


Prometheus-基础系列-(四)-PromQL语句实践-2

接着上一章
PromQL聚合操作
Prometheus还提供了下列内置的聚合操作符,这些操作符作用域瞬时向量。可以将瞬时表达式返回的样本数据进行聚合,形成一个新的时间序列。
-
sum(求和) -
min(最小值) -
max(最大值) -
avg(平均值) -
stddev(标准差) -
stdvar(标准差异) -
count(计数) -
count_values(对value进行计数) -
bottomk(后n条时序) -
topk(前n条时序) -
quantile(分布统计)
使用聚合操作的语法如下:
<aggr-op>([parameter,] <vector expression>) [without|by (<label list>)]
其中只有
count_values
,
quantile
,
topk
,
bottomk
支持参数(parameter)。
without用于从计算结果中移除列举的标签,而保留其它标签。by则正好相反,结果向量中只保留列出的标签,其余标签则移除。通过without和by可以按照样本的问题对数据进行聚合。
例如:
sum(prometheus_http_requests_total) without (instance)
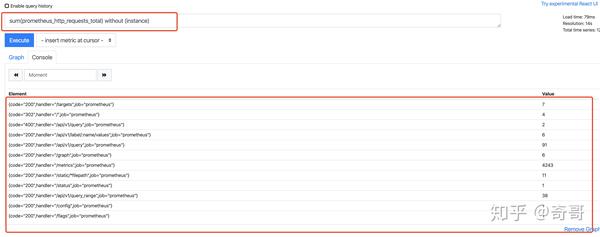
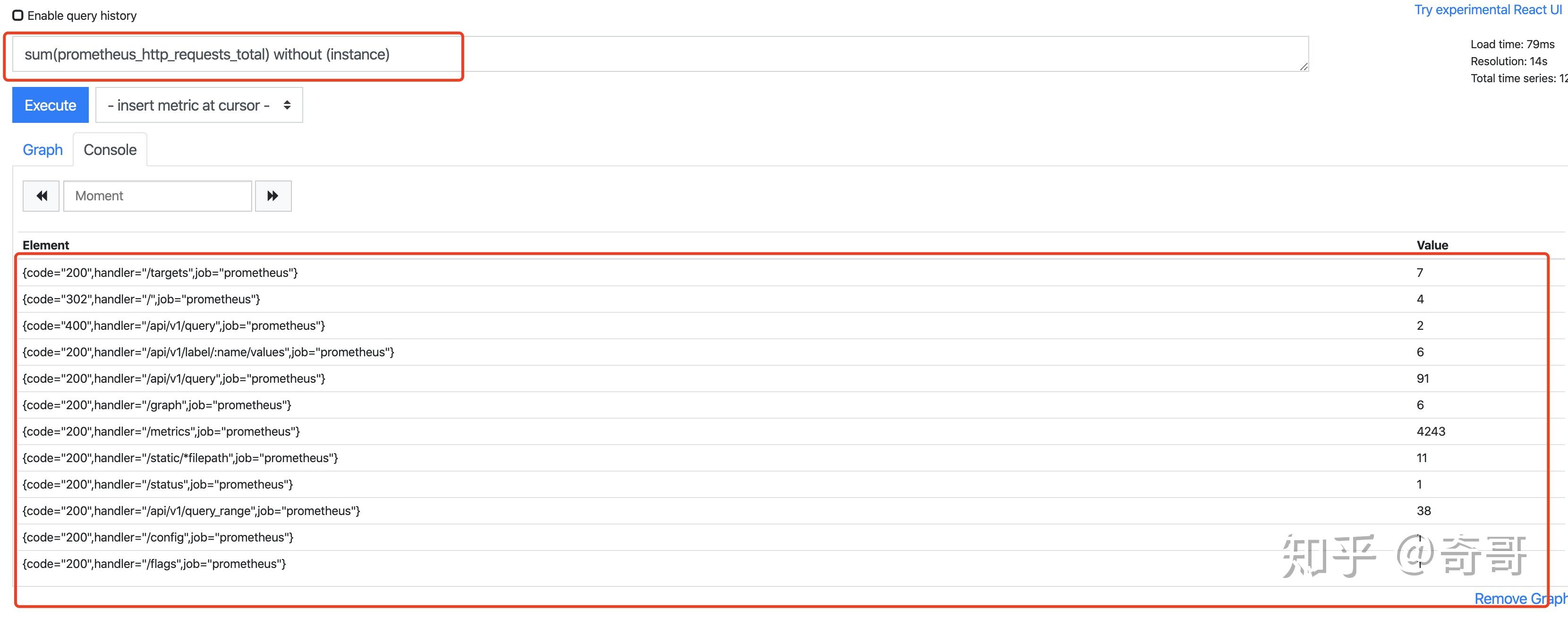
等价于
sum(prometheus_http_requests_total) by (code,handler,job,method)

略有不同是排序
如果只需要计算整个应用的HTTP请求总量,可以直接使用表达式:
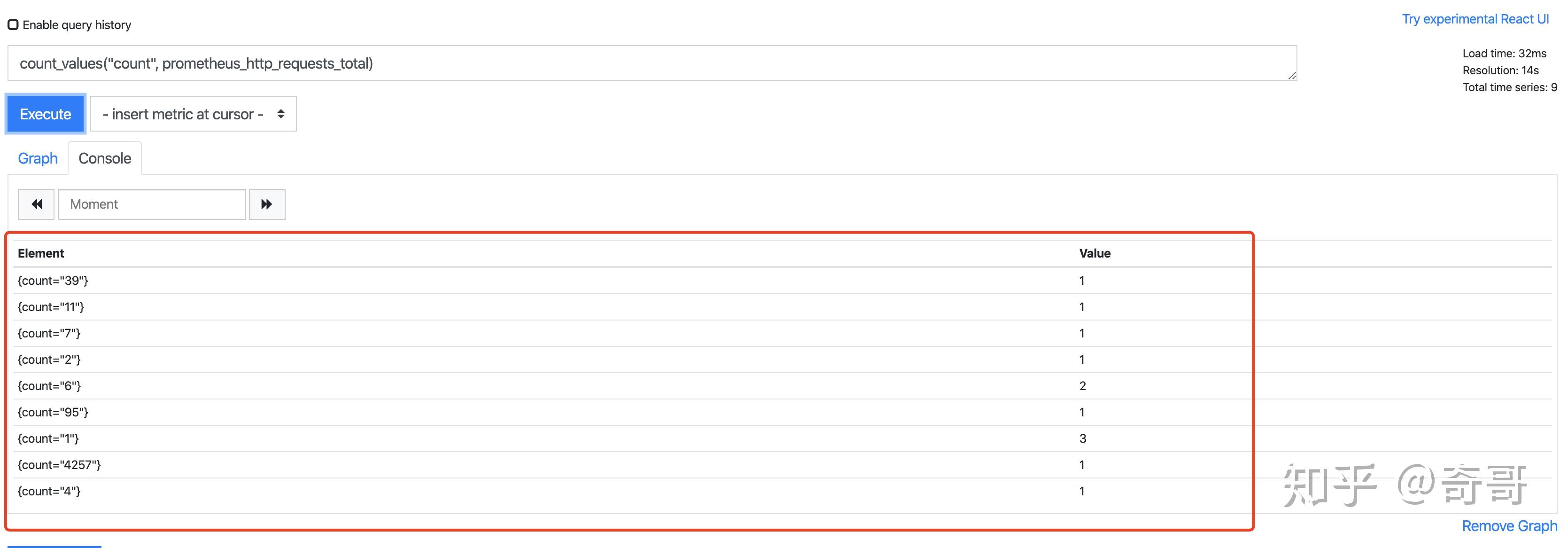
sum(prometheus_http_requests_total)count_values用于时间序列中每一个样本值出现的次数。count_values会为每一个唯一的样本值输出一个时间序列,并且每一个时间序列包含一个额外的标签。
例如:
count_values("count", prometheus_http_requests_total)

topk和bottomk则用于对样本值进行排序,返回当前样本值前n位,或者后n位的时间序列。
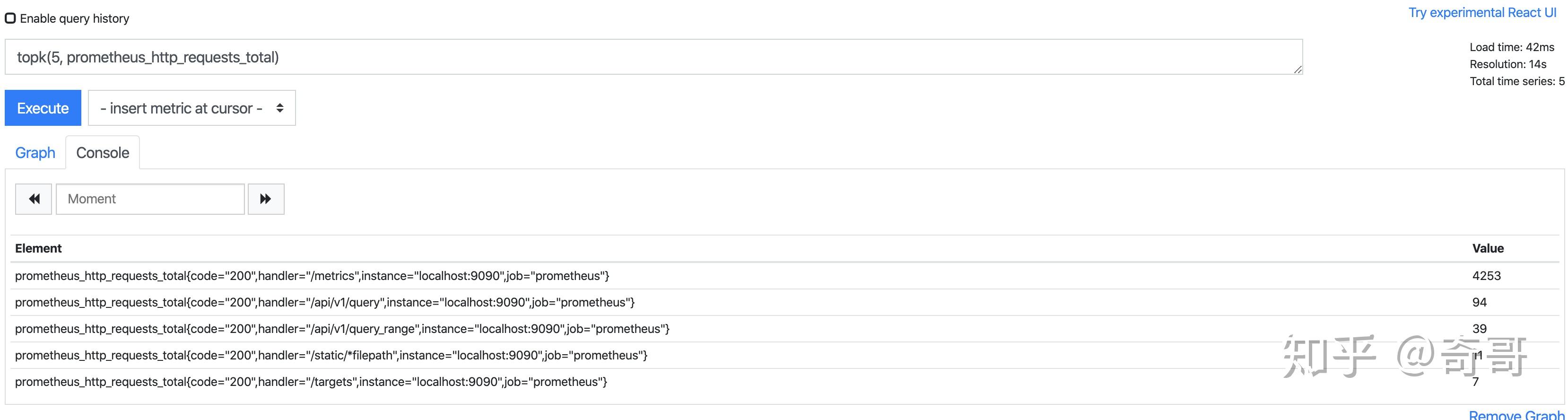
获取HTTP请求数前5位的时序样本数据,可以使用表达式:
topk(5, prometheus_http_requests_total)

