

pandas和sql

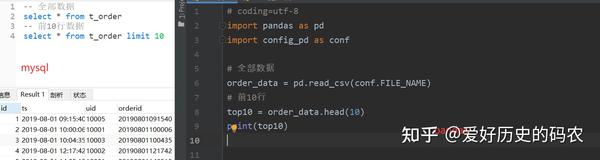
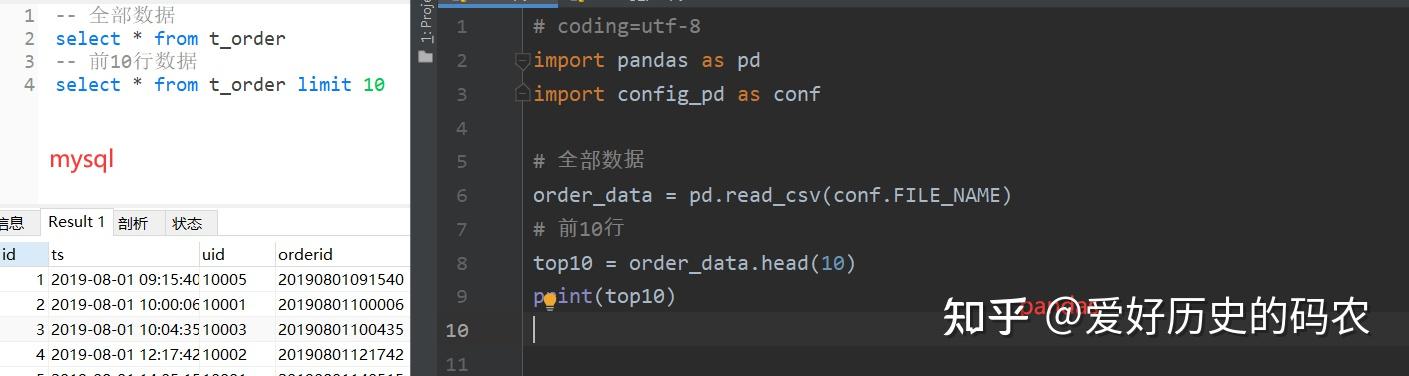
1、查看全部数据或者前n行数据
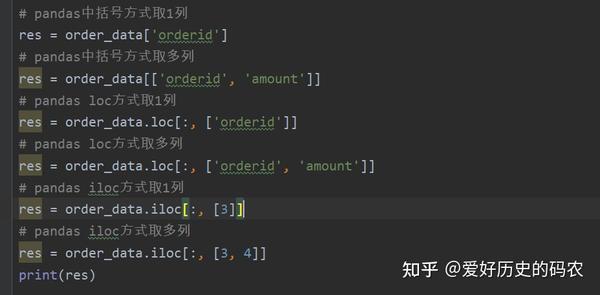
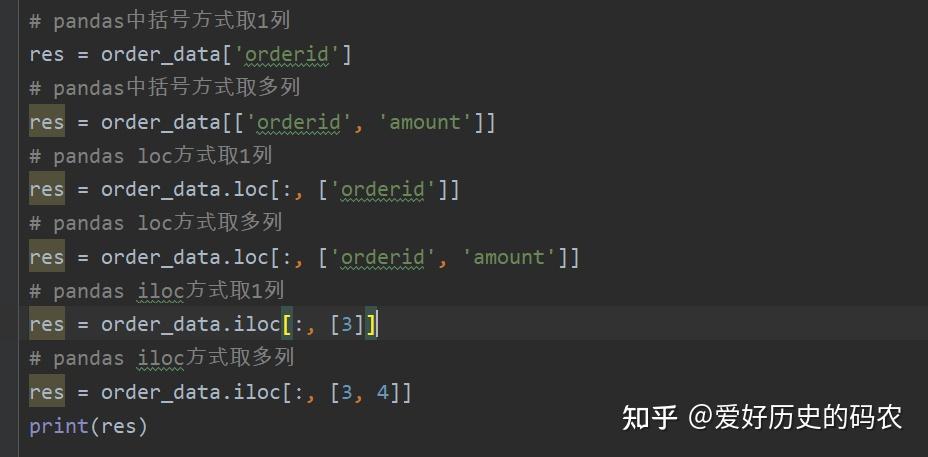
2、查询特定列的数据
在pandas里可以使用中括号或者loc,iloc等多种方式进行列选择,可以选择一列或多列。loc方式可以直接写列名,iloc方式需要指定索引,即第几列。
SQL里只需写相应的列名即可。


