学习Python首先我们要知道Python
变量保存的是值的引用
也可以说:
变量是对内存及其地址的抽象
Python:
一切变量都是对象
变量的存储,采用了
引用语义
的方式,存储的只是一个变量的值所在的内存地址,而不是这个变量的值本身
见下图
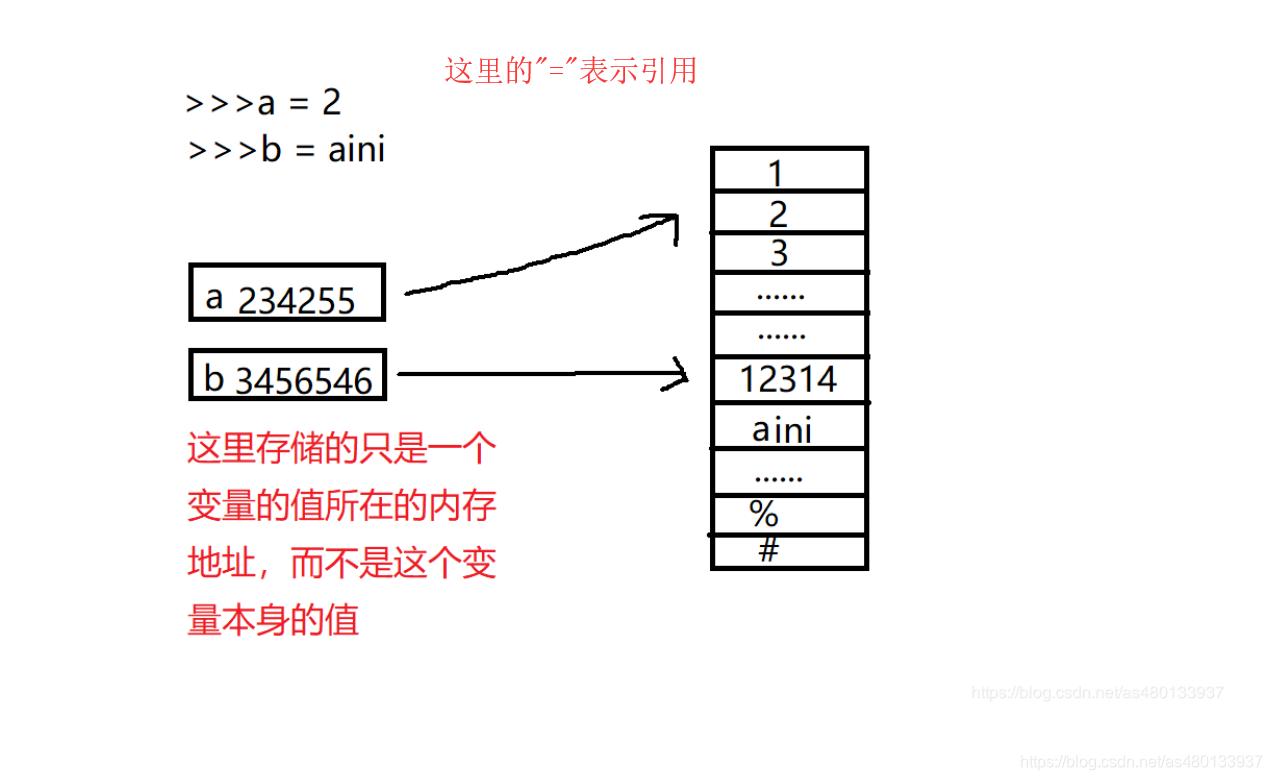
采用这种方式:
变量所需的存储空间大小一致,因为变量只是保存了一个引用。也被称为对象语义和指针语义。变量的每一次初始化,都开辟了一个新的空间,将新内容的地址赋值给变量
值语义:
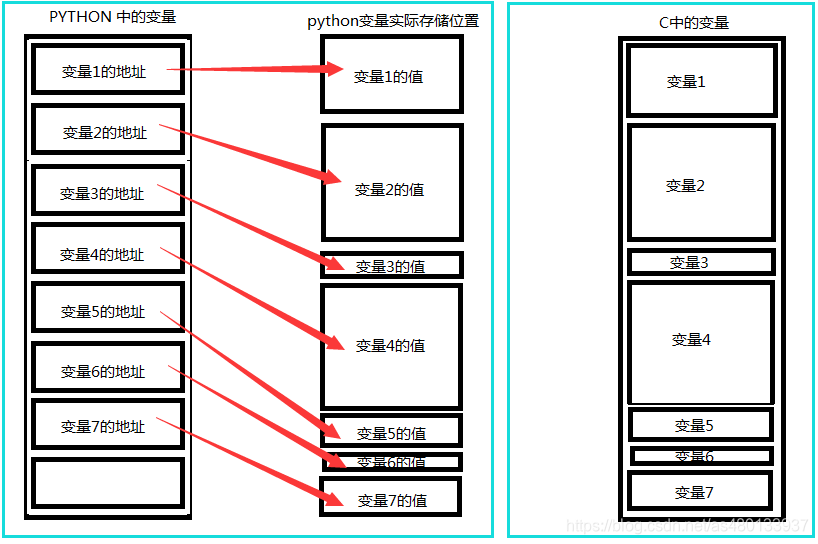
有些语言采用的不是这种方式,它们把变量的值直接保存在变量的存储区里,这种方式被我们称为值语义,例如C语言,采用这种存储方式,每一个变量在内存中所占的空间就要根据变量实际的大小而定,比如 c中 int 一般为2个字节 而char为一个字节
这张图帮助你更好理解⬇
*
预备知识一----id函数
id函数:你可以通过python的内置函数 id() 来查看对象的身份(identity),这个所谓的身份其实就是 对象 的
内存地址
就是
获取对象在内存中的地址
*
预备知识二----对于变量的赋值
我们把不同的值赋给变量时候,变量指向的地址发生变化,但是相同的值地址不发生变化。