quantile用于计算当前样本数据值的分布情况quantile(φ, express)其中0 ≤ φ ≤ 1。
例如,当φ为0.5时,即表示找到当前样本数据中的中位数:
quantile(0.5, prometheus_http_requests_total)PromQL内置函数
在上一小节中,我们已经看到了类似于irate()这样的函数,可以帮助我们计算监控指标的增长率。除了irate以外,Prometheus还提供了其它大量的内置函数,可以对时序数据进行丰富的处理。本小节将带来读者了解一些常用的内置函数以及相关的使用场景和用法。
计算Counter指标增长率
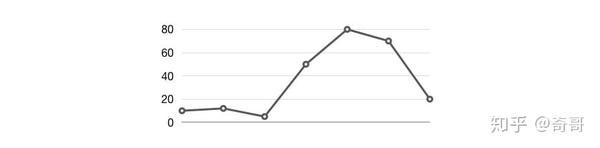
我们知道Counter类型的监控指标其特点是只增不减,在没有发生重置(如服务器重启,应用重启)的情况下其样本值应该是不断增大的。为了能够更直观的表示样本数据的变化剧烈情况,需要计算样本的增长速率。
如下图所示,样本增长率反映出了样本变化的剧烈程度:

-
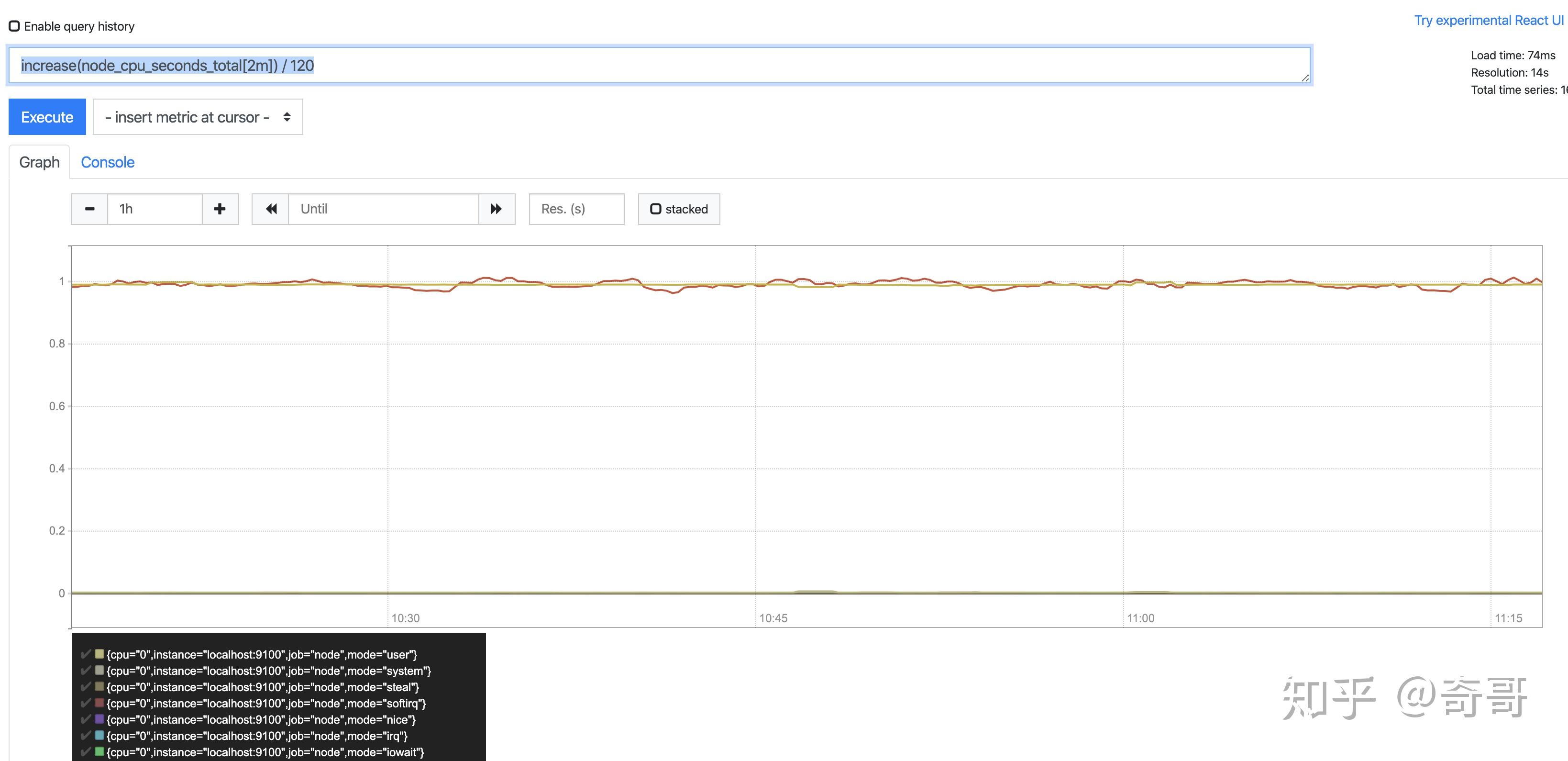
increase(v range-vector)函数是PromQL中提供的众多内置函数之一。其中参数v是一个区间向量,increase函数获取区间向量中的第一个后最后一个样本并返回其增长量。因此,可以通过以下表达式Counter类型指标的增长率:
