|
|
|


参加 TiDB Hackathon 2022 是什么体验?
关注者
54
被浏览
30,920
10 个回答

这次和小伙伴组了一个叫“摸鱼就是”的队伍,项目名称是 Double My QPS ,最终有幸获得了 TiDB 产品组一等奖。基本的想法是在不增加硬件成本的情况下,一键让 TiDB QPS 性能翻倍,为注重性价比的 TiDB 用户服务。


非常幸运,找到了 @pingyu 、 tengjin 、 liming 三位靓仔做队友,并获得了许多同学的支持和鼓励。感谢 @黄漫绅 、 @姚维 、 @Ed Huang 和广州 office 大家庭的小伙伴们,以及 @唐刘 亲自来广州给我们加油(他一来广州赛区就两个一等奖,没有 buff 谁信啊)。
缘起
来 P 社 4 年多了,前几届都会羡慕参赛同学的热闹,然而想报名的念头总是被“上班已经好累周末不如宅家玩dota”的念头轻松击败。这次参加比赛,缘起是午饭时间和 @黄漫绅 (贵司和社区的同学亲切的称呼为表妹)吹水,了解到报名队伍还不多,提交 rfc 就有奖,就马上报了名,并强行拉上了对面一脸懵逼在干饭的 pingyu。简单对了一下想法,我自己主要是搞 AP 的(TiFlash 摸鱼达人一枚),不想在周末还要加班搞,就提议来搞 TP 方向吧。然后我对 TP 了解也不多,那就来卷最简单直接的 QPS 性能吧。我估计当时 pingyu 老师的内心 OS:干啥不重要,反正队长写 rfc 混个决赛礼包就行。然后又依据人多力量大,大力出奇迹的思路,通过逐渐熟练的忽悠技巧,把 tengjin 和 liming 连哄带骗拉进了项目群。
初赛的插曲
我最初的想法是扯一个大点的牛皮,定个大目标性能提升一倍,再在这个框架下各自整点花活。反正性能优化嘛,没有固定标准的东西,大家乐呵乐呵随便搞搞,最不济去掉一些统计逻辑、调优参数什么的,提高10% 应该能做到的。反正又不是老板定的 kpi ,是否实现无所谓(最后果然没有完全实现 Orz)。
所以 rfc 也没怎么好好写。然而最后时刻有 80 只队伍提交了 rfc,初赛突然就变成了 80 进 60。最后初赛结果出炉,我们非常惊险的以最后一名身份晋级……
???说好的“不卷,躺进决赛”原来都是骗人的啊!然后,岁月静好的画风就突然变得热血起来了。


比赛过程
既然是性能优化,最简单的方法是先看看目前的瓶颈在哪里。考虑到 hackathon 时间紧张,所以我们选择了一个有代表性但是比较简单(我能看懂代码逻辑)的 workload:sysbench oltp_point_select 。
我们部署了一个 TiDB v6.3.0 集群来跑性能测试,找找感觉。集群拓扑是 1 TiDB (8C, 16G) + 3 TiKV(8C, 64G),只部署 1 个 TiDB 节点是考虑到我们这个方案是给注重性价比的用户准备的(另外也没这么多机器 Orz)。
然后一顿性能测试跑下来,我们直接傻眼了,TiDB CPU 打满,成为了最严重的瓶颈。并且我曾经设想的调参数、提高并发利等等简单方法统统没有效果(资源都已经用完了还提高个啥呀)。然后就拉了火焰图,一个个模块的深入分析找优化点,期待哪里代码写得比较挫,给个优化的机会。结果被狠狠打脸,TiDB 的开发者已经做得非常好了,根本不给我们一点机会啊…… 最后猥琐的想把统计信息的逻辑去掉(ExecStmt.SummaryStmt()),预期能省 5% CPU,但是考虑到会被评委喷死,最后没敢用上。
好了,这时候可以认真考虑退赛的问题了。然而由于报名之后我就在办公室各种吹牛这是个冠军项目(前提是能搞出来 ),把小伙伴的期望值都拉高了,见面就问一句 “Double 了吗”,真是让人骑虎难下……
然后在和队伍的小伙伴的脑暴过程中,明确了解决瓶颈的主要思路就是提高 CPU 的效率,即用更少的 CPU cycle 做同样的事情。由于我对 AP 比较熟悉,就想借用一下 AP 领域的性能优化套路:代码生成太高端了也确实不适合,那就搞攒批执行吧。
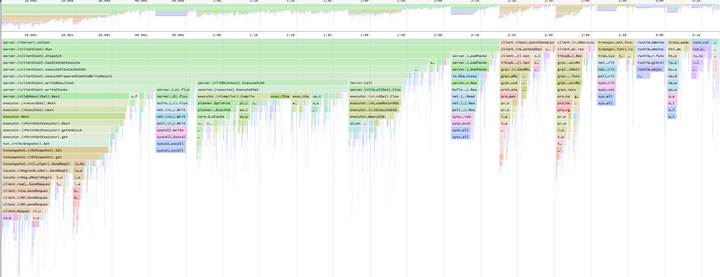
但说起搞 batch,TiDB 其实能搞的基本都有了,比如 chunk 什么的。而且我们这个点查的场景,一条 SQL 就只涉及一条数据,所以唯一的机会就是跨 SQL batch!即让多条拥有相同执行计划的 SQL,可以用一个执行过程同时处理。下面是 TiDB 跑 sysbench oltp_point_select 负载的火焰图,也就是这一坨代码跑一轮,只处理了一行数据,我们想让它可以处理多行数据,从而提高 CPU 利用率。

