

如何爬取豆瓣书评并做词云分析


一、词云分析
1、词云分析有什么用
“词云”这个概念由美国西北大学新闻学副教授、新媒体专业主任里奇·戈登(Rich Gordon)提出。
词云分析的由来:因为互联网时代信息大量涌入人们的视线,在信息爆炸的时代,如何快速的过滤无效信息,收集到有效信息,为此“词云分析”开始出现,通过对网络文本中出现频率较高的“关键词”予以视觉上的突出,使人可以迅速了解文章或者网页内容主旨。
通过书评的词云分析,也是为了方便大家快速了解一本书的主旨大意,再辅助了解目录、高排名书评等确认是否需要阅读,也可以迅速帮你了解一本书的主旨。
2、分析结果
抓取了豆瓣上1500+多位同学对于这本书的评价,而后分词得出的主题,基本上几个关键词突出了本书的主题


1、从第一眼来看,除了书名”被讨厌的勇气“外,这是一本关于人生、心理学的话题的书,最多的关键词在于”课题“、”课题分离“、”人生课题“、”人际关系“、”共同体“以及”生活方式“
2、 本书的世界观可以启迪人心,并帮助特定人群重拾勇气,将注意力从过去的创伤以及对未来的焦虑转移到自己可以把握的当下,改善自我价值过低的心态,因此,比起哲学或是心理学著作,这本书更像是一本具有启迪性的心灵鸡汤,而且比鸡汤更有营养。
3、其他类如”选择“、”价值“、”目的论“、”原因论“等都是大家讨论的关注点,爬虫词云分析有助于大家快速来了解都在讨论什么,核心词有哪些,便于大家关注重心,一眼扫过文本就可了解核心主旨。
二、如何爬取数据豆瓣书评
豆瓣读书的数据采集需要登录账号后才能看到,登录账号,点开目标网址: 被讨厌的勇气的书评 (1560) 。






豆瓣读书每本书下面会有三个部分来记录或分享观点:
- 短评:字数较短,一般用来记录读完一本书后的感受
- 书评:字数相对较长,几百上万字都有,属于对于这本书的整体评价
- 读书笔记:长短不一,或摘录书中的句子,或发表个人对某句话的感悟
考虑到本次做词云分析,我们主要选择了字数相对较多的“书评”。后续爬虫也是这部分的内容。
1、分析网址
豆瓣整体的架构设计都是简单的静态网页,只需通过页码参数就可以
urls=[]
pages=79 #可以根据页面数据来设定
for page in range(0,pages):
url = 'https://book.douban.com/subject/26369699/reviews?start={}'.format(page)
urls=urls.append(url)通过观察每一页网址的规律,可以推测出start的计算公式,用如上代码即可自动生成所有数据的地址。
2、爬取网页
我们提到,需要登录获取cookie并传递给请求头才能正常请求到数据,这里可以在开发者模式中的Request Headers中获取到cookies值。
def getHTML(url):
headers={'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114 Safari/537.36',
'Connection': 'keep-alive',
'Cookie': '', #你的cookies
'Referer': 'https://book.douban.com/subject/26369699/reviews',
request = urllib.request.Request(url,headers=headers)
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
return content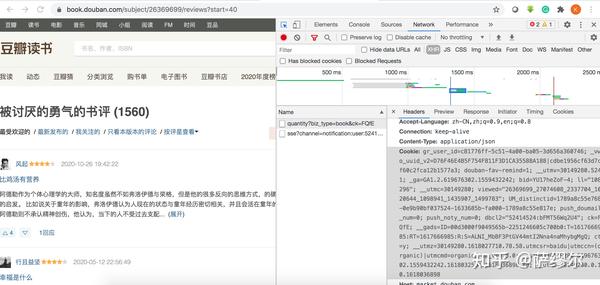

