onnx是把一个网络的每一层或者说一个算子当成节点node,使用这些node去构建一个graph,即一个网络。通过onnx.helper来生成onnx
步骤如下:
第一步:node列表,里面通过onnx.helper.make_node生成多个算子节点
第二步:initializer列表,里面通过onnx.helper.make_tensor对算子节点进行初始化
第三步:input和output列表,里面通过onnx.helper.make_value_info生成输入输出
第四步:生成计算图,通过onnx.helper.make_graph将node列表、输入输出作为参数,生成计算图
第五步: 生成模型,通过onnx.helper.make_model
注释:使用onnx.helper的make_tensor,make_tensor_value_info,make_attribute,make_node,make_graph,make_node等方法来完整构建了一个ONNX模型。
实例:通过conv、relu、add等算子来构建一个简单的模型,结构图如下所示:
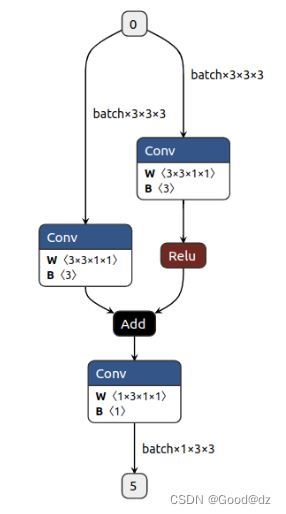
代码如下:
import torch
import torch.nn as nn
import onnx
import onnx.helper as helper
import numpy as np
# reference
# https:
# 构建网络结构
class Model(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(3, 3, 1, 1)
self.relu1 = nn.ReLU()
self.conv2 = nn.Conv2d(3, 1, 1, 1)
self.conv_right = nn.Conv2d(3, 3, 1, 1)
def forward(self, x):
r = self.conv_right(x)
x = self.conv1(x)
x = self.relu1(x)
x = self.conv2(x + r)
return x
def hook_forward(fn):
# @hook_forward("torch.nn.Conv2d.forward") 对torch.nn.Conv2d.forward进行处理
fnnames = fn.split(".") #
fn_module = eval(".".join(fnnames[:-1]))
fn_name = fnnames[-1]
oldfn = getattr(fn_module, fn_name)
def make_hook(bind_fn):
ilayer = 0
def myforward(self, x):
global all_tensors
nonlocal ilayer
y = oldfn(self, x)
bind_fn(self, ilayer, x, y)
all_tensors.extend([x, y]) # 避免torch对tensor进行复用
ilayer += 1
return y
setattr(fn_module, fn_name, myforward)
return make_hook
@hook_forward("torch.nn.Conv2d.forward")
def symbolic_conv2d(self, ilayer, x, y):
print(f"{type(self)} -> Input {get_obj_idd(x)}, Output {get_obj_idd(y)}")
inputs = [
get_obj_idd(x),
append_initializer(self.weight.data, f"conv{ilayer}.weight"),
append_initializer(self.bias.data, f"conv{ilayer}.bias")
nodes.append(
helper.make_node(
"Conv", inputs, [get_obj_idd(y)], f"conv{ilayer}",
kernel_shape=self.kernel_size, group=self.groups, pads=[0, 0] + list(self.padding), dilations=self.dilation, strides=self.stride
@hook_forward("torch.nn.ReLU.forward")
def symbolic_relu(self, ilayer, x, y):
print(f"{type(self)} -> Input {get_obj_idd(x)}, Output {get_obj_idd(y)}")
nodes.append(
helper.make_node(
"Relu", [get_obj_idd(x)], [get_obj_idd(y)], f"relu{ilayer}"
@hook_forward("torch.Tensor.__add__")
def symbolic_add(a, ilayer, b, y):
print(f"Add -> Input {get_obj_idd(a)} + {get_obj_idd(b)}, Output {get_obj_idd(y)}")
nodes.append(
helper.make_node(
"Add", [get_obj_idd(a), get_obj_idd(b)], [get_obj_idd(y)], f"add{ilayer}"
def append_initializer(value, name):
initializers.append(
helper.make_tensor(
name=name,
data_type=helper.TensorProto.DataType.FLOAT,
dims=list(value.shape),
vals=value.data.numpy().astype(np.float32).tobytes(),