3、查询特定列去重后的数据
pandas里有unique方法。
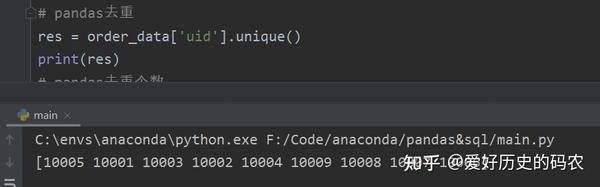
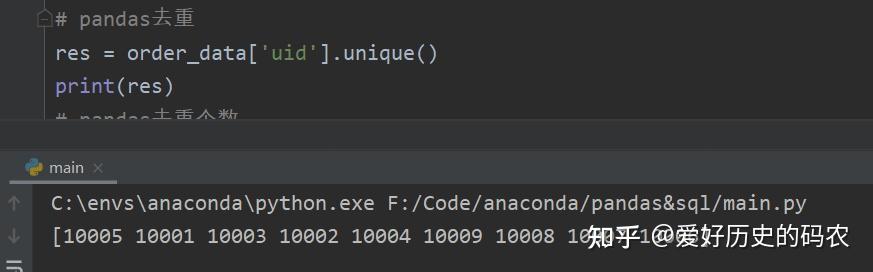
SQL里有distinct关键字。
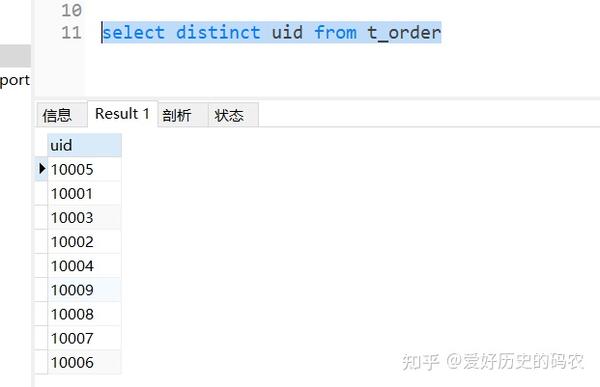
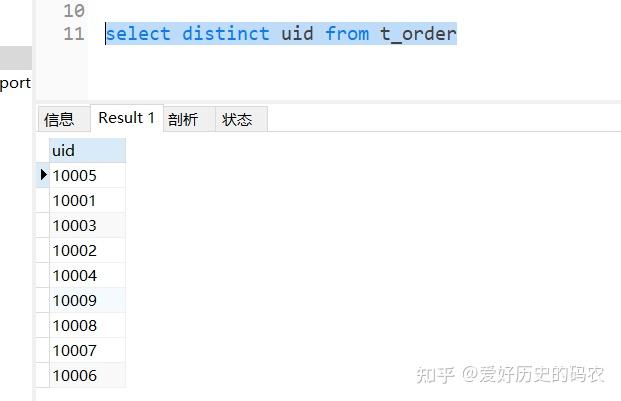
pandas用nunique()方法实现,统计个数
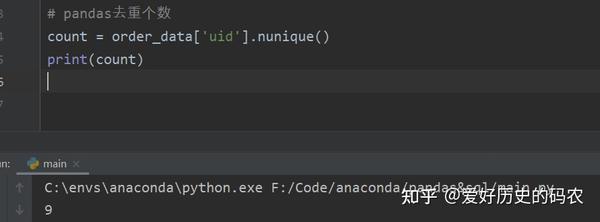
