|
|
|


为什么m1能用3.2ghz的频率在单核性能打赢近5Ghz的锐龙7 5800x?
关注者
168
被浏览
320,896
57 个回答


虽然略胜,但打赢真说不上,各有胜负而已
这里主要使用Anandtech的几个单线程评测结果 [1] :
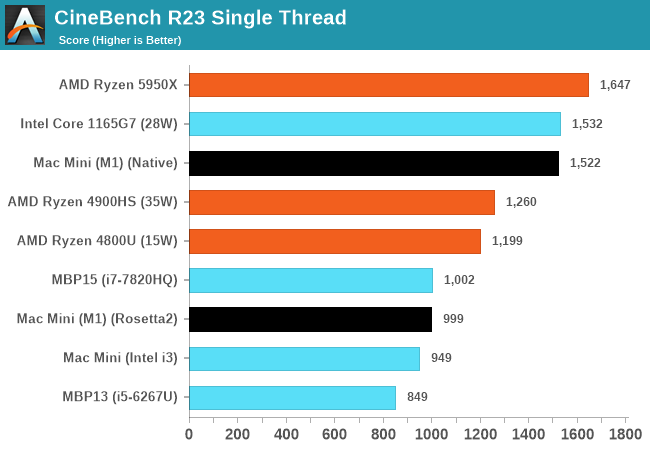
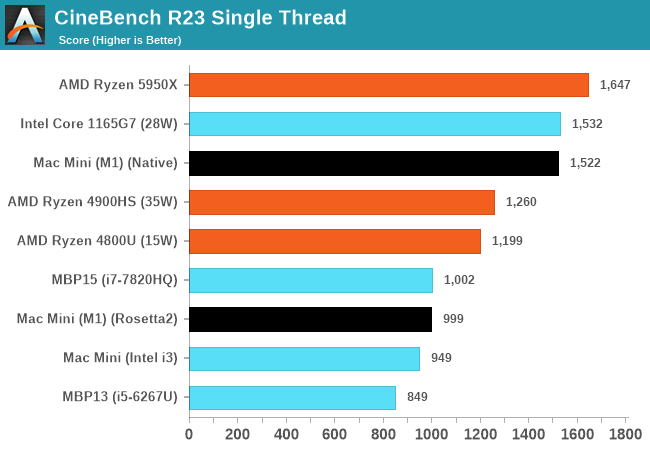
Geekbench单线程,A社就给了个总分,还是要看看子项的,反正GB官网一大堆成绩,随便挑两个对比就是了 [2] 。不过要注意找个黑苹果的,也就是CPU是5800X,操作系统是macOS的。要是找了Win或者Linux平台的话,5800X的得分要高一些,尽可能排除操作系统影响吧。