raw=True
return name
def get_obj_idd(obj):
global objmap
idd = id(obj)
if idd not in objmap:
objmap[idd] = str(len(objmap))
return objmap[idd]
all_tensors = []
objmap = {}
nodes = []
initializers = []
torch.manual_seed(31)
x = torch.full((1, 3, 3, 3), 0.55)
model = Model().eval()
y = model(x)
inputs = [
helper.make_value_info(
name="0",
type_proto=helper.make_tensor_type_proto(
elem_type=helper.TensorProto.DataType.FLOAT,
shape=["batch", x.size(1), x.size(2), x.size(3)]
outputs = [
helper.make_value_info(
name="5",
type_proto=helper.make_tensor_type_proto(
elem_type=helper.TensorProto.DataType.FLOAT,
shape=["batch", y.size(1), y.size(2), y.size(3)]
graph = helper.make_graph(
name="mymodel",
inputs=inputs,
outputs=outputs,
nodes=nodes,
initializer=initializers
# 如果名字不是ai.onnx,netron解析就不是太一样了 区别在可视化的时候,非ai.onnx的名字的话,每一个算子的框框颜色都是一样的
opset = [
helper.make_operatorsetid("ai.onnx", 11)
# producer主要是保持和pytorch一致
model = helper.make_model(graph, opset_imports=opset, producer_name="pytorch", producer_version="1.9")
onnx.save_model(model, "custom.onnx")
print(y)
参考文献:https://github.com/shouxieai/learning-cuda-trt/blob/main/tensorrt-basic-1.4-onnx-editor/create-onnx.py
整个定义是主要就是这三个部分最外层是ModelProto,记录一些模型信息:ir版本,来自pytorch/tensorflow,… , 和GraphProto////};GraphProto才是核心,里面主要包含:1.保存const tensor + 预训练的参数。2.保存每个op 输入,输出 tensor 名字。}NodeProto}所以整个计算图的node的输入,来自于node.input,node的输出记录在node.output。
可以自定义每列的标题,也可以直接用datatable的字段名。
string[] caption = new string[] { "计划代码", "产品代码", "产品机型", "产品SN", "包装序号", "生产线", "作业人员", "作业时间" };
//NPOIHelper.ExportDTtoExcel(packlistTable, "包装附件清单", fileName);
NPOIHelper.ExportDTtoExcel(packlistTable, "包装附件清单", caption, fileName);
ONNX-开放式神经网络交换格式 - vh_pg - 博客园
Play with ONNX operators — sklearn-onnx 1.9.2 documentation
Python helper.make_graph方法代码示例 - 纯净天空
https://github.com/onnx/onnx/blob/master/onnx/test/helper_test.py
shape (Sequence[Union[int, str]]) :张量的形状,如果模型使用尺寸参数,则可能包含字符串。方便函数,用于获取此张量的输入节点之一的输入张量。producer_idx(int):如果张量有多个生产者,则输入张量的生产者节点的索引,默认为0。注:此处的“空”是指张量的名称,对于可选张量,省略了该名称,而不是张量的形状。tensor_idx(int):输入节点的输入张量的索引,默认为0。方便函数,用于获取此张量的输出节点之一的输出张量。制作此张量的浅拷贝,省略输入和输出信息。
构建onnx方式通常有两种:1、通过代码转换成onnx结构,比如pytorch —> onnx2、通过onnx 自定义结点,图,生成onnx结构本文主要是简单学习和使用两种不同onnx结构,下面以gather结点进行分析。
在进行模型融合时,我们通常需要将多个模型的层合并为一个自定义节点,以提高模型推理效率和减少推理时间。其中,'custom_node’为自定义节点的名称,'input_tensor’为输入节点名称,'output_tensor’为输出节点名称,value_list为节点属性列表。
ONNX是开放式神经网络(Open Neural Network Exchange)的简称,主要由微软和合作伙伴社区创建和维护。很多深度学习训练框架(如Tensorflow, PyTorch, Scikit-learn, MXNet等)的模型都可以导出或转换为标准的ONNX格式,采用ONNX格式作为统一的界面,各种嵌入式平台就可以只需要解析ONNX格式的模型而不用支持多种多样的训练框架,本文主要介绍如何通过代码或JSON文件的形式来构造一个ONNX单算子模型或者整个graph,以及使用ONN...

