就是代表这个访问的浏览器是哪家的浏览器。
上面代码用的便是谷歌(Chrome)浏览器的User-Agent,这里以谷歌浏览器为例讲解下如何获取浏览器的User-Agent。首先打开谷歌浏览器在搜索框输入:about:version(注意是英文格式的冒号),然后在弹出的界面中找到用户代理,它就是User-Agent的中文翻译,不同版本谷歌浏览器的用户代理的内容会在版本号上有些差别(例如这里是86版本),但是都可以使用。


对于实战,只要记得在代码的最前面,写上如下代码:
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36'}然后每次用requests.get访问的时候,加上headers = headers即可。
res = requests.get(url, headers=headers).text有时不加headers也能获得网页的源代码,比如第一章最后通过requests库爬取Python官网就不需要加headers。不过headers只要在开头设置一次,之后直接在requests.get()中添加headers=headers即可,所以并不麻烦,而且可以避免可能会出现的爬取失败。
这里可以看到通过短短4、5行代码,我们就能够获得网页的源代码了,而这个可以说是网络数据挖掘中最重要的一步了,之后所需要做的工具就是信息提取和分析了,这个我们将在下一章进行讲解。
(2)分析网页源代码信息
获取到网页源代码后,我们想提炼其中的新闻标题、网址、日期和来源等信息。在提炼这些信息之前,我们有三种常见的分析方法来观察这些信息的特征。
(a) 方法1:F12方法
点击 选择按钮 ,选择一个标题,可以在 Elements 中看到,我们所需要的标题内容就在这一片内容中,用同样的的方法可以查看新闻日期和来源等信息。
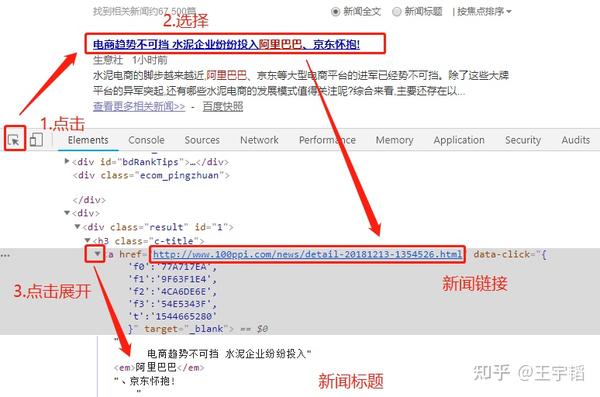

如果看不到其中的中文信息,那是因为它被折叠了,点击折叠箭头展开折叠就可以看到中文了。不过有时通过F12看到的源代码并不一定准确,所以也常常和下面两种方法一起使用。
(b) 方法2:右击选择“查看网页源代码”
和之前提到过的一样,我们在浏览器上右击,选择“查看网页源代码”,到了源代码网页的时候,可能得 往下滚动一下滚轮才能看到内容 ,然后便可以通过 Ctrl + F 快捷键(快速搜索快捷键)定位关心的内容了。
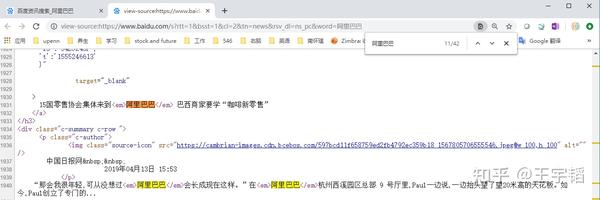