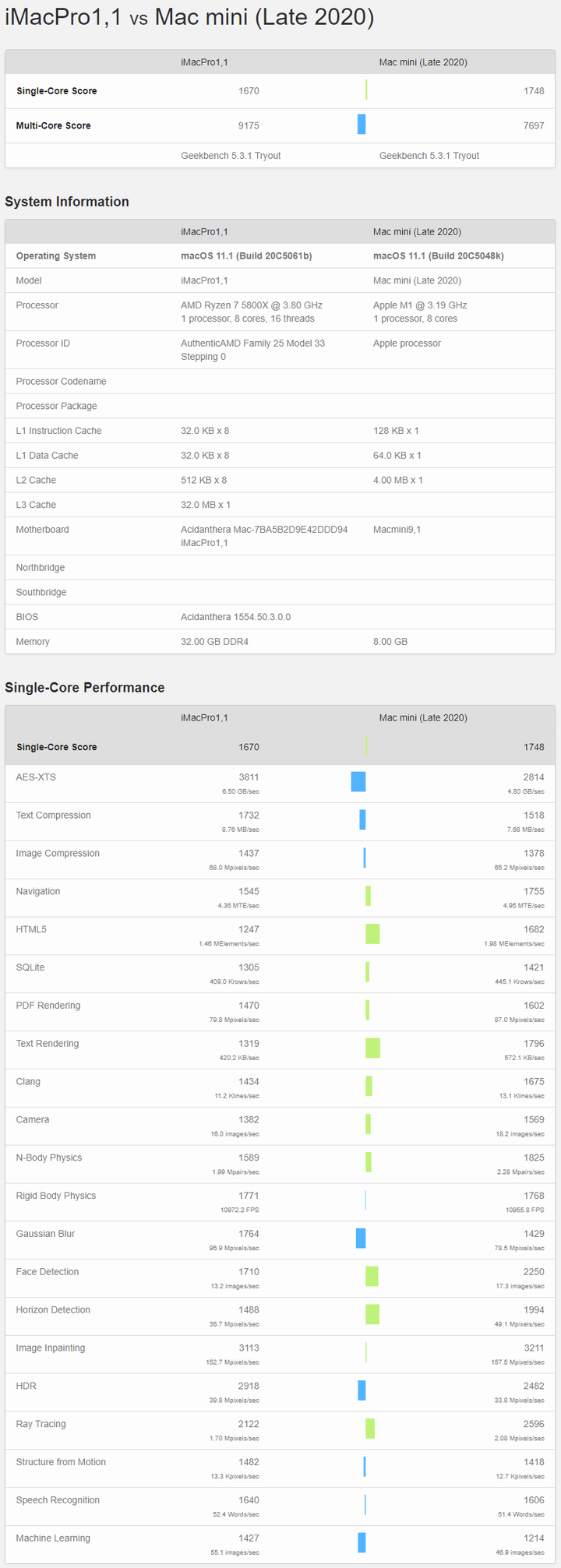
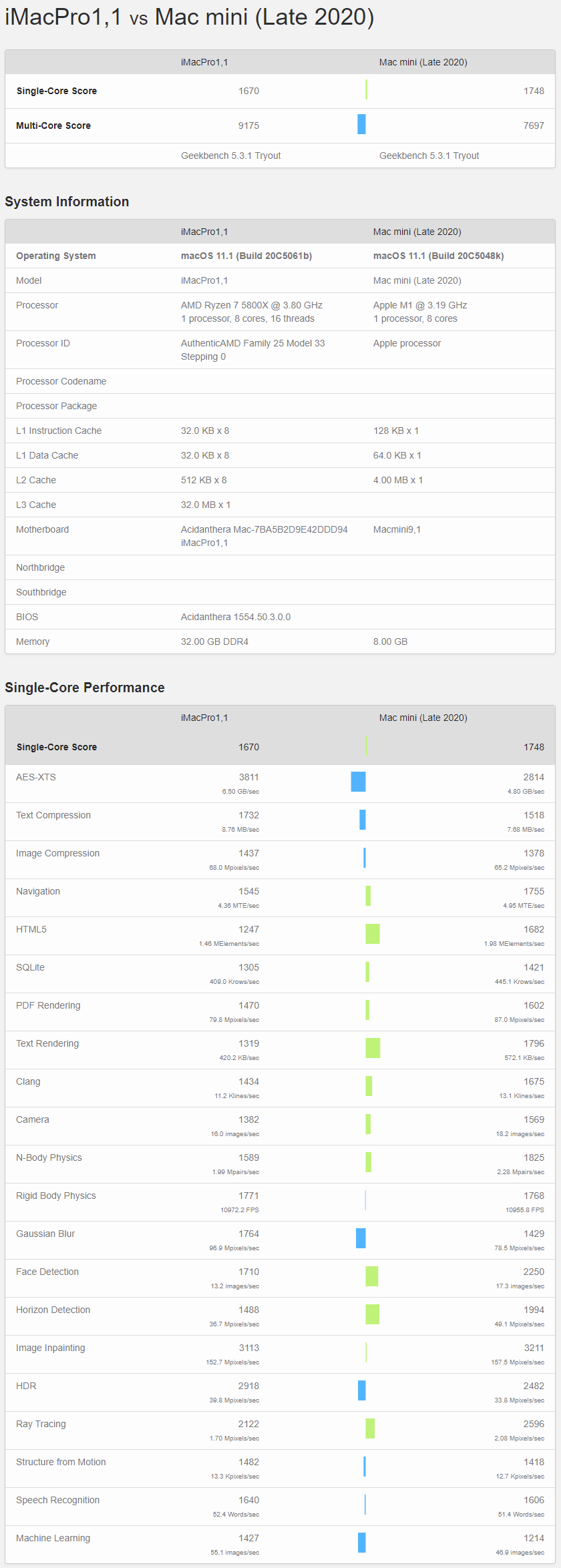
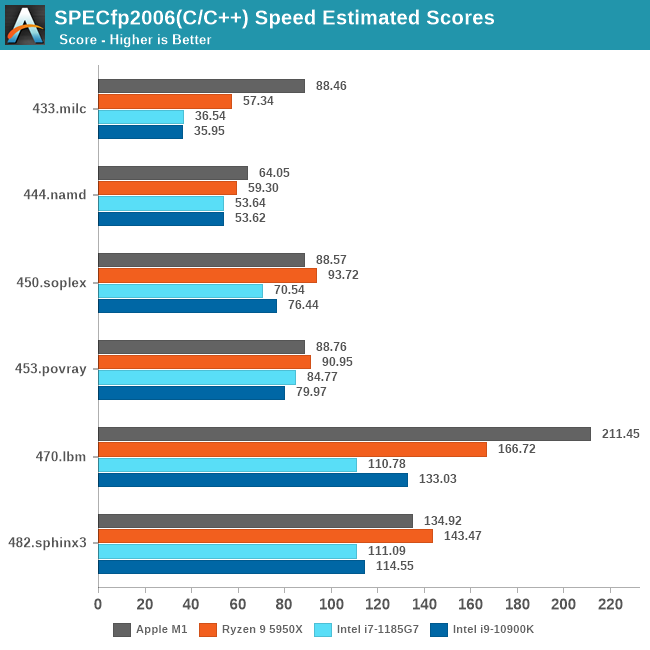
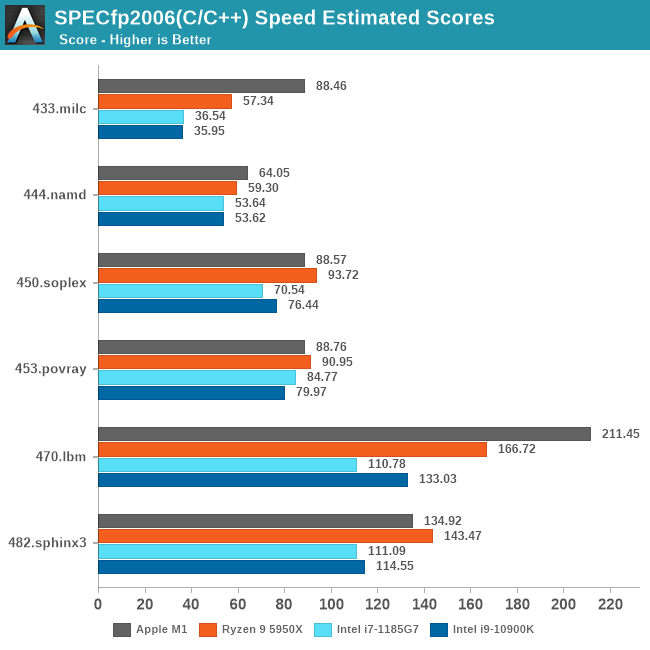
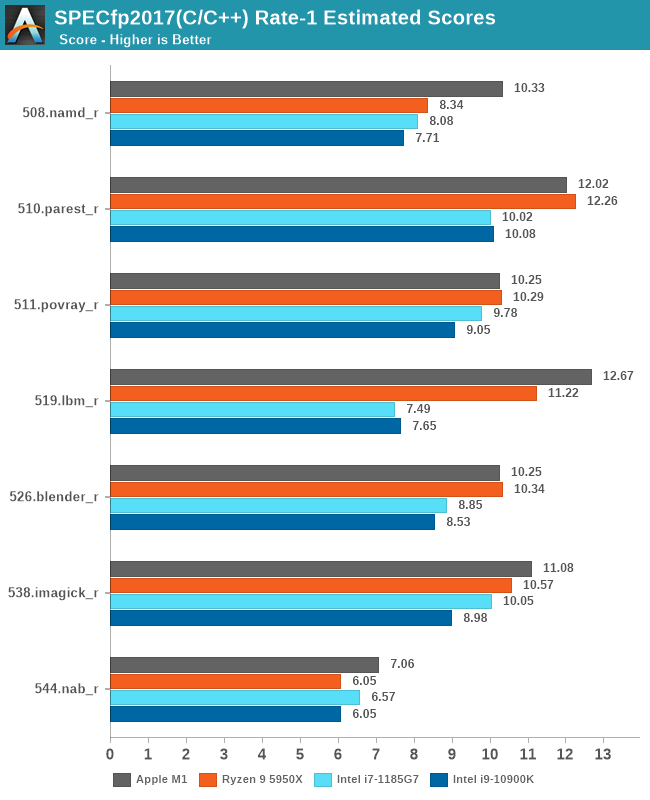
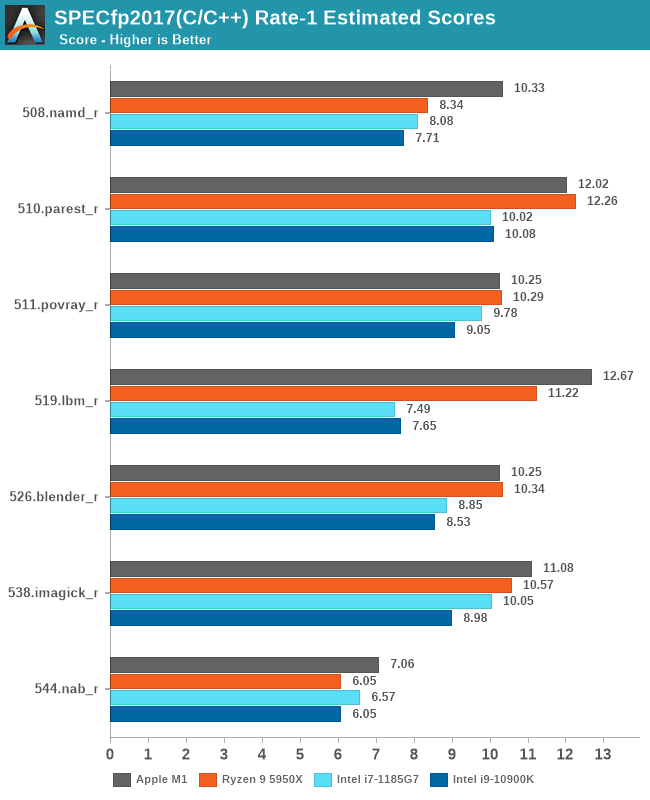
全部成绩汇总一下:
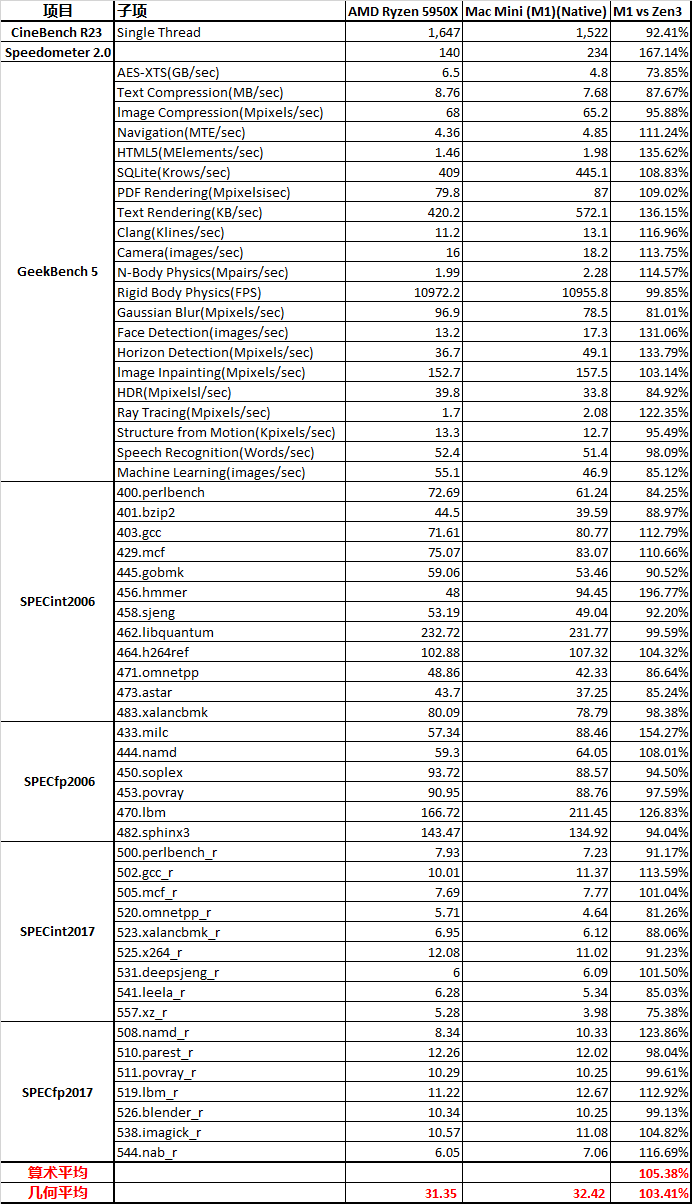