?对于变量进行赋值时,每一次的赋值都会产生一个新的空间地址,将新内容的地址赋值给变量
*
预备知识三----复杂的数据类型,列表,元组,字典等修改与赋值
对于这些复杂数据类型,如果修改其中某一项元素的值,或者添加几个元素,
不会改变其本身的地址
,只会改变其内部元素的地址引用,
但是如果对其进行重新赋值操作时,就会给列表重新赋予一个地址,来覆盖之前的地址
这时列表地址会发生改变

这里我们不妨举个例子

上图一个是直接用
引用复制
“=”进行复制
另一个是用
分片复制
[:]进行复制
修改list1之后list2跟list1相同,但是list3却没发生变化
在我们创建list1的时候,Python已经了开辟list1的地址,并且分别指向了其中的值,而我们用“=”进行复制时,只是
会给现存的对象添加一个新的引用,并不会在内存中生成新的对象
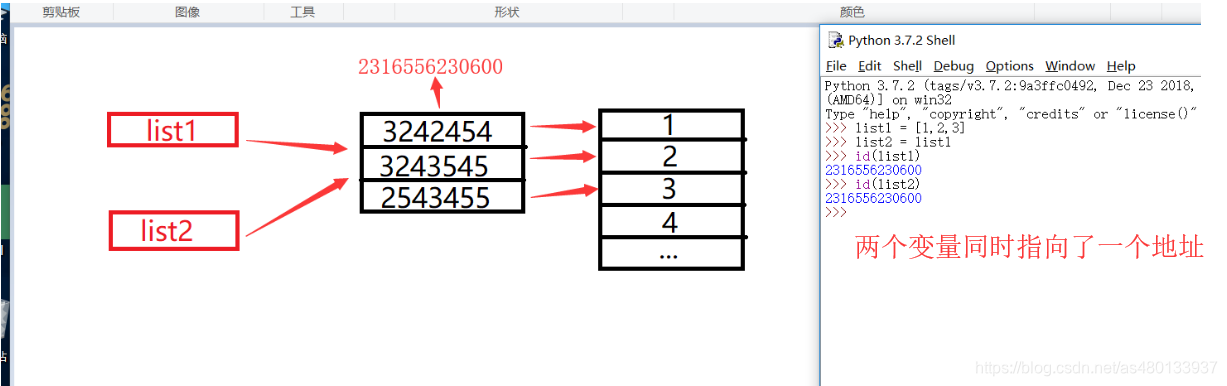
这里list1和list2指向的是同一个地址,
相当于创建快捷方式一样,多了一个指向该列表地址的引用
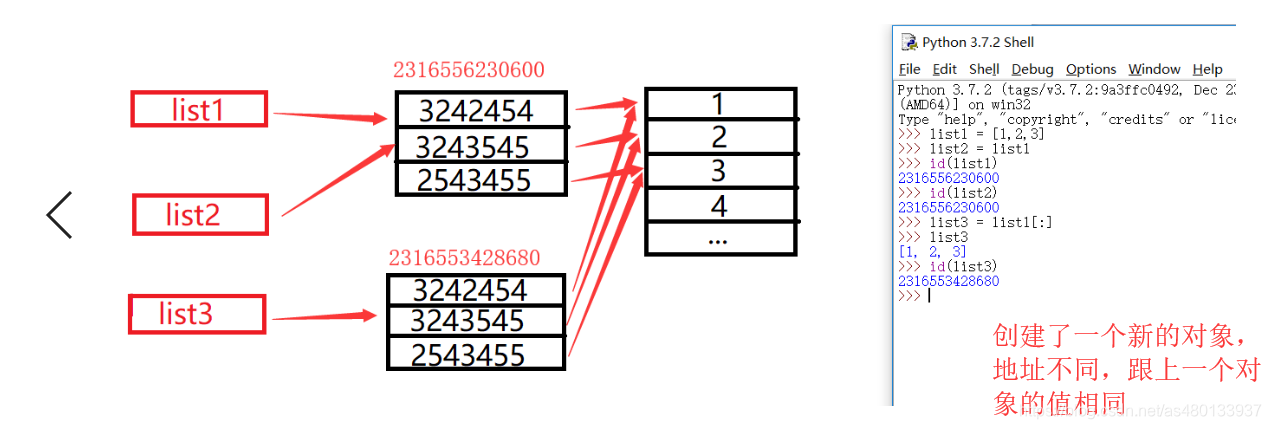
但是分片[:]复制是不同的,
他会创建一个新的对象
,list3跟list1和list2的值相同,但是地址是不同的,相当于
复制
了一份新的,
copy()函数和分片相同
通过上面我们可以知道:
Python支持
相同的值的不同对象,相当于内存中对于同值的对象保存了多份
但是上面只是对于可变数据类型适用,对于
不可变数据类型,内存中只能有一个相同值的对象
当然,具体也要看有没有产生新的对象,如果产生新的对象,则改变的那个列表会指向新的地址
def func(val1):
print('val1: {}, id: {}'.format(val1, id(val1)))
val2 = val1
print('val2: {}, id: {}'.format(val2, id(val2)))
val2.append(4)
print('val2: {}, id: {}'.format(val2, id(val2)))
val2 = val2 + [5]
print('val2: {}, id: {}'.format(val2, id(val2)))
a = [1, 2, 3]
print('a: {}, id: {}'.format(a, id(a)))
func(a)
print('a: {}, id: {}'.format(a, id(a)))
可变数据类型:列表list和字典dict
不可变数据类型:整型int、浮点型float、字符串型string和元组tuple
同学们会有疑问,可变数据类型于不可变数据类型差别在哪里呢?