increase(node_cpu_seconds_total[2m]) / 120这里通过node_cpu_seconds_total[2m]获取时间序列最近两分钟的所有样本,increase计算出最近两分钟的增长量,最后除以时间120秒得到node_cpu_seconds_total样本在最近两分钟的平均增长率。并且这个值也近似于主机节点最近两分钟内的平均CPU使用率。
-
rate(v range-vector)函数,rate函数可以直接计算区间向量v在时间窗口内平均增长速率。因此,通过以下表达式可以得到与increase函数相同的结果:
rate(node_cpu_seconds_total[2m])
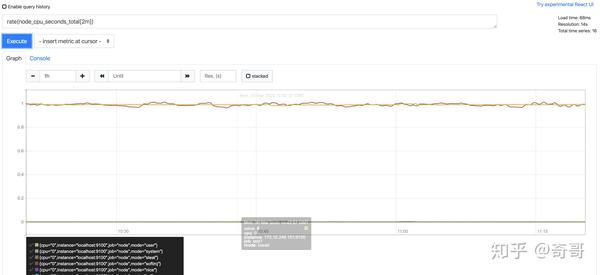
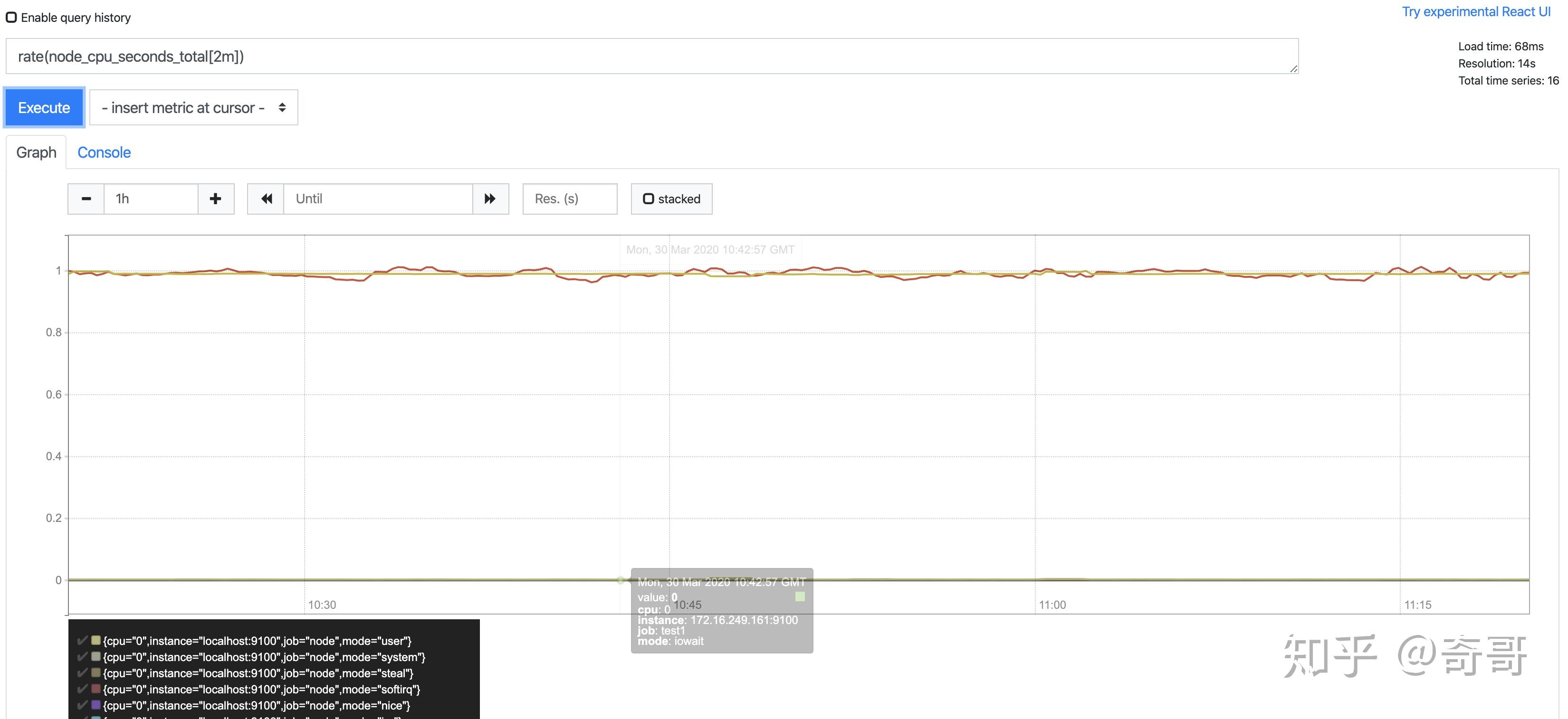
需要注意的是使用rate或者increase函数去计算样本的平均增长速率,容易陷入“长尾问题”当中,其无法反应在时间窗口内样本数据的突发变化。 例如,对于主机而言在2分钟的时间窗口内,可能在某一个由于访问量或者其它问题导致CPU占用100%的情况,但是通过计算在时间窗口内的平均增长率却无法反应出该问题。