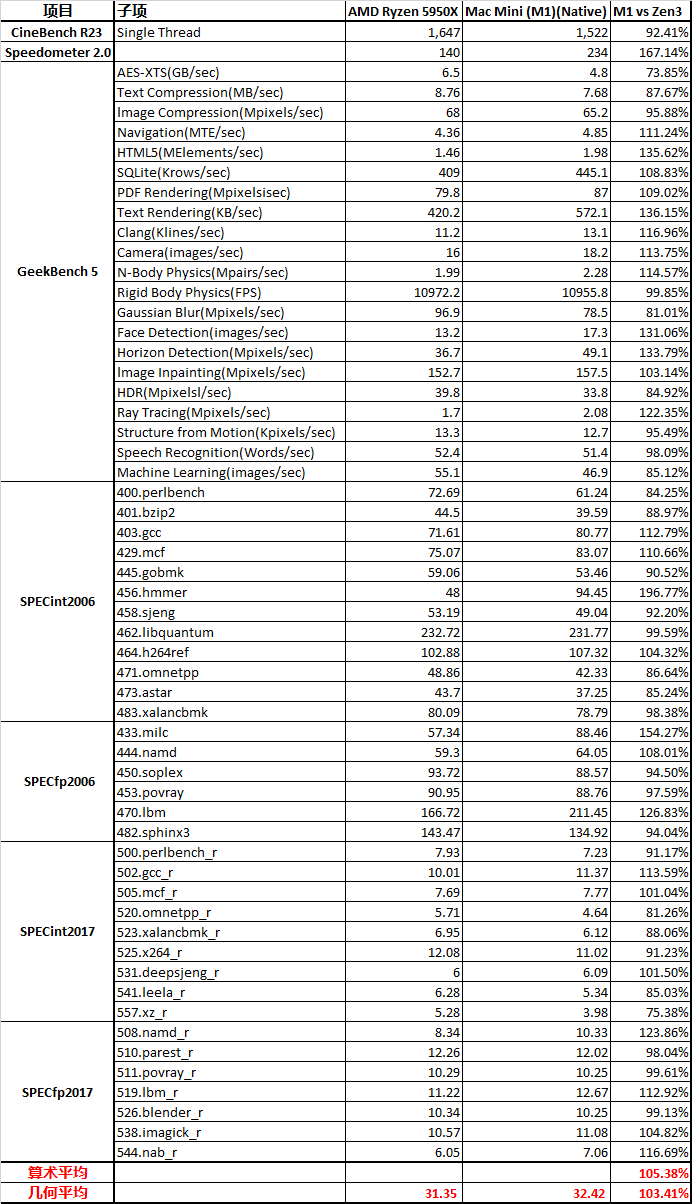
从这些测试项目综合来看,M1的确是稍微强于5950X的,但你要说真赢了,就算是归一后算术平均下来,也就胜出5%多点。
而且,按照Anandtech所说:
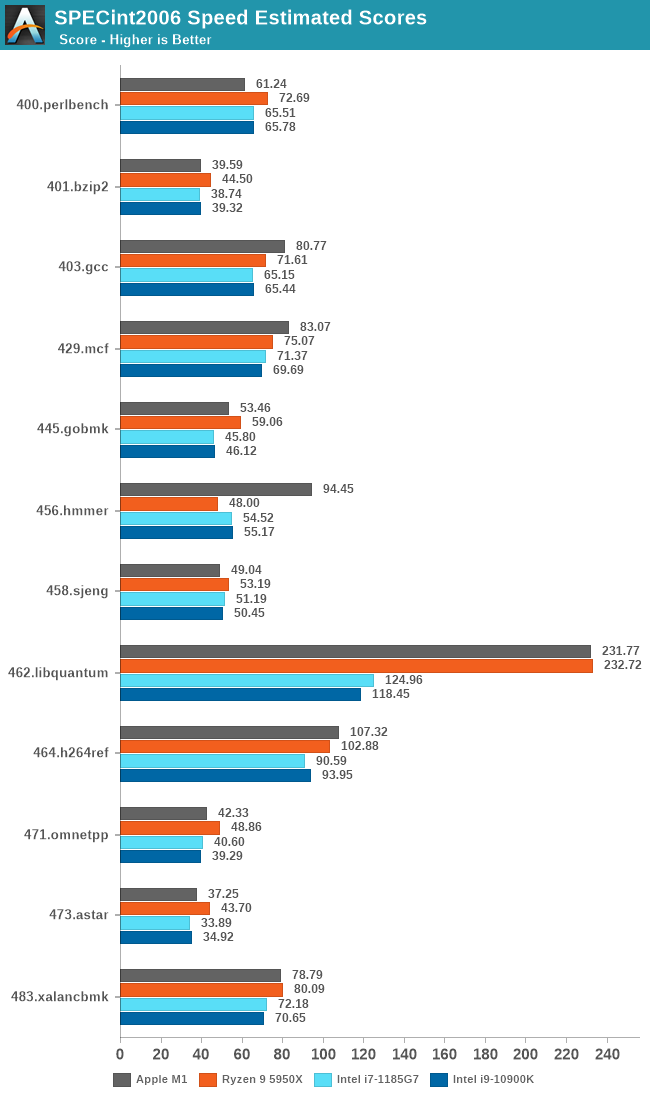
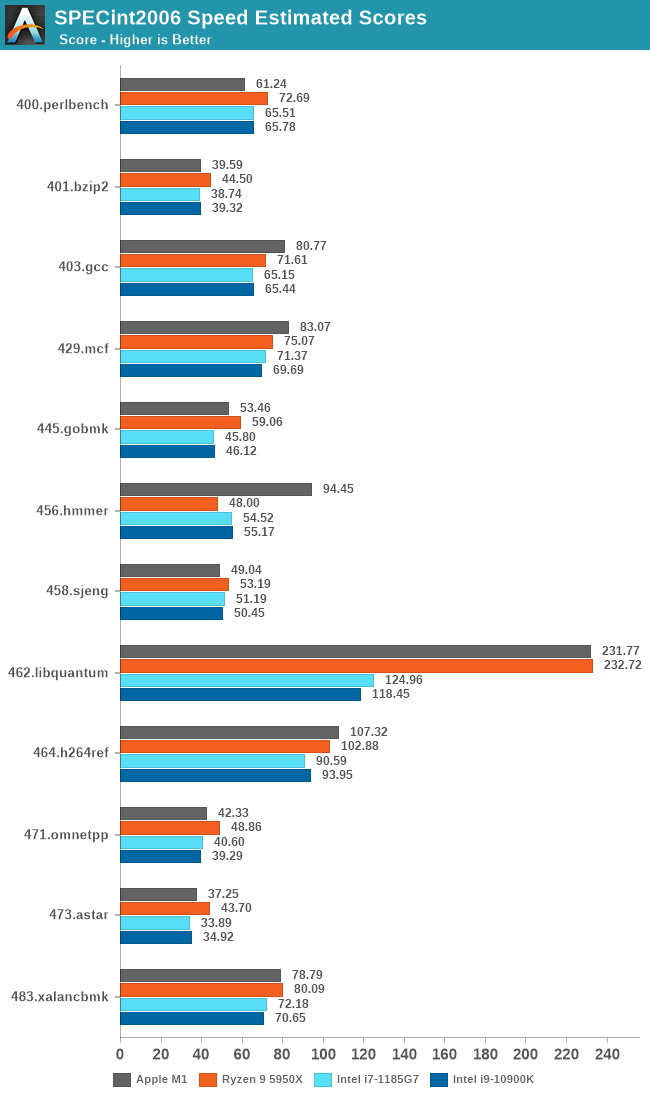
Since our A14 results, we’ve been able to track down Apple’s compiler setting which increases the 456.hmmer by such a dramatic amount – Apple defaults the “-mllvm -enable-loop-distribute=true” in their newest compiler toolchain whilst it needs to be enabled on third-party LLVM compilers. A 5950X with the flag enabled increases its score to 91.64, but also while seeing some regressions in other tests. We haven’t had time to re-test further platforms.