(c) 方法3:在Python获得的网页源代码中查看
在获取到源代码的输出框内通过Ctrl + F组合键,调出搜索框,搜索所关心的信息,这种方法也比较常见,不过需要先通过程序获得网页源代码信息。
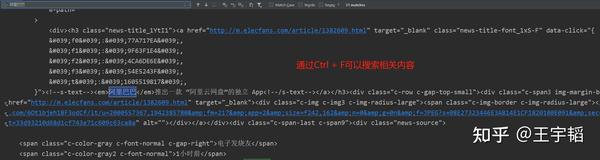
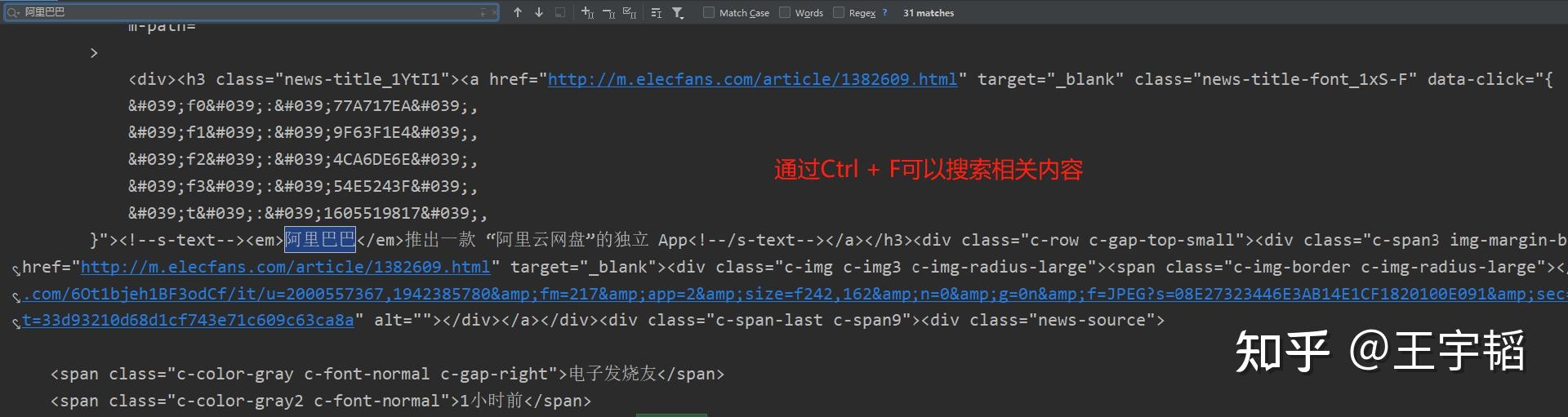
在源代码里可以看到,关于新闻的标题,来源日期以及正文其实都已经有了,只不过被一些英文、空格以及换行包围着,需要通过一个手段将这些信息提取出来。一个常见的提取信息的手段就是通过正则表达式来进行提取,将在下一章进行详细讲解。
此外,虽然有多种查看网页源代码的方式,但是如果3者出现了不一致,以Python获取到的网页源代码为准(因为下一章的Python数据提取是基于Python获取到的网页源代码),如果Python获取到的内容没有包含所需的信息,那大概率是网站做了动态渲染或其他一些反爬处理,用requests库就不太够了,此时就需要利用下一节即将讲到的Selenium库。
2 爬虫核心库2:selenium库
Selenium库这一知识点相对比较重要,如果说requests库能够爬取50%的网站的话,那么通过selenium库的话可以爬取95%的网站,大部分较为困难的网址都可以通过其来获取网页源代码。下面我们首先来分析下requests库在一些复杂爬虫中遇到的难点,然后讲解下如何安装selenium库以及如何通过selenium库获取到网页源代码。
2.1 requests库遇到的难点
在使用requests库进行爬虫实战时,有时会遇到一大难题:获取不了网页真正的源代码。例如,上海证券交易所的公开信息、新浪财经的股票行情实时数据等,用常规爬虫手段会发现获取到的网页源代码内容很少且没有用。因为这些网页上展示的信息是动态渲染出来的,而通过常规爬虫手段获取的则是未经渲染的信息,所以其中没有我们想要的信息。
以新浪财经的上证综合指数(上证综合指数反映在上海证券交易所全部上市股票价格综合情况)网页( http://finance.sina.com.cn/realstock/company/sh000001/nc.shtml )为例,在浏览器中按F12 键,可以在网页源代码中看到指数数值,如下图所示。
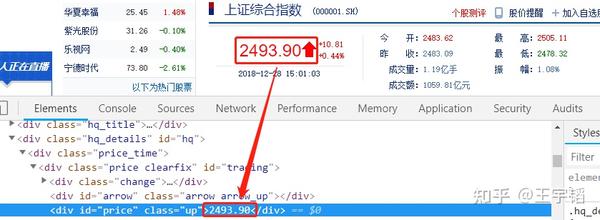
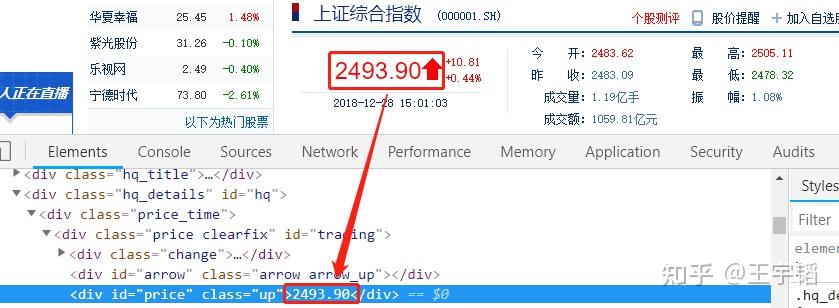
然后用常规爬虫手段,以requests.get(url).text 的方式获取这个网页的源代码,然后按快捷键Ctrl+F,在源代码中搜索刚才看到的指数数值,会发现搜索不到,如下图所示。而且就算加上headers 参数也没有改观。
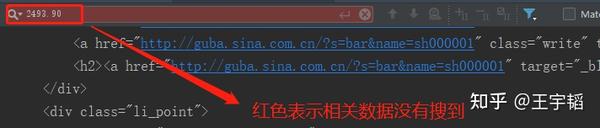