-
irate(v range-vector)。irate同样用于计算区间向量的计算率,但是其反应出的是瞬时增长率。
irate函数是通过区间向量中最后两个两本数据来计算区间向量的增长速率。这种方式可以避免在时间窗口范围内的“长尾问题”,并且体现出更好的灵敏度,通过irate函数绘制的图标能够更好的反应样本数据的瞬时变化状态。
irate(node_cpu_seconds_total[2m])
irate函数相比于rate函数提供了更高的灵敏度,不过当需要分析长期趋势或者在告警规则中,irate的这种灵敏度反而容易造成干扰。因此在
长期趋势分析或者告警中更推荐使用rate函数
。
预测Gauge指标变化趋势
在一般情况下,系统管理员为了确保业务的持续可用运行,会针对服务器的资源设置相应的告警阈值。
例如:
当磁盘空间只剩512MB时向相关人员发送告警通知。 这种基于阈值的告警模式对于当资源用量是平滑增长的情况下是能够有效的工作的。 但是如果资源不是平滑变化的呢? 比如有些某些业务增长,存储空间的增长速率提升了高几倍。这时,如果基于原有阈值去触发告警,当系统管理员接收到告警以后可能还没来得及去处理问题,系统就已经不可用了。 因此阈值通常来说不是固定的,需要定期进行调整才能保证该告警阈值能够发挥去作用。 那么还有没有更好的方法吗?