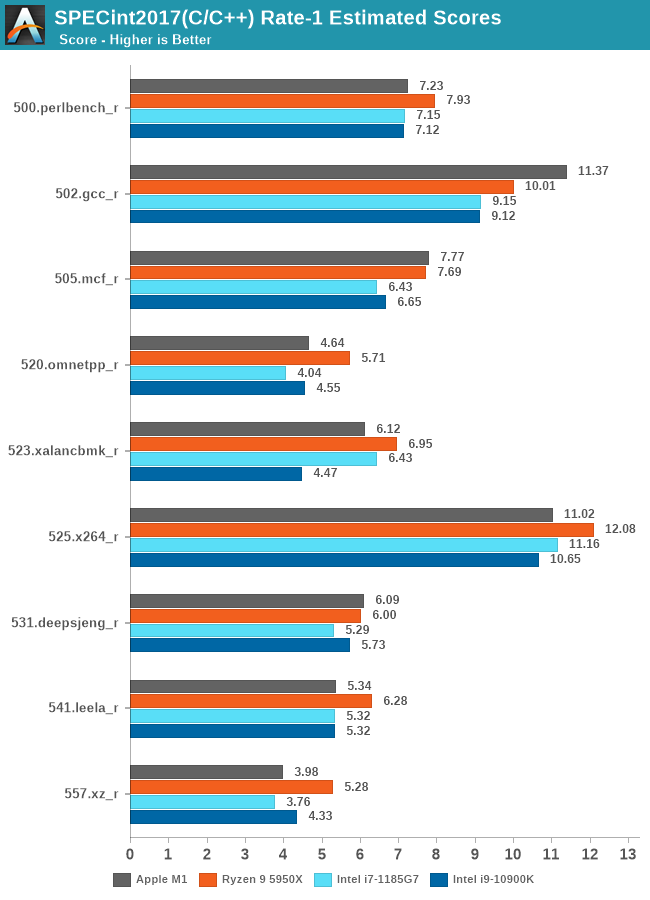
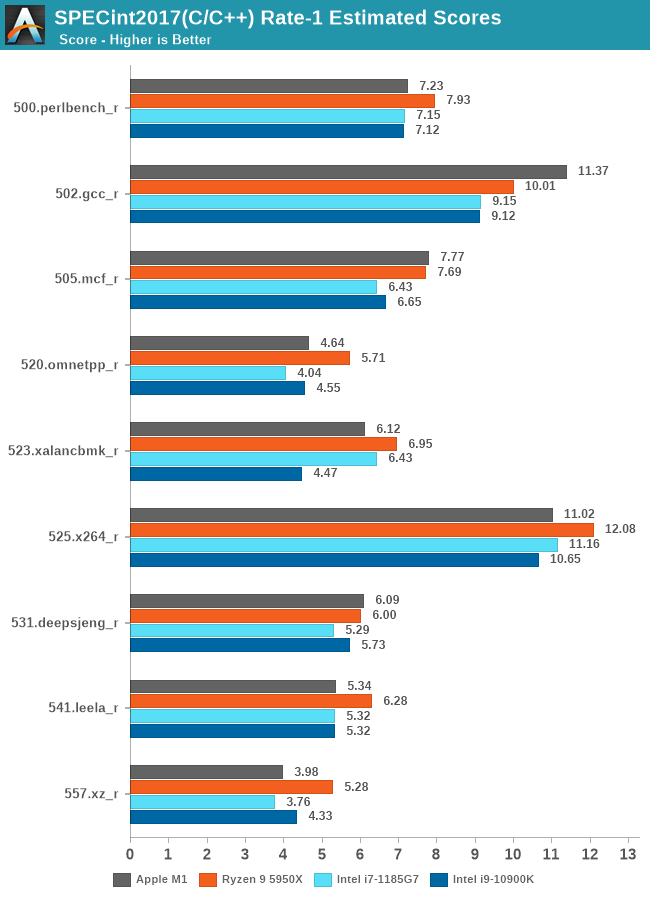
5950X的测试软件环境和M1还是不同的,包括SPEC的编译参数都未能一致,SPECint2006的456.hmmer子项如果用A社追踪到的Apple的默认编译参数重新编译再跑一遍,成绩可以从48分提升到91.64,虽然还是略输于M1,而且用这个参数编译的其它子项成绩会有所倒退。但如果用这个成绩重新计算的话,归一后的算数平均103.74%,几何平均102.24%——我其实很期待A社能够搞个黑苹果重新再测一遍——但很有可能这样还是不够公平,毕竟苹果从来没有为AMD优化过操作系统和编译器。
虽然上面A社成绩对比的Zen3是5950X,不过单核性能和5800X几乎一样的 [3] 。
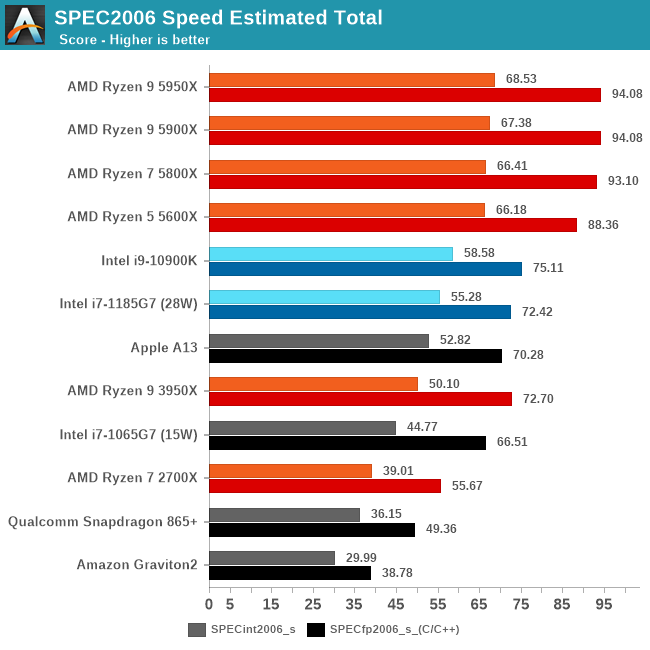
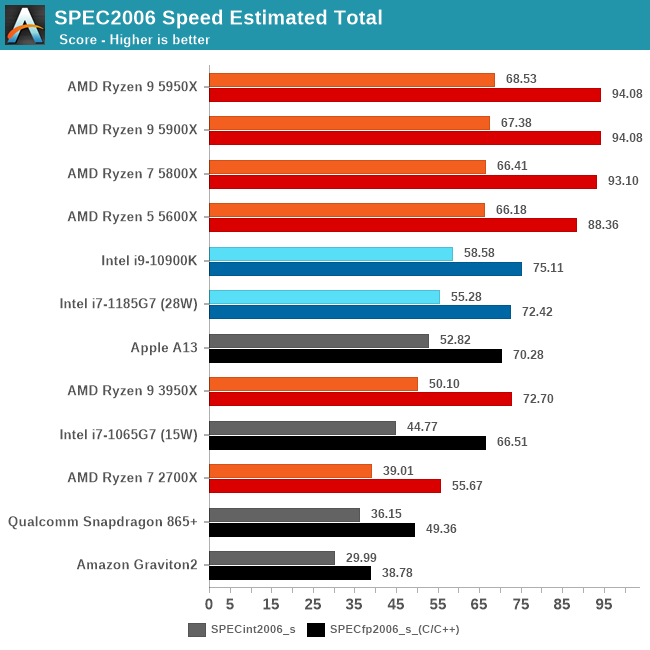
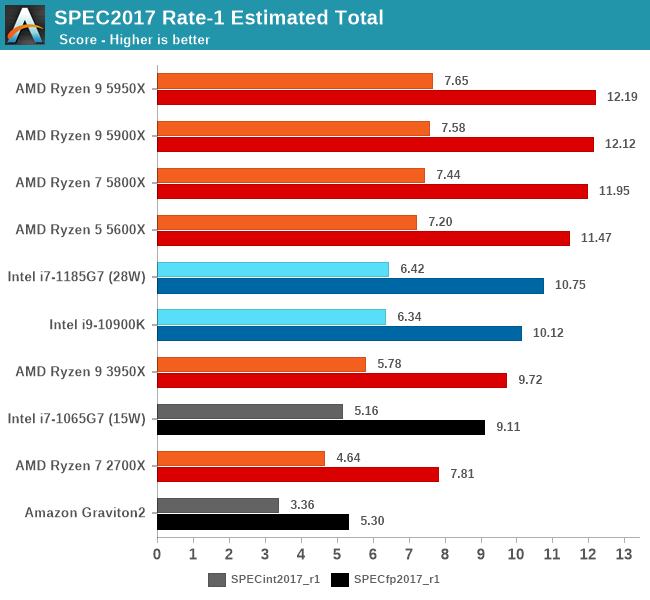