方案看起来可行,但是需要对 TiDB 的计算框架做大量改动,比赛强行进入 hard mode 。还好我们队有 tengjin 这种大佬, 一点都不慌。 tengjin 大佬在周三公布名单后开撸,周四就在群里报告已经能跑起来了,tql!然而帅不过一秒就扑街了。

然后 tengjin 就一直在改代码,修 bug,时间就突然快进到了周六,正式比赛日。
周六早上我们简短的讨论了一下,由于我们做了攒批,所以预计 Query Duration 是会上升的,需要从其他地方找补回来。经过一番研究,pingyu 和 liming 决定从 TiKV 端下手,优化 BatchGet 接口的延时。


周六白天的情况是,tengjin 在折腾 TiDB 的 batch 执行问题,pingyu 和 liming 在 TiKV 埋头大干 batch get 并行化和 async io,呈现出一派热火朝天的氛围。而我主要在悠闲的跑跑测试,时不时站在队友身后指指点点,然后去和其他团队交(chui)流(niu),并收获了这些重要情报:隔壁 breezewish 的项目(图一乐, Data Dance )太炫目了,收费界面都准备好了;nolouch 的项目(我垫你们蹲, TiFlash Collocated Optimization ) PPT 周五就写好了啊!卷王!;crazycs520 的项目(TiFancy, TiFancy )太diao 了,提升 50 倍吓死人……



然后,高潮来了!周六下午 18:30,TiDB batch 执行的 bug 修完,我推上去一跑,好家伙,性能提高了 30%,然后 CPU 才用了 68%,再抓个火焰图一看,新加的代码还有优化空间!按这个节奏下去,想办法吃完 CPU,代码随便优化一下,提升 100% 触手可及啊!此时的我已经默默开始练习领奖台词了:先感谢队友,感谢主办方,再幽默的赞美一下社区的小姐姐和自愿者,感叹其它队伍的强大,最后表示明年还来。


然后就去吃饭,吃完磨磨蹭蹭,再跑去和其它队伍吹水,到处宣扬我们已经 Double 了,你们努努力竞争二等奖吧。然而回去仔细一看,我艹 TiKV 怎么没有负载啊…… 莫非 TiDB 最近上了量子通信?最后自然是代码有问题,请求错误的复用了上次查询的结果。火速修复之后颤抖的推上去一跑,优化后的真实性能不能说毫无提升,比原来还差…… hmmmm 我想不到词汇形容那种又尴尬又挫败又有点想笑的感觉。
然后 tengjin 就搬了把椅子坐在我旁边,也不怎么说话,就默默优化代码;我对着火焰图发呆;pingyu 老师在埋头搞 RocksDB 不知道发生了什么事情;liming 不知道啥时候溜回家了(盲猜回去陪妹子了),但是半夜一点半还在提交代码。
管他呢,这不是还有优化点没搞完嘛。我们就边测试边讨论,把新的逻辑用更高效的写法重新实现,另外把线程和任务分发模型也重新优化了一遍,并且各种尝试攒批的参数。然后性能神奇的慢慢变好了,90% -> 130% -> 140% -> 160%。等回过神来已经周日早上 2 点了,实在顶不住,就先回去睡觉。临走时 pingyu 老师还在和 RocksDB 大战 300 回合。
第二天一早,liming 在群里宣布 TiKV 并发优化也推上去了,然后下午吃完饭,我躲到会议室里练习答辩。出来后 pingyu 老师的 async io 也搞定了,队友真是靠谱的让人感动…… 这个时候 QPS 性能达到了 165%,并且由于 TiKV 的优化 Query Duration 也下降了。