通过F12 键可以看到的内容,为什么用Python 却爬取不到呢?这是因为通过F12 键看到的其实是网站动态渲染后的内容,它能够被常规手段爬取的信息很有限。一个快速验证的办法就是在网页上右击,然后选择“查看网页源代码”命令,所看到的网页源代码内容很少,也没有显示通过F12 键能看到的信息,如下图所示。此时就可以判定通过F12 键看到的网页源代码是动态渲染后的结果。
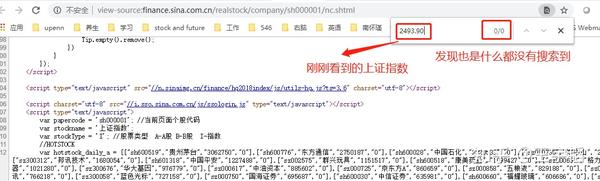

面对这种动态渲染的网页,在数据挖掘时就需要使用Selenium 库,通过模拟打开一个浏览器访问网址,然后获取渲染后的网页源代码,从而完成requests库难以完成的任务。
读到这里,有的读者可能会有疑问,既然requests库获取到的内容通过selenium库可以获取,requests库获取不到的内容也可以通过selenium库获取到,那么为什么还要讲解selenium库呢?这是因为requests库是直接进行网页请求,访问速度非常快,而selenium因为要模拟打开浏览器再访问网址,会使得爬取速度较慢。
| 优点 | 缺点 | |
| requests库 | 爬取速度快 | 有些网站爬取不到 |
| selenium库 | 能爬取95%以上的网站 | 爬取速度较慢 |
简单来说,如果网页能通过requests库获取到网页源代码,那么推荐使用requests库进行爬取从而使得爬取速度较快,如果requests库获取不到网页源代码,再通过selenium库进行爬取。
2.2 一力降十会!- Selenium库介绍与安装
正式介绍selenium库之前,得首先先安装一个网页模拟器:ChromeDriver,它的作用是给Pyhton提供一个模拟浏览器,让Python能够运行一个模拟的浏览器进行网页访问,并用selenium进行鼠标及键盘等操作获取到网页真正的源代码。
(1) 安装Chrome谷歌浏览器
安装ChromeDriver之前,得先装一下Chrome谷歌浏览器,直接百度搜索谷歌浏览器,然后在官网 https://www. google.cn/chrome/ 下载即可。
(2) 查看Chrome浏览器版本
先来查看下自己Chrome浏览器的版本,这个之后安装ChromeDriver的时候有用,点击谷歌浏览器右上角的菜单栏,选择帮助,选择关于Google Chrome。