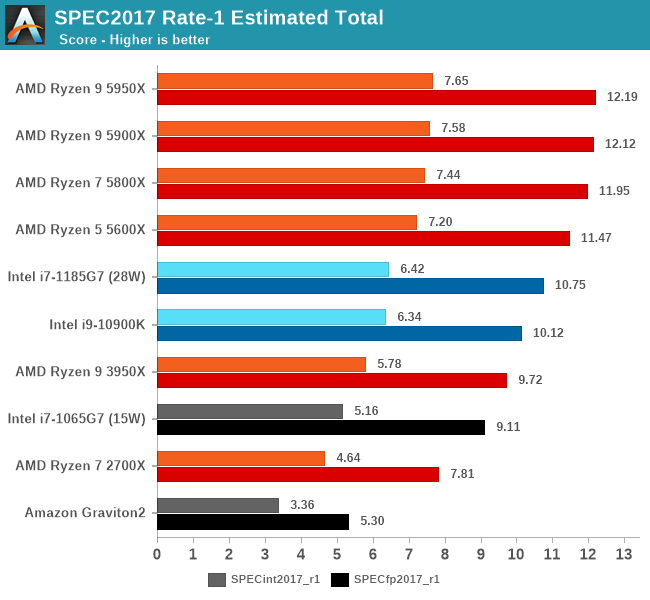
从成绩来看,两个版本的SPEC,M1都是整数略输,浮点略胜。这是因为M1是四个128bit的NEON单元,而Zen3是两个256bit AVX单元,理论上同频性能一致,但M1还是比Zen3灵活很多,更容易发挥出性能,毕竟直到今天,256bit的AVX指令的普及率并不算高,单靠编译器优化很难完全发挥出AVX单元的性能。另外,HTML相关、程序编译的子项,M1也很有优势,这个我猜测是M1的大容量L1I和超宽ROB(应该还有更大容量的μOP Cache)更有利于格式文本处理中的正则表达式匹配算法。
Apple M1是怎么以3.2 GHz的低频达成这么强的性能的?
关于对M1的分析,之前在另一个问题详细分(xia)析(cai)过,这里就不重复了:
@salasin 你把我拉黑了?我还觉得你回答下的评论只是观念不同而已,言辞激烈点也不止于拉黑吧?不过还是多说两句,说完就算了。
既然是靠这个吃饭的,难道不是应该提前考虑业界发展,未雨绸缪么?明知道世道要变,还等到事到临头才去应对?回头刚买了一堆x86设备,发现自己要跑的应用在mac上更省电性能更好,换也不是不换也不是很好玩?