PromQL中内置的
predict_linear(v range-vector, t scalar)
函数可以帮助系统管理员更好的处理此类情况,
predict_linear
函数可以预测时间序列v在t秒后的值。它基于简单线性回归的方式,对时间窗口内的样本数据进行统计,从而可以对时间序列的变化趋势做出预测。
例如:
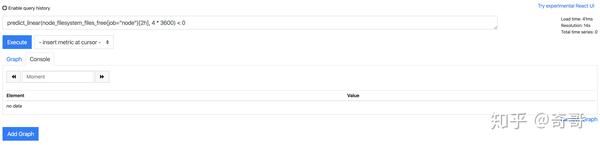
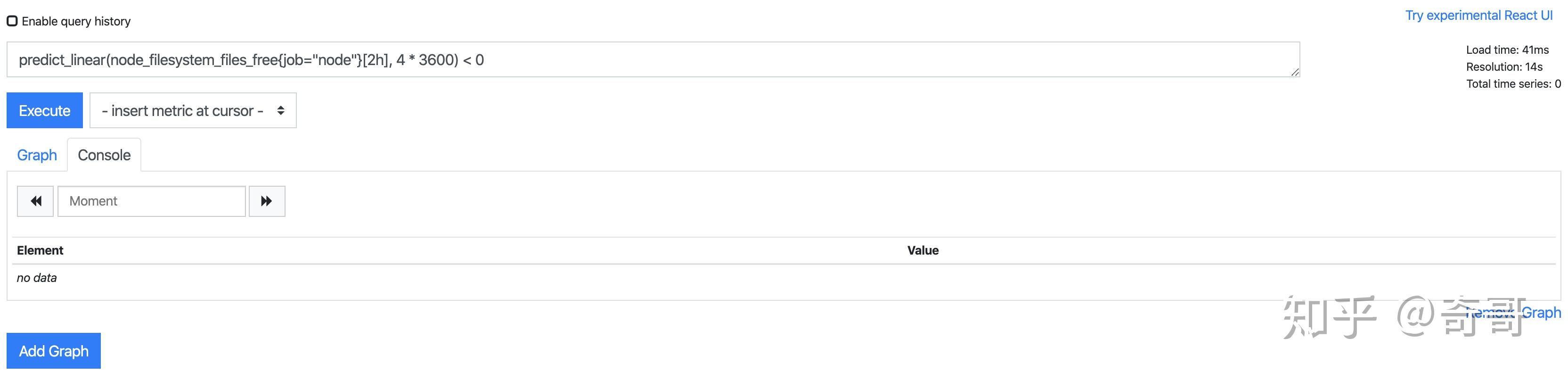
基于2小时的样本数据,来预测主机可用磁盘空间的是否在4个小时候被占满,可以使用如下表达式:
predict_linear(node_filesystem_files_free{job="node"}[2h], 4 * 3600) < 0
统计Histogram指标的分位数
Histogram和Summary都可以同于统计和分析数据的分布情况。区别在于Summary是直接在客户端计算了数据分布的分位数情况。而Histogram的分位数计算需要通过histogram_quantile(φ float, b instant-vector)函数进行计算。其中φ(0<φ<1)表示需要计算的分位数,如果需要计算中位数φ取值为0.5,以此类推即可。
以指标prometheus_http_request_duration_seconds_bucket为例:
当计算9分位数时,使用如下表达式:
histogram_quantile(0.5, prometheus_http_request_duration_seconds_bucket)通过对Histogram类型的监控指标,用户可以轻松获取样本数据的分布情况。同时分位数的计算,也可以非常方便的用于评判当前监控指标的服务水平。
以Grafana展示为例子
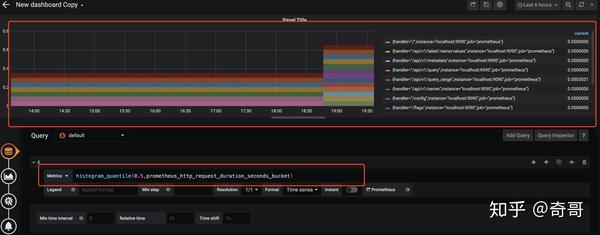
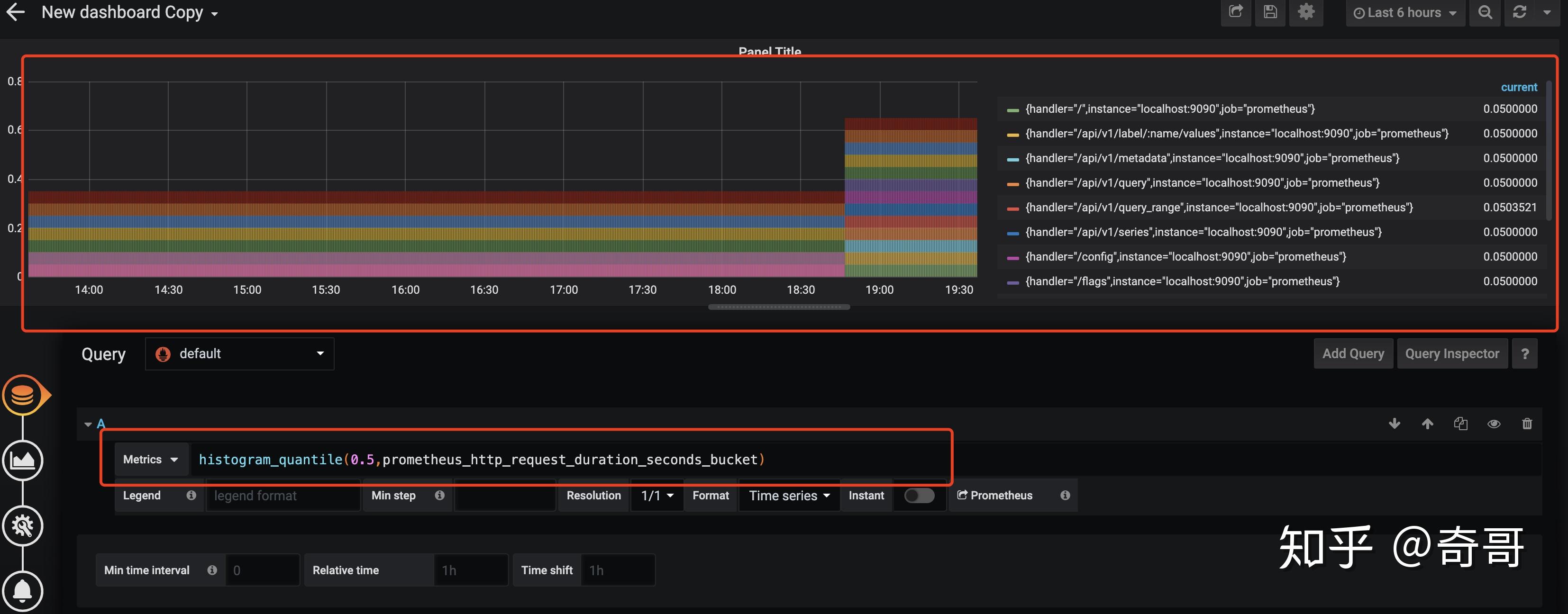
需要注意的是通过histogram_quantile计算的分位数,并非为精确值,而是通过prometheus_http_request_duration_seconds_bucket和prometheus_http_request_duration_seconds_sum近似计算的结果。
动态标签替换
一般来说来说,使用PromQL查询到时间序列后,可视化工具会根据时间序列的标签来渲染图表。例如通过up指标可以获取到当前所有运行的Exporter实例以及其状态:
up{instance="localhost:8080",job="cadvisor"} 1
up{instance="localhost:9090",job="prometheus"} 1
up{instance="localhost:9100",job="node"} 1这是可视化工具渲染图标时可能根据,instance和job的值进行渲染,为了能够让客户端的图标更具有可读性,可以通过label_replace标签为时间序列添加额外的标签。label_replace的具体参数如下:
label_replace(v instant-vector, dst_label string, replacement string, src_label string, regex string)该函数会依次对v中的每一条时间序列进行处理,通过regex匹配src_label的值,并将匹配部分relacement写入到dst_label标签中。如下所示:
label_replace(up, "host", "$1", "instance", "(.*):.*")函数处理后,时间序列将包含一个host标签,host标签的值为Exporter实例的IP地址:
up{host="localhost",instance="localhost:8080",job="cadvisor"} 1
up{host="localhost",instance="localhost:9090",job="prometheus"} 1
up{host="localhost",instance="localhost:9100",job="node"} 1除了label_replace以外,Prometheus还提供了label_join函数,该函数可以将时间序列中v多个标签src_label的值,通过separator作为连接符写入到一个新的标签dst_label中:
label_join(v instant-vector, dst_label string, separator string, src_label_1 string, src_label_2 string, ...)label_replace和label_join函数提供了对时间序列标签的自定义能力,从而能够更好的于客户端或者可视化工具配合。
其他内置函数直接参考官网
https:// prometheus.io/docs/prom etheus/latest/querying/functions/
HTTP API中使用PromQL
Prometheus当前稳定的HTTP API可以通过/api/v1访问。
API响应格式
Prometheus API使用了JSON格式的响应内容。 当API调用成功后将会返回2xx的HTTP状态码。
反之,当API调用失败时可能返回以下几种不同的HTTP状态码:
- 404 Bad Request:当参数错误或者缺失时。
- 422 Unprocessable Entity 当表达式无法执行时。
- 503 Service Unavailiable 当请求超时或者被中断时。
所有的API请求均使用以下的JSON格式:
{
"status": "success" | "error",
"data": <data>,
// Only set if status is "error". The data field may still hold
// additional data.