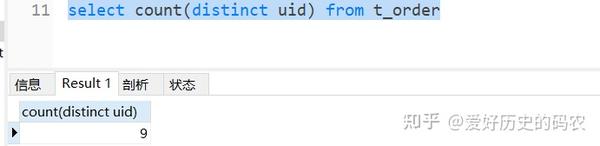
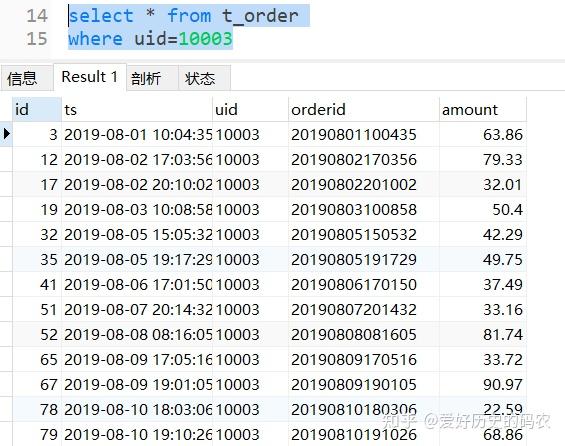
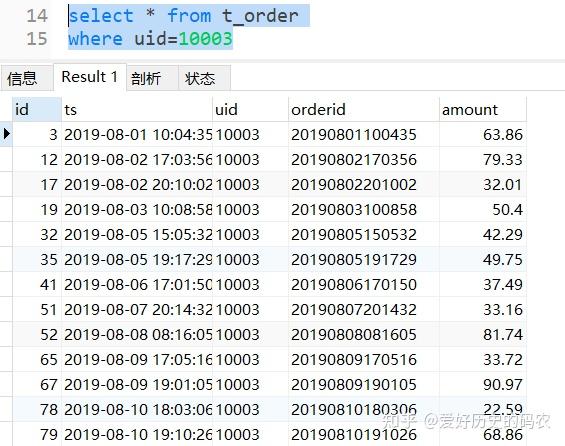
4、查询带有1个条件的数据
pandas需要使用布尔索引的方式,指定条件时,可以指定等值条件,也可以使用不等值条件,如大于小于等。但一定要注意数据类型。
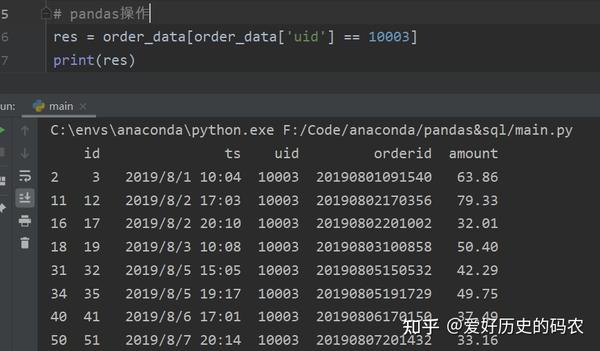
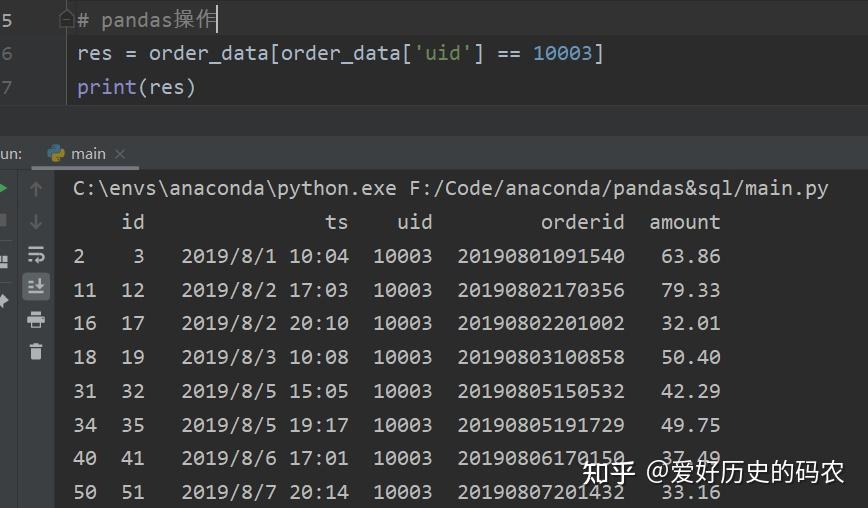
SQL中需要使用where关键字。