说实话,真要说高性能计算吧,Intel还真可以说一句“你大爷还是你大爷”,不管是linpack还是例如3dpm、yCruncher这类应用,只要数据结构适合SIMD,avx512加上mesh的SKL-X/SP,哪怕工艺落后一代,架构还是四五年前的,Zen2核心数量两倍甚至四倍也要输,按照Zen3的表现,估计也赢不了。随手找两个评测:
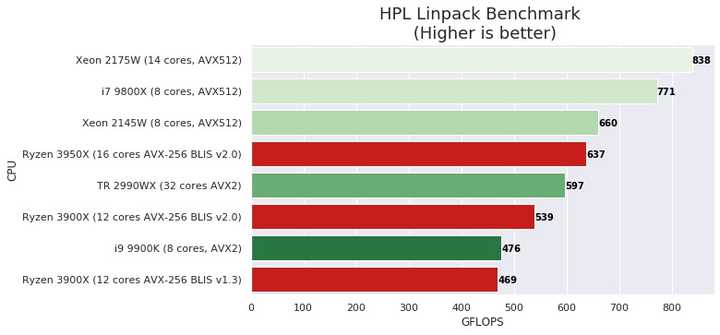
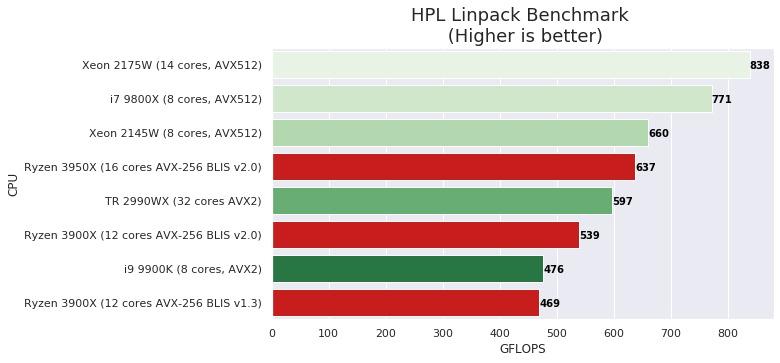


和HPC应用相比,3D渲染并行度极其良好,几乎是只看线程数量×单线程性能,不在乎Interconnect性能,连Memory Bond都很少碰到。说实话,在ARM的单核性能相当接近x86的今天,更低的功耗意味着同样的功耗限制下,可以容纳更多核心。除了应用兼容性外,可以预见到一旦高功耗场景的ARM生态普及,x86已经没有任何优势。偏偏3D渲染是极其性能渴求的应用,为了性能,兼容性是可以放弃的。这也是M1出来后,多家3D建模软件开发商都表达出适配M1的意愿的原因。
这种情况下,如果我像你一样吃3D渲染这行饭,现在我肯定去找软件开发商打探他们的后续计划,并且去做相应的准备,保证如果他们计划适配ARM架构的mac的话,制定相应的设备更新计划,保证只要开发商适配mac后可以第一时间切换。甚至现在用的软件没有适配计划,只要其它软件提供商有适配计划而且有证据证明性能更好,我会让设计师提前去适应新的软件。
参考
- ^ Anandtech:The 2020 Mac Mini Unleashed: Putting Apple Silicon M1 To The Test https://www.anandtech.com/show/16252/mac-mini-apple-m1-tested
- ^ Geekbench:iMacPro1,1 vs Mac mini (Late 2020) - Geekbench Browser https://browser.geekbench.com/v5/cpu/compare/5413151?baseline=4931678
- ^ Anandtech:AMD Zen 3 Ryzen Deep Dive Review: 5950X, 5900X, 5800X and 5600X Tested https://www.anandtech.com/show/16214/amd-zen-3-ryzen-deep-dive-review-5950x-5900x-5800x-and-5700x-tested/9

Geekbench5不想多说,这个玩意在Parallel虚拟机里虚拟win10 on ARM64,运行Geekbench5 for AARch64。性能依然还是损失13%到15%。我在KVM里测这个项目就没见过虚拟机有什么性能损失。
说一下R23吧。R23基于intel Embree光线追踪库,根据Vtune的测试结论,Cinebench R23单线程在Tiger Lake微架构的瓶颈很大一部分在DTLB。也就是说DTLB的缺失限制了前端向后端提供数据流,导致后端空置,引起大幅度的超线程性能提升。也就是说,对于Zen3/Tiger lake这样的处理器,后端执行单元 or ROB or 别的什么你们看微架构图企图看出来的“规模”(我知道很多人喜欢拿前端译码数量和执行单元之类的东西说事,把CPU当成GPU?),对R23是完全没有瓶颈的,如果前端能完全塞满后端,超线程怎么会有这么大的提升?