然而这个时候,经历了大喜大悲+熬夜的我已经没有啥情绪了,只是在反复测试,确保没有再出现其他幺儿子。撑到下午 3 点多开始答辩,毕竟练习了几次,时间和节奏控制的刚刚好,演示效果也不错。实话说我现在已经忘记评委老师的具体问题了(太累了),只记得答辩完后办公室的大家都围在 tengjin 和 liming 的座位后面聊天,唐刘也跑到外面和我们讨论性能优化的问题,我们还现场做了几组测试。
小小的总结
这次比赛我们的主要套路是,先整一个比较大的且对产品有帮助的优化目标,最刺激的是没人知道能具体实现多少。然后队伍里边每个同学都能找到自己擅长的点去折腾,最后几个大佬的思维在短时间内在一起碰撞,迸发的能量让人惊叹。
我觉得 Double My QPS 这个项目主要的贡献是给 TiDB 引入了一种全新的针对 TP 业务的优化方法,即在 SQL 之间攒批执行,相同执行计划的 SQL 可以被同时执行。这个优化效果显著(虽然没有真正达到 Double 的效果),并且可以做到无副作用,同时可以被复制到其他负载。最重要的是,它是可以落地的!
比赛过程跌宕起伏大起大落,我觉得体验的价值远超荣誉和奖金,特别是和队友拼尽全力解决一个个问题的过程弥足珍贵。感谢主办方提供的舞台。


附录

我们队叫我垫你们蹲,成员有我、徐指导、耿子哥、宁子哥。这次搞了一个利用索引实现数据分布,再实现 Collocated 优化的项目。
众所周知:
TiDB 是分布式而不支持 Collocated 优化的唯一的数据库…… TiDB 睁大眼睛说,“你怎么这样凭空污人清白……” “什么清白?我前天亲眼见你跑了个 Join, 吊着打 。”
不是我们不想搞,而是主键分布实在太顽固!


那咋办呢?只能靠着数据冗余(Replica)实现 Collocation 了,于是我们先后研究了两种 Replica:一是 TiFlash Replica,但 TiFlash Replica 作为 Region 层面的 Replica,同样受主键分布的制约;二是 ETL 同步到外部系统,但代价是要解决复杂的一致性、实时性问题,很不 HTAP。


那有没有这么一种 Replica,它即有独立于主键的分布,同时又能很好的保证一致性、实时性呢?理性分析之后,觉得这东西怎么这么像(二级)索引?


于是格局打开了,路走宽了。我们顺着二级索引的思路,开发了一种新的索引类型:重分布索引。本质上就是一个二级且聚簇的索引:二级性体现在独立副本、按索引列(而非主键)排序;聚簇性体现在索引的值中存储整行的数据(而不是二级索引那样存储主键)。当然,这样的索引还不能保证所有索引列相同的行被分布到相同的节点,因为即便数据在 Key 层面是按索引列连续的, 但随着 Region 分裂、合并、搬迁,索引列相同的行可能存在于多个 Region 并被调度到不同的节点,这就破坏了 Collocation。因此还要辅助以一定的调度手段,我们称之为数据亲和性调度,它是通过 Placement Rule 来实现的调度规则,在 Region 分裂、合并、搬迁会考虑索引列的边界,保证不破坏 Collocation。另外为了实现多表(索引)之间的 Collocation(用于实现 Collocated Join),与许多友商一样,我们还引入了 Collocation Group 的概念,然后同样利用数据亲和性调度来保证多表(索引)数据的 Collocation。具体的用法就是在建表语句中指定重分布的索引列及所属的 Collocation Group 即可:
CREATE TABLE t(...
c1 INT,
c2 INT,
c3 DATETIME,
REDISTRIBUTED KEY (c1),
REDISTRIBUTED KEY (c2, c3));
上例中对表
t
建立了一个索引列为
c1
的重分布索引和一个索引列为
c2
与
c3
组合的重分布索引(是的,可以建多个索引实现多种分布,知识点,后面要考)。
CREATE TABLE t1(...
c1 INT,