5、查询带有多个条件的数据
多个条件同时满足的情况
pandas需要使用&符号连接多个条件,每个条件需要加上小括号
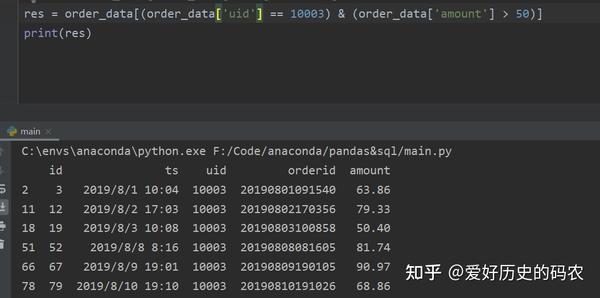
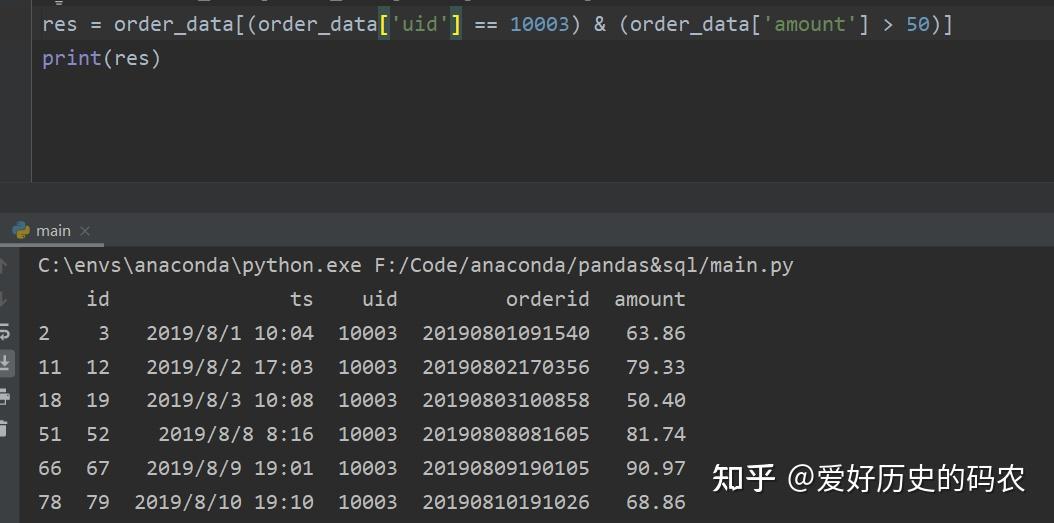
SQL需要使用and关键字连接多个条件
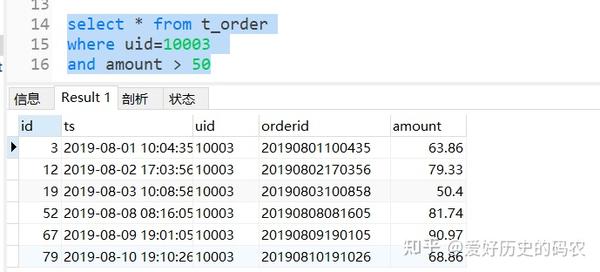
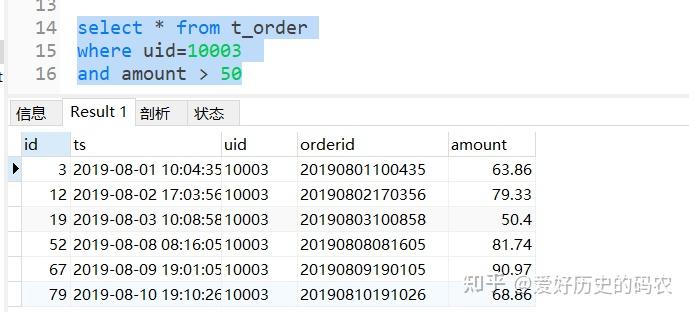
多个条件满足其中一个的情况
pandas使用|符号表示一个条件满足的情况