DTLB是什么?是一种在CPU里保存页表的缓存,页表是干什么的。每个进程其实都有一个页表,它记录了从虚拟地址转换为物理地址所需要的信息。CPU完成了指令译码,要去取数据了,CPU的AGU产生了一个虚拟地址。MMU要把它转换为物理地址,需要查看虚拟地址与物理地址的对应关系,就是要从这个进程的页表里找,可是页表在内存里啊,MMU要先去内存里找到页表,把虚拟地址转换为物理地址,然后根据物理地址从内存取数据,也就是说,取数据要经过2次内存访问,对于现在的CPU来说,访问内存造成的周期损失是极度昂贵的。这仅仅只是对于比较小的页表,对于比较大的页表。甚至要设置多级页表,那访问内存的数量可就不止2次了。这么多访问内存的次数,那已经译码完的指令就得呆在保留站里,等待数百个时钟周期,才能等到它的数据。为了减少内存访问,人们就发明了用于页表的缓存,也就是TLB,DTLB就是专门用于程序的数据段部分内存的TLB。
但是受限于硬件,DTLB的容量是有限的,如果大量发生DTLB miss,那么访问数据就要2次,甚至更多次的内存访问,于是译码完的指令就只能呆在保留站,不能发射。直接导致流水线后端空转,很明显,译码宽度和后端执行单元数量帮不上任何忙。
目前主流的x86系统用的是4kB大小的分页,而M1芯片,iOS用的是16kB大小的分页,页面越大,同样内存占用下所需要的页表项越少。也就越难发生TLB Miss,就这一点来说,M1 or iOS具有极大的优势。
对于DTLB瓶颈,这个包括英特尔自己,在Embree的官方文档里都提到了。
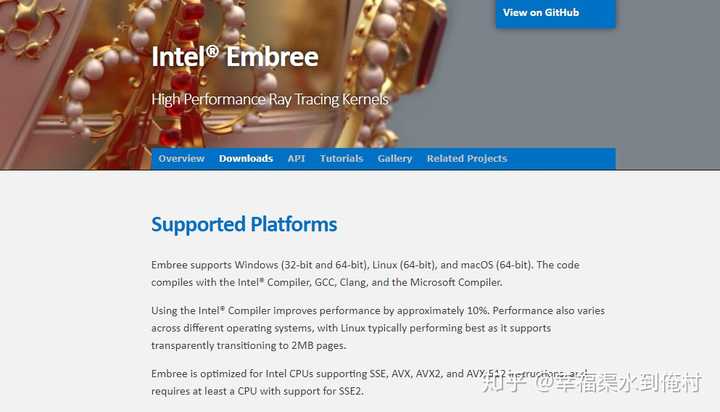
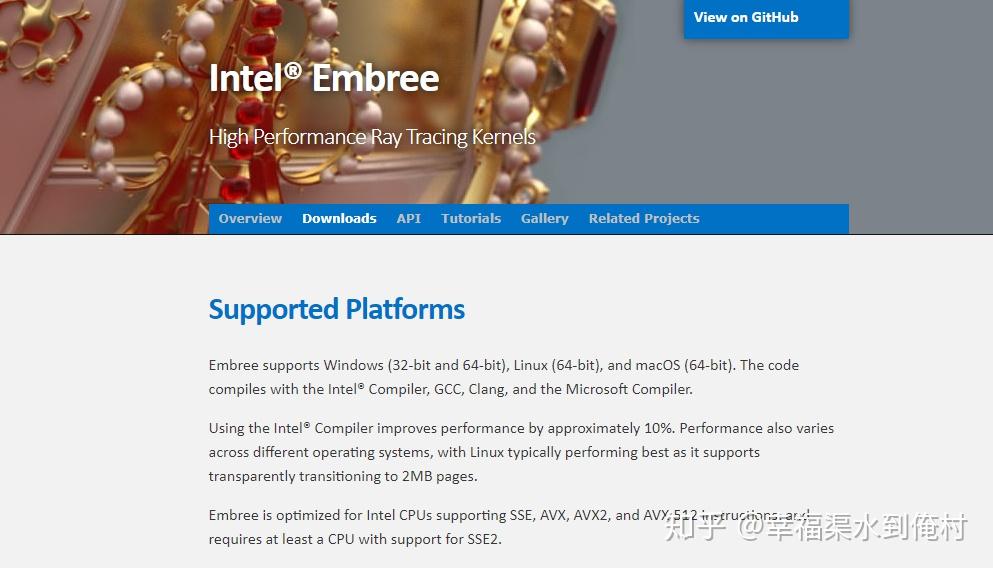
因为Linux支持“透明大页”,能动态的为程序分配2MB的内存页,对于降低TLB瓶颈非常有效。
我还找了Phoronix测试的Emree3.9.0的数据。如下
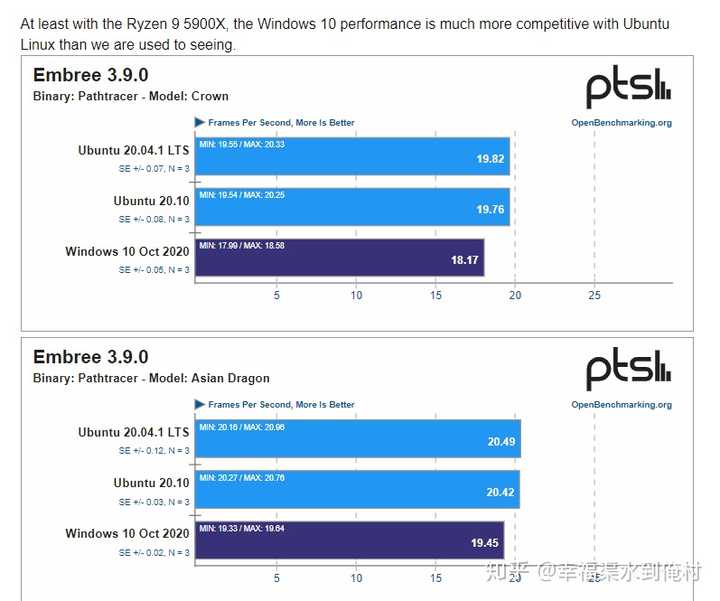
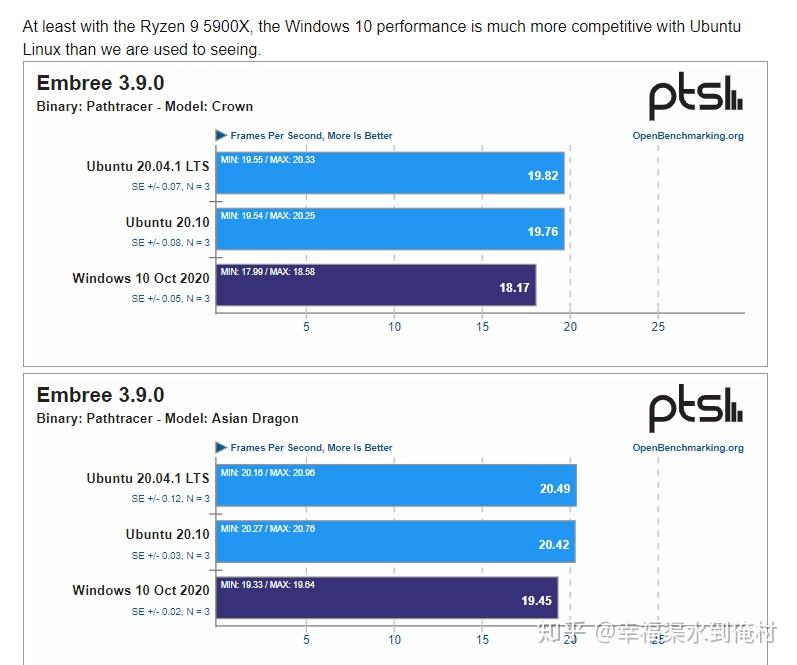
但是我不清楚Phoronix是否开启了透明大页,毕竟不是所有Linux发行版都默认打开这个设置的。就当一个不同系统下Embree的跑分差异吧,权当验证intel的说法。事实上,Phoronix测试的所有渲染项目里,不仅是Embree,其他的渲染项目,Windows10一般都会落后很多。不太清楚具体原因。
另外。众所周知,R23修改了SIMD指令的数据宽度,在新的Embree文档里,有这样的说明。


对于只使用SSE的负载而言,设置SIMD128避免CPU降频,但R23并不是SSE,而是针对AVX2优化的,这种做法与官方的推荐是相反的。非常奇特。不知道该如何评价。
最后,intel指出,Embree使用intel编译器可以获得额外10%的性能提升,那么,对于宣布使用新的编译器的R23,它使用了什么去编译的Embree呢?R20是intel编译器编译的。