|
|
|


1. 背景
一个作业(Job)由一组任务(Task)及其依赖关系组成,每个任务可以有一个或多个执行实例(Instance)。具体详情看 名词解释 。目前的任务类型分为两种:并发任务和 DAG(Directed Acyclic Graph) 任务。
2. 任务概述
2.1 并发任务
作业中的一个任务可以指定在多个实例上运行程序,这些实例运行的任务程序都是一样的,但是可以处理不同的数据。
2.2 DAG任务
作业中的多个任务之间可以有 DAG 依赖关系。即前面的任务运行完成后, 后面的任务才开始运行。
3. 任务实现
这两种任务是在提交的 Job 中指定相关字段实现的,下面以 Python SDK 为例给出实现方式,代码的完整程序见快速开始。
3.1 并发任务实现
在提交的 Job 中,填写 InstanceCount 字段。指明任务需要的实例数。该字段就是实现任务的并发功能。
from batchcompute.resources import (
JobDescription, TaskDescription, DAG
# create my_task
my_task = TaskDescription()
my_task.InstanceCount = 3 #指定需要实例数:3台VM如果并发任务需要处理不同片段的数据,这个时候在需要运行的任务程序中 使用环境变量 :BATCH_COMPUTE_DAG_INSTANCE_ID(实例 ID)来区分,就可以处理不同片段的数据。下面的示例程序是快速开始的count代码,假设输入数据已经放在OSS中。您需要下载OSS的 sdk 。
import oss2 #oss sdk
from conf import conf
import os
import json
endpoint = os.environ.get('BATCH_COMPUTE_OSS_HOST') #OSS Host
auth = oss2.Auth(conf['access_key_id'], conf['access_key_secret'])
def download_file(oss_path, filename):
(bucket, key) = parse_oss_path(oss_path)
bucket_tool = oss2.Bucket(auth, endpoint, bucket)
bucket_tool.get_object_to_file(key, filename)
def upload_file(filename, oss_path):
(bucket, key) = parse_oss_path(oss_path)
bucket_tool = oss2.Bucket(auth, endpoint, bucket)
bucket_tool.put_object_from_file(key,filename)
def put_data(data, oss_path):
(bucket, key) = parse_oss_path(oss_path)
bucket_tool = oss2.Bucket(auth, endpoint, bucket)
bucket_tool.put_object(key, data)
def parse_oss_path(oss_path):
s = oss_path[len('oss://'):]
[bucket, key] = s.split('/',1)
return (bucket,key)
def main():
# instance_id: should be start from 0
instance_id = os.environ['BATCH_COMPUTE_DAG_INSTANCE_ID']
data_path = conf['data_path']
split_results = 'split_results'
filename = 'part_%s.txt' % instance_id
pre = data_path[0: data_path.rfind('/')]
print('download form: %s/%s/' % (pre, split_results))
# 1. download a part
download_file('%s/%s/%s.txt' % (pre, split_results, instance_id ), filename)
# 2. parse, calculate
with open(filename) as f:
txt = f.read()
m = {
'INFO': 0,
'WARN': 0,
'ERROR': 0,
'DEBUG': 0
for k in m:
m[k] = len(re.findall(k, txt))
print(m)
# 3. upload result to oss
upload_to = '%s/count_results/%s.json' % (pre, instance_id )
print('upload to %s' % upload_to)
put_data(json.dumps(m), upload_to)3.2 DAG任务实现
在提交的job中,填写 Dependencies 字段。指明任务之间的依赖关系。下面的图中,首先理清各个任务之间的依赖关系,count1 和 count2 是并行的任务,它们依赖 split 任务,merge任务依赖 count1 和 count2。
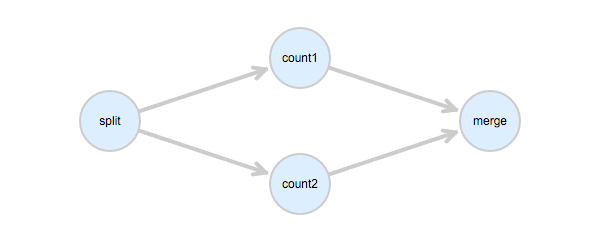
依据上面的依赖关系,在Job中可以这样描述:
from batchcompute.resources import (
JobDescription, TaskDescription, DAG, AutoCluster
job_desc = JobDescription()
#以下省略task的描述内容
split = TaskDescription()
count1 = TaskDescription()
count2 = TaskDescription()
merge = TaskDescription()
task_dag = DAG()
task_dag.add_task(task_name="split", task=split)
task_dag.add_task(task_name="count1", task=count1)
task_dag.add_task(task_name="count2", task=count2)
task_dag.add_task(task_name="merge", task=merge)
task_dag.Dependencies = {
'split': ['count1', 'count2'],
'count1': ['merge'],
'count2': ['merge']
job_desc.DAG = task_dag整个作业的任务执行顺序是:
-
split 运行完成后,count1 和 count2 同时开始运行,count1 和 count2 都完成后,merge 才开始运行。
-
merge 运行完成,整个作业结束。