SQL中则用or关键字连接各个条件表示任意满足一个


判断某字段是否为空值。pandas的空值用nan表示,其判断条件需要写成isna(),或者notna()。
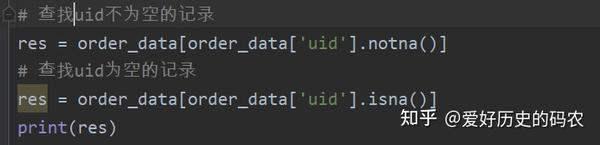
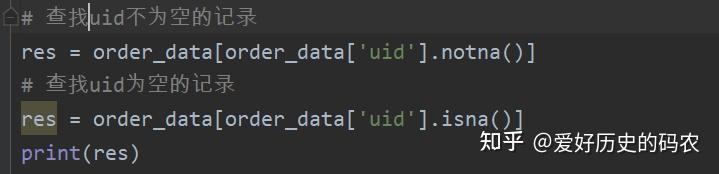
MySQL相应的判断语句需要写成 is null 或者is not null。


6、group by聚合操作
使用group by时,通常伴随着聚合操作
求每个uid有多少订单量
pandas操作,count和size不去重,nunique去重


sql操作,加上distinct去重


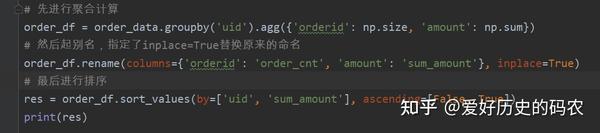
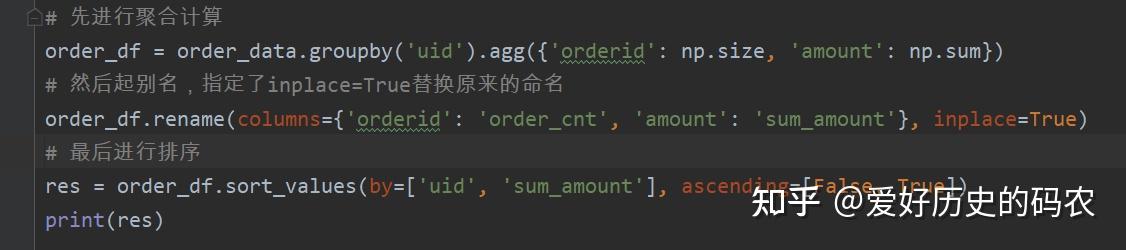
求每个uid的订单数量和订单总金额


对结果的数据集进行重新命名
pandas可以使用rename方法,MySQL可以使用as 关键字进行结果的重命名。


7、join相关操作
join相关的操作有inner join,left join,right join,full join等。pandas中统一通过pd.merge方法,设置不同的参数即可实现不同的dataframe的连接。
pandas的merge函数传入4个参数,第一个是连接的主表,第二个是连接从表,第三个连接的key值,第四个是连接的方式,how为left时表示是左连接。