这两者最本质的区别在于:,是指内存中的那块内容(值)是否可以被改变
(1)不可变数据类型,不允许变量的值发生变化,如果改变了变量的值,相当于是新建了一个对象,而对于相同的值的对象,在内存中则只有一个对象,就是不可变数据类型引用的地址的值不可改变
改变对象的值,其实是引用了不同的对象 ⬇

(2)可变数据类型,允许变量的值发生变化,即如果对变量进行append、+=等这种操作后,只是改变了变量的值,而不会新建一个对象,变量引用的对象的地址不会改变,只是对应地址的内容改变或者地址发生了扩充,所以对于相同的值的不同对象,会存在多份,即每个对象都有自己的地址
这样就可以理解预备知识三的变化了
copy.copy() 浅拷贝;
copy.deepcopy() 深拷贝
浅拷贝:不管多么复杂的数据结构,浅拷贝都只会copy一层。
深拷贝:深拷贝会完全复制原变量相关的所有数据,直到最后一层,在内存中生成一套完全一样的内容,,在这个过程中我们对这两个变量中的一个进行任意修改都不会影响其他变量
>>> import copy
>>> list1=[1,2,3]
>>> list2=[4,5,list1]
>>> list2
[4, 5, [1, 2, 3]]
>>>list3 = list2.copy()
>>>list4 = list2.deepcpoy()
>>>list1 = [6,6,6]
>>>list2
>>>[4, 5, [6, 6, 6]]
>>>list3
>>>[4, 5, [6, 6, 6]]
>>>list4
>>>[4, 5, [1, 2, 3]]
可以看到,list3只复制了list2列表的一层,在修改list1之后,list3也发生了变化
图片给出具体分析
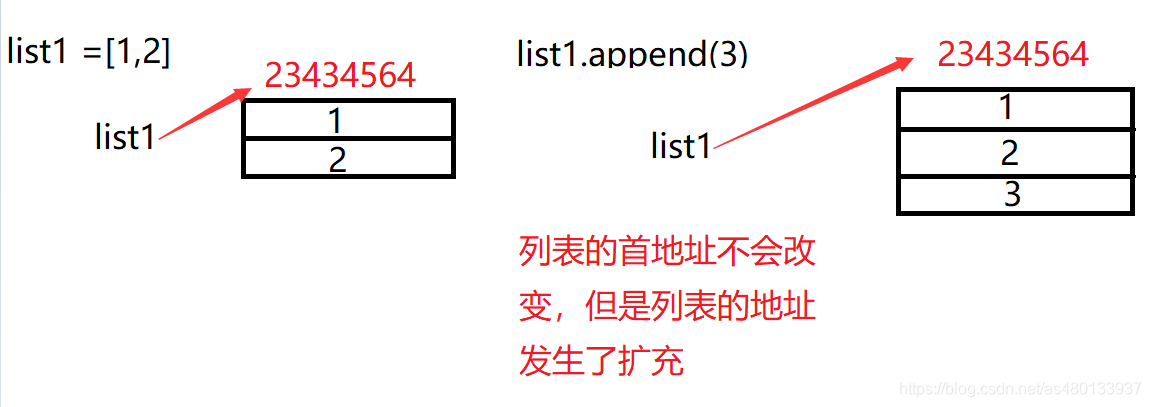
1浅拷贝
浅拷贝 只拷贝父对象(一层),不会拷贝对象的内部的可变子对象(多层)。,浅拷贝是指拷贝的只是原子对象元素的引用,换句话说,浅拷贝产生的对象(k1,k2,k3) 本身是新的,但是它的内容不是新的,只是对原子对象的一个引用。
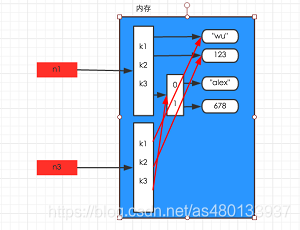
2深拷贝
深拷贝就是在内存中重新开辟一块空间,不管数据结构多么复杂,只要遇到可能发生改变的数据类型,就重新开辟一块内存空间把内容复制下来,直到最后一层
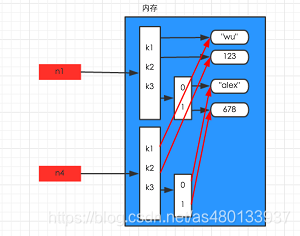
3引用复制(赋值拷贝)
“=”多了几个变量指向同一个地址,
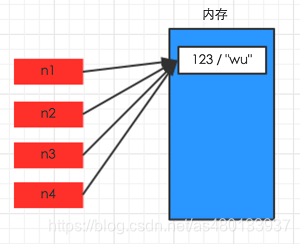
当我们使用下面的操作的时候,会产生浅拷贝的效果:
使用切片[:]操作
使用工厂函数(如list/dir/set)
使用copy模块中的copy()函数
可变对象为引用传递,不可变对象为值传递。(函数传值)
1,值传递: 简单来说 对于函数输入的参数对象,函数执行中首先生成对象的一个副本,并在执行过程中对副本进行操作。执行结束后对象不发生改变
即在堆栈中开辟了内存空间以存放由主调函数放进来的实参的值,从而成为了实参的一个副本。值传递的特点是被调函数对形式参数的任何操作都是作为局部变量进行,不会影响主调函数的实参变量的值。(被调函数新开辟内存空间存放的是实参的副本值)
值传递不会改变原来函数的值,
def Change(b):
b += 2 传递进来的为不可变对象,为值传递 相当于相同值的一个副本
print(id(b))
print (b)
return
a = 2
print(id(a))
Change(a)
print (a)
print(id(a))
140724617470832 a本来地址
140724617470896 值传递b的地址
4 在函数中为4
2 a本身还是2
140724617470832 a地址也没有改变
2,引用传递:当传递列表或者字典时,如果改变引用的值,就修改了原始的对象。(被调函数新开辟内存空间存放的是实参的地址)
def Change(str1):
str1[1] ="changed " 此处修改就是直接修改string的值
return
string = ['hello world',2,3]
print (string)
Change(string)
print (string)
输出为:

可以看到列表最后发生了变化
在函数调用中无法直接修改整个列表或字典的值 如果这样做,就是相当于也是相当于创建副本的值传递
这是网上很多帖子没有提到的
def Change(str1):
str1 =[6,7] //直接修改整个列表,也是相当于创建副本的值传递
return
string = ['hello world',2,3]
print (string)
Change(string)
print (string)
['hello world', 2, 3]
['hello world', 2, 3] string没有发生变化
整理不易,都看这儿了,点个赞再走呗!