在弹出的页面里就可以查看自己安装的Chrome版本号了。
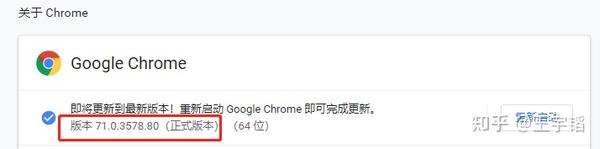

通过输入about:version也可以查看。
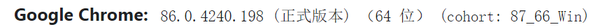

(3) ChromeDriver下载
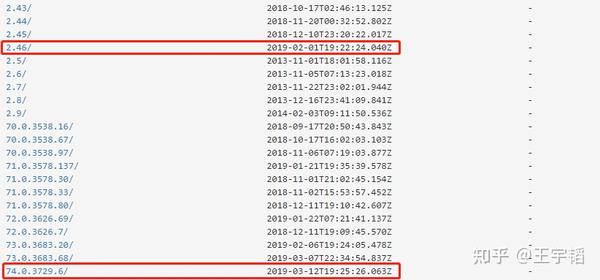
ChromeDriver官方下载地址: https:// sites.google.com/a/chro mium.org/chromedriver/downloads 。进入官网后,选择适合自己谷歌浏览器版本的ChromeDriver下载即可。不过由于官网再国内经常访问不了,因此可以在百度上搜索“ChromeDriver下载”,可以找到如下一个镜像下载网站: http:// npm.taobao.org/mirrors/ chromedriver/ 。

这个是一个镜像网站,里面提供下载链接就是为了防止出现访问不了官网的问题。不过利用这个镜像网站进行下载的时候有个小缺点就是它没有标明适合的谷歌浏览器版本号,所以如果不放心下载哪一个,可以下载最新版本的谷歌浏览器,然后如下图所示选择最近更新的chromedriver文件进行下载,通常来说,这个下载下来是一个压缩文件,大小为4-7M左右,如果文件大小过小,那可能是点错下载链接了。

(4) ChromeDriver环境变量配置
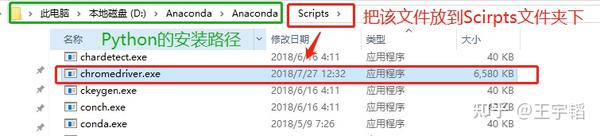
ChromeDriver下载完之后,还需要把ChromeDriver配置到环境变量中,其目的是为了让Pyhton能够更加容易的调用ChromeDriver。以Windows系统为例:将下载好的chromedriver_win32.zip解压得到一个exe文件,将其复制到Python安装目录下的 Scripts 文件夹,如下图所示。(如果是mac系统,则是将chromedriver移至/usr/bin目录下。)

如果忘了自己Python的安装路径,可以按如下方法进行查找。
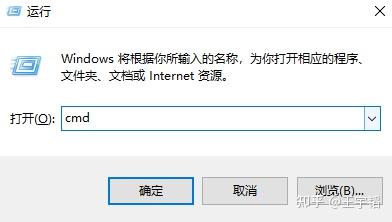
第一步:Win + R调出运行框,输入cmd:
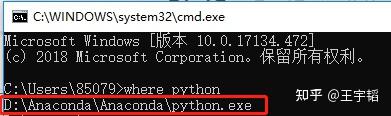
第二步:在弹出框内输入where python就可以找到Python的安装路径了:
然后在此安装目录,比如这边叫作D:\Anaconda\Anaconda下找到Scripts文件夹,把下载并解压好的chromedriver.exe文件放进去即可。
我们还可以在这个弹出框验证ChromeDriver是否安装成功,当把上面的步骤都做完之后,Win+R组合键调出运行框,输入cmd,在弹出控制台输入chromedriver,如果出现如下类似界面,就说明安装成功了。
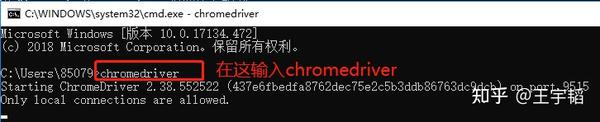

