


DataFrame的分组排序(笔试常用)

零基础学Python数据分析 >> Pandas >> DataFrame的分组排序(笔试常用)
前言
大家好,这里是零基础学Python数据分析系列。
这个系列所有的代码编写均是Python3版本。
之前我们介绍了DataFrame的排序函数和分组函数,那么如何实现DataFrame的分组排序呢?这也是Pandas笔试题常考的内容。
本章让我们来解决两个问题:
问题1:如何取出每个班级Python成绩的第一名?(分组排序,取每组的前几条数据)
问题2:给每个学生按班级进行Python成绩排名,新增一个排名的序号。(分组排序,给每个样本按类型加个序号)
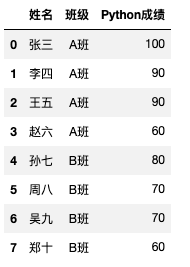
先创建一个DataFrame
先创建一个学生姓名、班级、Python成绩的DataFrame。
输入:
import pandas as pd
import numpy as np
Student_dict = {'姓名':['张三', '李四', '王五', '赵六', '孙七', '周八', '吴九', '郑十'],
'班级':['A班', 'A班', 'A班', 'A班','B班', 'B班','B班', 'B班'],
'Python成绩':[100, 90, 90, 80, 90, 80, 70, 60]}
# 字典创建DataFrame,字典键变DataFrame的列名
df = pd.DataFrame(data=Student_dict)
df输出:
这两个问题应该如何实现?
问题1:如何取出每个班级Python成绩的第一名?(分组排序,取每组的前几条数据)
问题2:给每个学生按班级进行Python成绩排名,新增一个排名的序号。(分组排序,给每个样本按类型加个序号)
问题1:分组排序,取每组的前几条数据
取每个班级Python成绩的第一名,我们可以先用sort_values函数按Python成绩逆序排序,再分组取每组的第一条数据。
实现方式如下:
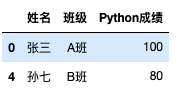
# 取出每个班级,Python成绩第一名的学生。
# 先排序
df = df.sort_values('Python成绩', ascending=False)
# 再分组取每组的第一条数据
df.groupby('班级').head(1)输出:
说明:
groupby函数有一个特性,分组后,每组的数据排序和原来的数据排序是一样的。
比如原数据,按Python成绩倒序排序后,分组后,每组的样本还是按Python成绩倒序排序。
所以可以先用sort_values函数按Python成绩逆序排序,再分组取每组的第一条数据,以此来得到每个班级Python成绩的第一名。
问题2: 分组排序,给每个样本按类型加个序号
DataFrame的排名函数rank()
首先我们来介绍一下DataFrame的的排名函数rank()。
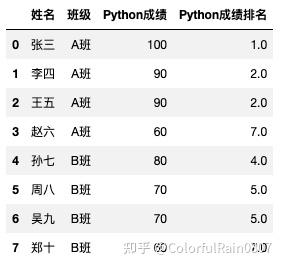
用rank函数,给每个学生进行Python成绩排名,新增一个排名的序号。(此处不分班级,介绍一下rank函数的用法)
输入:
# rank函数
df['Python成绩排名'] = df['Python成绩'].rank(method='min', ascending=False)
df输出:
rank函数参数介绍:
ascending:排序方式,True正序,False逆序。
method:如何对具有相同值的记录进行排名。取值可以为:average、min、max、first、dense。
average:相同排名下,取平均值进行排名。比如李四、王五为第二、第三名,孙7为第四名,那么李四、王五取值为2.5,孙7取值为4。