"errorType": "<string>",
"error": "<string>"
}HTTP API
通过HTTP API我们可以分别通过/api/v1/query和/api/v1/query_range查询PromQL表达式当前或者一定时间范围内的计算结果。
瞬时数据查询
通过使用QUERY API我们可以查询PromQL在特定时间点下的计算结果。
GET /api/v1/queryURL请求参数:
- query=:PromQL表达式。
- time=:用于指定用于计算PromQL的时间戳。可选参数,默认情况下使用当前系统时间。
- timeout=:超时设置。可选参数,默认情况下使用-query,timeout的全局设置。
例如使用以下表达式查询表达式up在时间点2020-03-30T20:10:51.781Z的计算结果:
$ curl 'http://localhost:9090/api/v1/query?query=up&time=2020-03-30T20:10:51.781Z'
"status" : "success",
"data" : {
"resultType" : "vector",
"result" : [
"metric" : {
"__name__" : "up",
"job" : "prometheus",
"instance" : "localhost:9090"
"value": [ 1435781451.781, "1" ]
"metric" : {
"__name__" : "up",
"job" : "node",
"instance" : "localhost:9100"
"value" : [ 1435781451.781, "0" ]
}响应数据类型
当API调用成功后,Prometheus会返回JSON格式的响应内容,格式如上小节所示。并且在data节点中返回查询结果。data节点格式如下:
{
"resultType": "matrix" | "vector" | "scalar" | "string",
"result": <value>
}PromQL表达式可能返回多种数据类型,在响应内容中使用resultType表示当前返回的数据类型,包括:
- 瞬时向量:vector
当返回数据类型resultType为vector时,result响应格式如下:
[
"metric": { "<label_name>": "<label_value>", ... },
"value": [ <unix_time>, "<sample_value>" ]
]其中metrics表示当前时间序列的特征维度,value只包含一个唯一的样本。
- 区间向量:matrix
当返回数据类型resultType为matrix时,result响应格式如下:
[
"metric": { "<label_name>": "<label_value>", ... },
"values": [ [ <unix_time>, "<sample_value>" ], ... ]
]其中metrics表示当前时间序列的特征维度,values包含当前事件序列的一组样本。
- 标量:scalar
当返回数据类型resultType为scalar时,result响应格式如下:
[ <unix_time>, "<scalar_value>" ]由于标量不存在时间序列一说,因此result表示为当前系统时间一个标量的值。
- 字符串:string
当返回数据类型resultType为string时,result响应格式如下:
[ <unix_time>, "<string_value>" ]字符串类型的响应内容格式和标量相同。
区间数据查询
使用QUERY_RANGE API我们则可以直接查询PromQL表达式在一段时间返回内的计算结果。
GET /api/v1/query_rangeURL请求参数:
- query=: PromQL表达式。
- start=: 起始时间。
- end=: 结束时间。
- step=: 查询步长。
- timeout=: 超时设置。可选参数,默认情况下使用-query,timeout的全局设置。
当使用QUERY_RANGE API查询PromQL表达式时,返回结果一定是一个区间向量:
{
"resultType": "matrix",
"result": <value>
}需要注意的是,在QUERY_RANGE API中PromQL只能使用瞬时向量选择器类型的表达式。
例如使用以下表达式查询表达式up在30秒范围内以15秒为间隔计算PromQL表达式的结果。
$ curl 'http://localhost:9090/api/v1/query_range?query=up&start=2015-07-01T20:10:30.781Z&end=2015-07-01T20:11:00.781Z&step=15s'
"status" : "success",
"data" : {
"resultType" : "matrix",
"result" : [
"metric" : {
"__name__" : "up",
"job" : "prometheus",
"instance" : "localhost:9090"
"values" : [
[ 1435781430.781, "1" ],
[ 1435781445.781, "1" ],
[ 1435781460.781, "1" ]
"metric" : {
"__name__" : "up",
"job" : "node",
"instance" : "localhost:9091"
"values" : [
[ 1435781430.781, "0" ],
[ 1435781445.781, "0" ],