其他连接方式
如果要实现inner join,outer join,right join,pandas中相应的how参数为inner或者不填,outer,right。SQL也是同样直接使用对应的关键字即可。其中inner join 可以缩写为join。


8、union操作
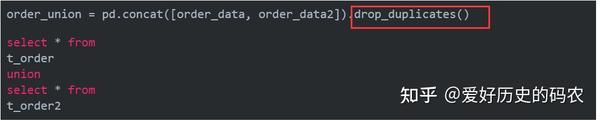
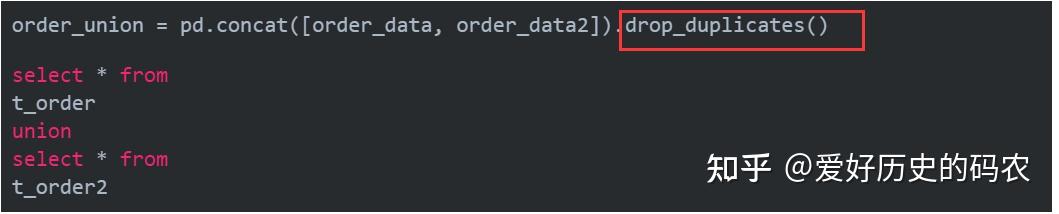
union相关操作分为union和union all两种。二者通常用于将两份含有同样字段的数据纵向拼接起来的场景。但前者会进行去重。
一份order2的订单数据,包含的字段和order数据一致,想把两者合并到一个dataframe中


以上是没有去重的情况,如果想要去重,SQL需要用union关键字。而pandas则需要加上去重操作。
9、排序操作
pandas中的排序使用sort_values方法,SQl中的排序可以使用order_by关键字。
按照每个uid的订单数从高到低排序。这是在前面聚合操作的基础上的进行的。


pandas里,dataframe的多字段排序需要用by指定排序字段,SQL只要将多个字段依次卸载order by之后即可。
输出uid,订单数,订单金额三列,并按照uid降序,订单金额升序排列。
pandas
sql


