|
|
|



知乎
有问题就会有答案

李大锤
我们在这篇文章里面探讨了CLIP的可解释性问题:
demo: CLIP_Surgery/demo.ipynb at master · xmed-lab/CLIP_Surgery · GitHub
一. CLIP的可解释性有什么问题
首先我们发现了CLIP的可解释性有两个问题:
1. 可视化结果和人的感知是反的
2. 可视化有非常多的噪声响应
我们主要解释CLIP的原始输出(image tokens),直接inference, 不做bp算梯度。画出simialrity map如下。结果令人意外和GT基本上反的,红色高亮都跑到背景去了。而且很多点状的噪声。原始输出效果很差,和最后一行我们的效果差距很大。
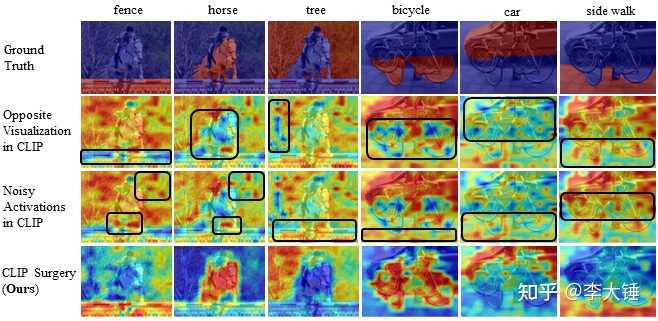

二.为什么有这些问题
1.对于相反结果,原因在于self-attention。
具体来说用原来的query和key的参数出来的特征算self-attention,最相似的token并不是本身或者相同语义区域,而是一些背景的噪声。而用value出来的特征和自己算attention就不会出现错误的关联。出现这种情况的原因主要是训练的pooling不合适,分析在:
https://
arxiv.org/abs/2209.0704
6


2.对于噪声响应,原因在于冗余特征。
总所周知,CLIP基本上类别是无限的,这就导致对于单个类只有很少的特征会响应。所以其他特征基本上都是冗余的。这个很好证明,CLIP输出的logit基本都是0.2-0.3,波动很小,大部分特征都是一致的。另外我们发现不同类之间的噪声都差不多,即使给个空文本噪声也很像(空字符代表所有特征都与类别无关,且冗余)。这进一步说明了冗余导致噪声。

三.解决方案
原因已经找到了,问题就好解决了。我们只需要在结构和特征上对CLIP做些小手术就能优化可视乎结果 (如果不改点东西,有问题的模型可解释性还是差的)。
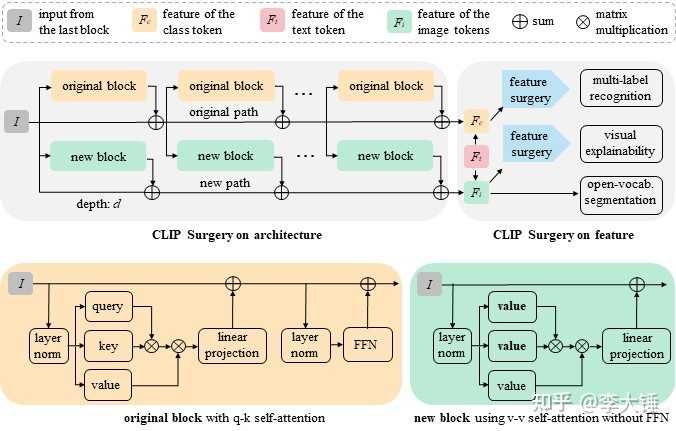

1.CLIP Architecture Surgery
结构上我们用了两个残差通道,一个通道的block只用原始参数的q-k self-attention,另一个通道的block用我们的v-v self-attention。由于中间层有改变,这个额外inference通道是必要的,不然一层叠一层后面模型就崩溃掉了。另外我们发现FFN(MLP)的特征和最后特征差异很大,会起到副作用,所以新分支并不保留FFN的特征。另外由于原始通道不变,后续的分类任务不受影响。
2. CLIP Feature Surgery
我们主要目的是算取一个冗余特征,多类的情况显著的类会影响其他的类(带偏了)。所以我们用类之间的分数作为权重,对每个特征做类别的加权,来抑制显著类的影响。然后在类别维度求均值作为冗余特征,并对每个特征减去冗余特征,然后求和得到余弦相似度。对于单个类来说,如交互式分割和多模态可视化,我们则用空文本特征作为冗余特征。
四. 实验结果和在下游任务的应用
1.可解释性
可解性效果提升是最明显的,比原始CLIP的输出好了几十个点:
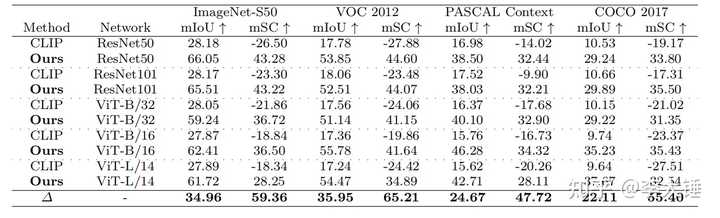