2.1 反爬虫
反爬虫是网站限制爬虫的一种策略,让爬虫在网站可接受的范围内爬取数据,不至于导致网站瘫痪无法运行。
A、身份识别
有些网站在识别出爬虫后,会拒绝爬虫的访问,如果用爬虫直接爬取它,则输出结果为空。这是由于服务器会通过请求头(requests headers)里的信息来判别访问者的身份。
查看网站请求头的方法:
- 在开发者工具中点击Network标签
- 点击第一个请求
- 找到Request Headers
- 找到user-agent字段
为了将爬虫伪装成浏览器,避免被服务器识别出来,需要在requests中定制请求头:定义一个字典,请求头字段作为键,字段内容作为值,传递给headers参数。大部分情况下,只需添加user-agent字段即可。
B、IP限制
当爬取大量数据时,由于访问过于频繁,可能会被限制IP。因此,常使用time.sleep()来降低访问的频率。
此外,也可以使用代理来解决IP限制的问题,以便快速地大规模爬取数据。和headers一样,定义一个字典,将http和https这两种协议作为键,对应的IP代理作为值,最后将整个字典作为proxies参数传递给requests.get()方法。
爬取大量数据时需要很多的IP进行切换,因此,需要建立一个IP代理池(列表),每次从中随机选择一个传给proxies参数。
3、基础数据
本文用Xpath做的解析,但我们发现直接去找爬取当前网页,发现评论内容不全,为此,我们找到评论的网页并逐一翻页提取评论的内容。
def spyderComment(data):
s=etree.HTML(data)
file=s.xpath('/html/body/div[3]/div[1]/div/div[1]/div[1]')
for div in file:
nickname=div.xpath('.//div/header/a[2]/text()')#书评作者昵称
star=div.xpath('.//div/header/span[1]/@title') #推荐级别
comment_time=div.xpath('.//div/header/span[2]/@content')#评价时间
href=div.xpath('.//div/div[1]/h2/a/@href') #评价链接
useful=div.xpath('//div/div/div[3]/a[1]/span/text()') #赞同支持人数
useless=div.xpath('//div/div/div[3]/a[2]/span/text()')#不赞同的人数
follow=div.xpath('//div/div/div[3]/a[3]/text()') #回复人数
for i in range(len(comment_time)):
nickname_list.append(nickname[i])
star_list.append(star[i])
comment_time_list.append(comment_time[i])
href_list.append(href[i])
useful_list.append(useful[i])
useless_list.append(useless[i])
follow_list.append(follow[i])
#数据清洗
for j in range(len(nickname_list)):
useful_list[j]=useful_list[j].strip('\n').strip(' ').strip('\n')
useless_list[j]=useless_list[j].strip('\n').strip(' ').strip('\n')
#comment_list[j]=comment_list[j].strip('\n').strip(' ').strip('\n')
#print("{}.{};{};{};{};{};{};{}\n".format(index,nickname_list[j],star_list[j],comment_time_list[j],href_list[j],useful_list[j],useless_list[j],follow_list[j]))
df=pd.DataFrame()
df['Nickname']=nickname_list
df['Star']=star_list
df['Comment_time']=comment_time_list
df['Href']=href_list
df['Useful']=useful_list
df['Useless']=useless_list
df['Follow']=follow_list
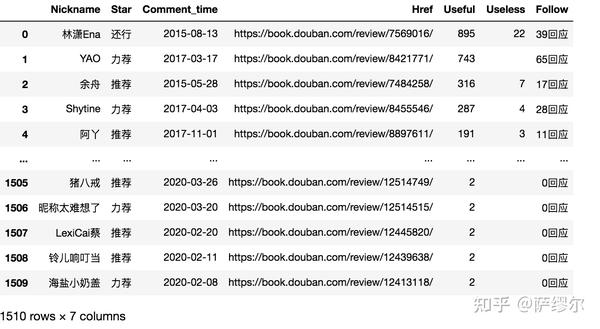
return df爬取后得到的书评相关的信息,并按照DataFrame的格式进行存取。

再根据网页的内容,我们逐一去爬取书评的内容,同样直接用Xpath提取页面信息即可。最后将爬取到的信息存储到一个Dataframe中,便于查看和分析。
index=0
for index in range(0,len(df_comment['Href']):
hf=df_comment['Href'][index]
print(index,hf)
index+=1
time.sleep(random.randint(0,3))
data = getHTML(hf)
s=etree.HTML(data)
comment=s.xpath('/html/body/div[3]/div[1]/div/div[1]/div[1]/div/div[1]/div[1]//text()')
print(comment)
comment_list.append(comment)
#df_comment['Comment']=comment_list
CommentDF=pd.DataFrame()
CommentDF['Comment']=comment_list4、词云分析
最后,就可以生成词云了,词云生成有几个不同的库,个人使用的是stylecloud,也可以考虑wordcloud,根据你的习惯,形成一个固定的模板即可。到此,全部的结果也就结束啦。
#ciyun分析
import stylecloud
import numpy as np
from PIL import Image
import jieba
import jieba.analyse
import pandas as pd
def ciYun(data,addWords,stopWords):
print('\n正在作图...')
comment_data = []
for item in data:
if pd.isnull(item) == False:
comment_data.append(item)
# 添加自定义词典
for addWord in addWords:
jieba.add_word(addWord)
comment_after_split = jieba.cut(str(comment_data), cut_all=False)
words = ' '.join(comment_after_split)
bg=np.array(Image.open('/Users/……/Downloads/被讨厌的勇气.jpeg'))#省略号除填写你的存储地址
# mask=bg
stylecloud.gen_stylecloud(text=words,
font_path="/System/Library/Fonts/STHeiti Light.ttc",
output_name='被讨厌的勇气.jpeg',
palette='cartocolors.diverging.TealRose_2', # 选取配色方案
background_color= 'black',
icon_name='fas fa-grin-beam',#选取底图
gradient='horizontal' ,
size=500,
custom_stopwords=stopWords,
print('词云已生成~')
if __name__ == "__main__":
data=list(comment_list['Comment'])
addWords = ['勇气','讨厌']
# 添加本地停用词文件
stoptxt = pd.read_table(r'/Users/samuelzhan/Downloads/cn_stopwords.txt',encoding='utf-8',header=None)
stoptxt.drop_duplicates(inplace=True)
stopWords = stoptxt[0].to_list()