10、case when 操作
将每个uid按照总金额分为[0-300),[300,600),[600,900),三组。
pandas
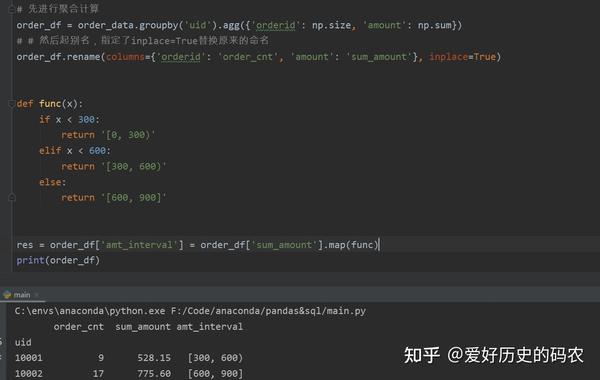
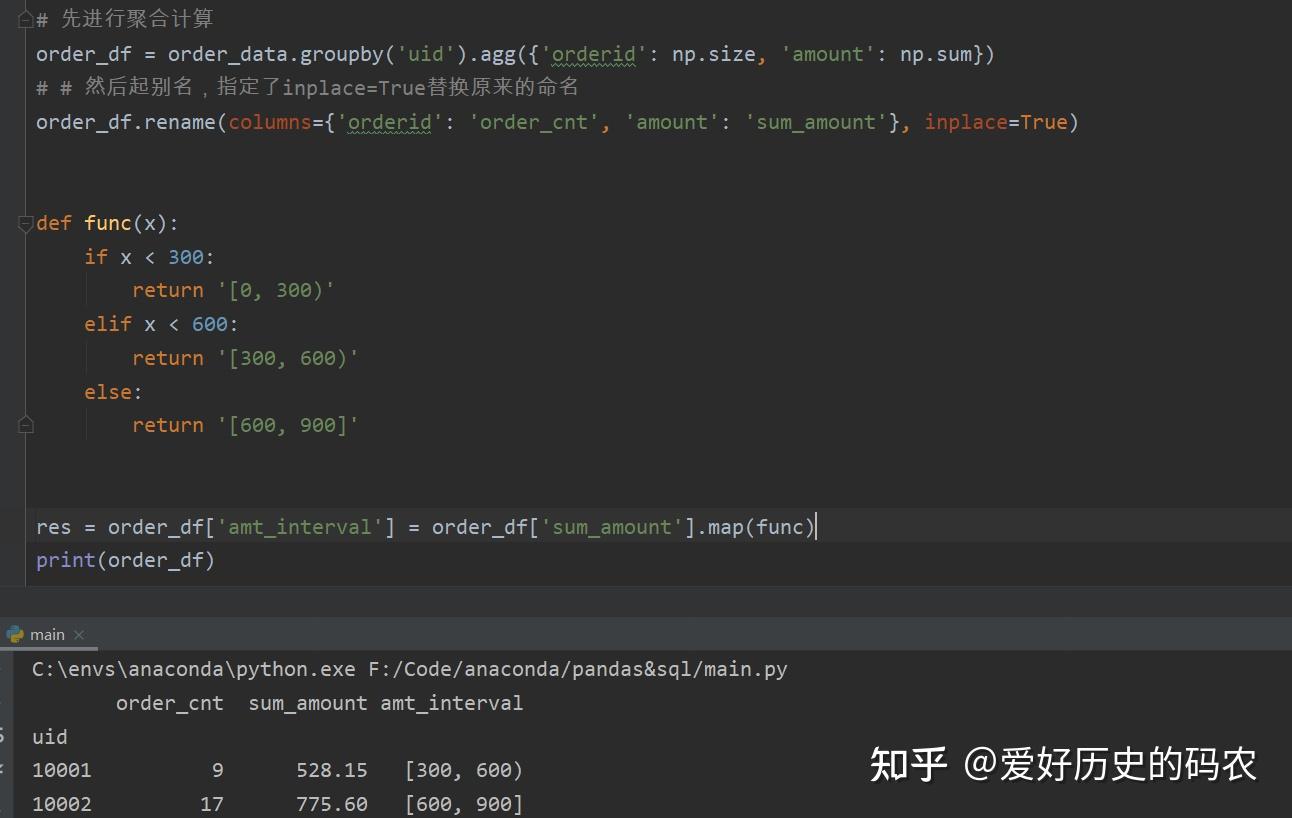
sql
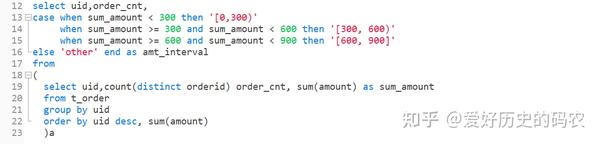
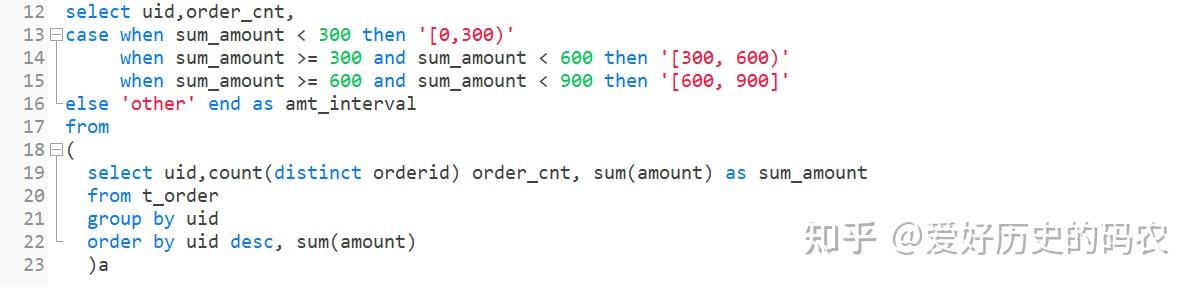
pandas的这种分组操作有一种专门的术语叫“分箱”,相应的函数为cut,qcut,能实现同样的效果。
11、更新和删除操作
更新和删除都是要改变原有数据的操作。对于更新操作,操作的逻辑是:先选出需要更新的目标行,再进行更新。
pandas中,可以使用前文提到的方式进行选择操作,之后可以直接对目标列进行赋值。SQL中需要使用update关键字进行表的更新。
将年龄小于20的用户年龄改为20。
pandas