不可变数据类型
不可变数据类型immutable:一般为基本数据类型,仅存储一个数值的数据类型,元组例外,如 int、long、float、string、元组,当创建一个变量时,变量内存储了指向值的地址,该地址处的值不会发生改变,当对变量重新赋值时,实际上是变量内的地址发生了改变。
例如创建a = 1,a内存储的地址指向1,令b = a,b中存储和a相同的地址。
当重新赋值a = 0,a内存储的地址发生变化指向0,而b的地址不变所以值依然为1:
可变数据类型
这篇文章主要是对python中的数据进行认识,对于很多初学者来讲,其实数据的认识是最重要的,也是最容易出错的。本文结合数据与内存形态讲解python中的数据,内容包括:
引用与对象
可变数据类型与不可变数据类型
引用传递与值传递
深拷贝与浅拷贝
(id函数:你可以通过python的内置函数 id() 来查看对象的身份(identity),这个所谓的身份其实就是 对象 的内存地址)
# python中定义一个变量,如:`name = 'the3times'`,在计算机底层会发生这样一件事:操作系统调用硬件,在内存中开辟一块空间,将值'the3times'存放在这块内存空间中;然后将变量名name与这块内存空间的地址绑定关联在一起;程序通过变量名name的调用来唯一访问值'the3times'。
# 这样的话,如果程序中有许多变量需要定义就会在内存中开辟大量的内存空间;
# 另外,我们知道内存是有限的,变量数量如果太多就会造成内存不足甚至内存溢出的风险。
# 从这个角度出
变量名具有的属性:本身的内存(存在栈中),本身的地址(不会显示),引用的值的地址(通过id取出来),引用的值(使用和输出时就调用),python里面的变量名的内存和值的内存是分开的,变量名相当于是对值的内存的引用,id()取出来的是值的内存的地址。当然变量名里存着它引用的值的内存的地址,当输出变量名时,会通过地址来找到引用的那块内存,并取出里面的值输出了,值具有的属性:本身的内存(存在堆中),本身的地址(通过id(变量)取出来),本身存的值。所以当改变变量a的值时,id()取出来的地址也不一样。
在高级语言中,变量是对内存及其地址的抽象。
对于python而言,python的一切变量都是对象,变量的存储,采用了引用语义的方式,存储的只是一个变量的值所在的内存地址,而不是这个变量的只本身。
引用语义:在python中,变量保存的是对象(值)的引用,我们称为引用语义。采用这种方式,变量所需的存储空间大小一致,因为变量只是保存了一个引用。也被称为对象语义和指针...
11、关于变量地址的变化:在对一个变量进行赋值的时候,如果变量的值前后发生了变化,那么此时变量所指向的地址也发生了变化,如果两个变量的数据类型相同而且值相等,那么两个变量指向同一个变量空间,一个变量的值一旦发生变化,计算机就会开辟的新的内存空间,把新值放进此,而此变量的地址变成了新值的地址。8、当list使用copy函数,得到的新的list与原来的list数值相同,但是地址不同,指向新的内存空间,修改原来的list不影响现在的list,直接使用新的list = 原来的list,指向的地址空间相同。