此外,注意有时候Chrome谷歌浏览器会自动更新,会导致更新后的浏览器和chromedriver版本不匹配,因此需要重新下载并配置相应版本的chromedriver。例如下图报错就是版本不一致。


(5) Selenium库的安装
ChromeDriver安装完成后就可以进行selenium库的安装了,这里推荐pip安装法,具体步骤如下:第一步:通过Win + R组合键,调出运行框,输入cmd;第二步:在弹出对话框里,输入 pip install selenium ,按一下Enter回车键,等待安装结束即可。也可以参考之前Pycharm安装库的方法在Pycharm里进行安装。
如果直接pip安装失败,也可以通过下面代码使用清华镜像源进行安装。
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple selenium安装完成之后,先来试着运行如下代码看看:
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.baidu.com/')如下图所示,发现通过Python模拟打开了一个浏览器,并自动访问了百度首页了。
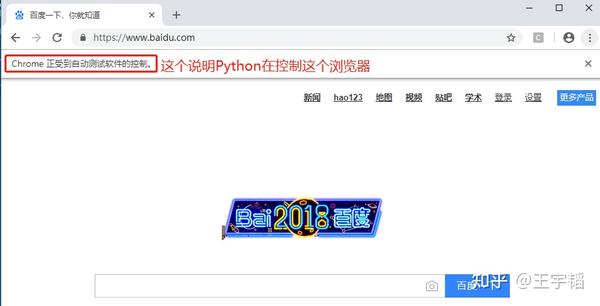
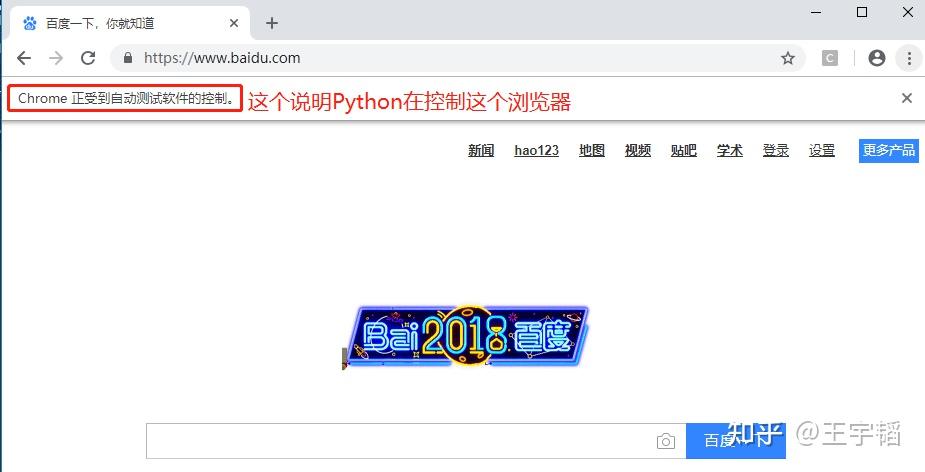
若没做好chromedriver的环境变量配置,则需通过executable_path参数注明chromedriver的文件安装路径,如下所示(其中r用来取消文件路径中“\”可能存在的特殊含义):
browser = webdriver.Chrome(executable_path=r'C:\Users\chromedriver.exe')2.3 Selenium库获取网页源代码 - 新浪财经股票信息
Selenium库的功能很强大,使用技巧却并不复杂,只要掌握了下面的几个知识点,就能较游刃有余的使用selenium库了。
(1) 访问及关闭页面 + 网页最大化
通过以下这三行代码,就可以访问网站了,它相当于模拟人打开了一个浏览器,然后输入了一串网址:
from selenium import webdriver