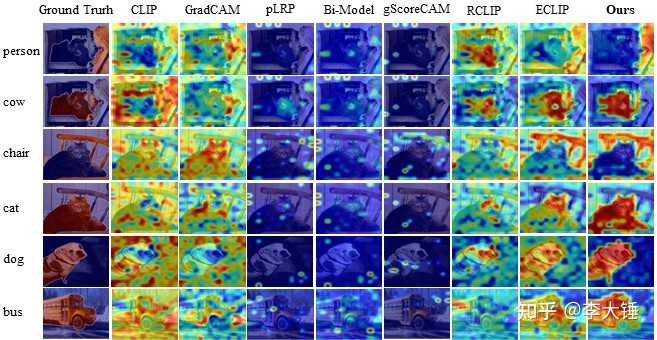
错误的self-attention也能解释为什么有人删掉CLIP中ResNet的最后一个self-attention可以做可视化。但是ViT每层都是self-attention,所以现有的方法在ViT上表现很差(全是self-attention删最后一层没用)。以下方法都统一对ViT-B/16@224最后一层做的解释,我们的方法明显会好一些(RCLIP, ECLIP是我们的早期版本):

2.开放文本分割
有了准确的heatmap就很好做分割了,可以直接做argmax得到最后的mask. 基于可解释性来做分割在context相关的数据集上效果还不错,优势很明显,就是不用任何训练和额外数据:


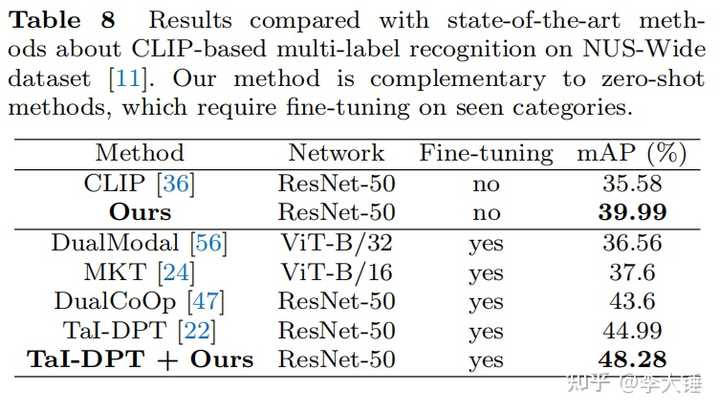
3.开放多标签分类
除此之外我们的算法做open-vocabulary的多标签分类也有效果,可以作为一种后处理任意插到算法里面来提高mAP。原理是抑制冗余特征后会让误报少一些。注意,单类没有效果,因为冗余特征是一个common bias,不改变单张图别之间的位次,而是影响跨图之间的排位来减少误报:

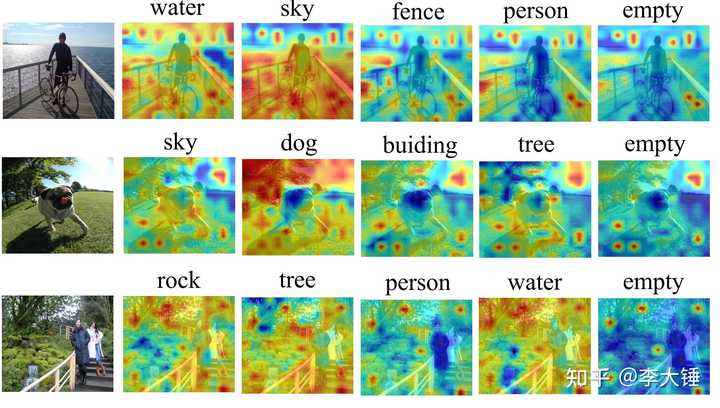
4.多模态可解释性
我们做了多模态的可解释性,解释CLIP训练过程中文本和图片是怎么匹配的,也发现了一些有趣的现象。比如CLIP训练数据一般关注部分物体,如第一张图片只关注了自行车。而且CLIP对文本也有一定的感知,如最后一张。对于文本的解释,一些不重要的词如 'in' 'the' '.' 也经常也有高响应,而且结束符[end]是最高频的。这说明clip会把全局特征编码到固定的token中。


5.交互式分割-SAM的应用
最后我们着重介绍一下SAM。SAM可以支持text prompt输出,但是如原文Fig.12,纯text prompt效果不尽人意,需要人工的点来辅助。 最大的问题是text features来源于CLIP,而CLIP的可解性很差 。文本往往和背景的token匹配上。基于这样 错误匹配的文本特征势必会导致错误的分割结果 。


但是直接分割的效果在边界上做的不好,也有一些噪声。这个时候就该 SAM 出场了。选取一些高分的背景和前景点,经过SAM后就可以得到很好的分割结果了。实验证明我们的方法在点的准确性和最后交互式分割的效果上都比其他可解释性模型高。

另外我们还提供了.ipynb来展示结果,里面有各种可视化的demo和结合SAM的例子:
CLIP_Surgery/demo.ipynb at master · xmed-lab/CLIP_Surgery · GitHub


代码目前是一个demo版本,其他代码过段时间有空再整理。目前这个demo版本和实验的结果稍有不同(APEX amp的fp16没加进来,装起来比较复杂): GitHub - xmed-lab/CLIP_Surgery: CLIP Surgery for Better Explainability with Enhancement in Open-Vocabulary Tasks
编辑于 2023-04-14 23:23
・IP 属地四川
268
37
423
3