sql


删除操作可以细分为删除行的操作和删除列的操作。
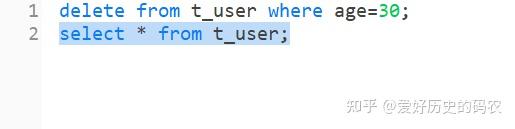
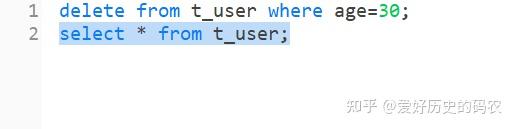
例如删除年龄为30岁的用户
对于删除行操作,pandas的删除行可以转换为选择不符合条件进行操作。
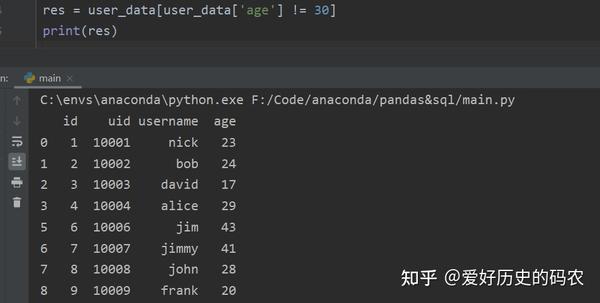
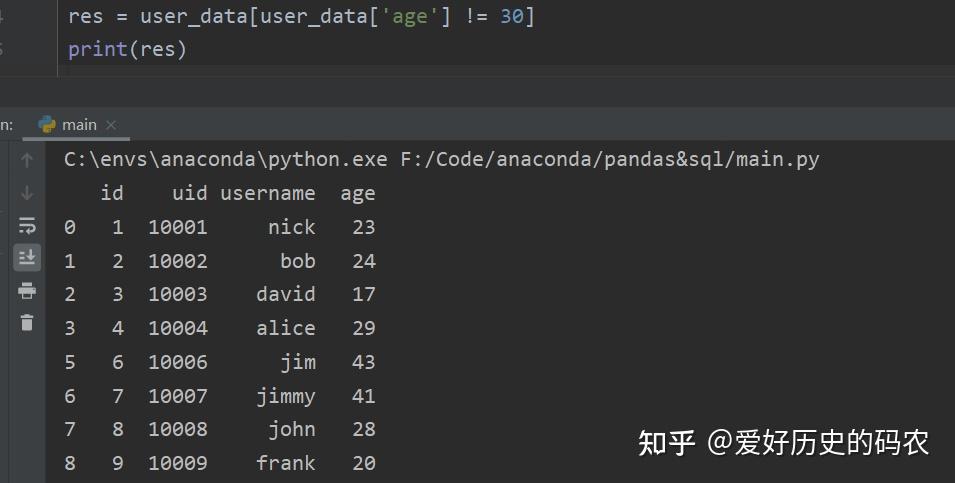
SQL需要使用delete关键字。
对于删除列的操作。pandas需要使用drop方法。


SQL也需要使用drop关键字。


12、pandas实现where in
newDropList = [9,10,11,12,22,50,51,60,61]
newDB = newDB[newDB['groupId'].isin(newDropList)] 13、not in直接加一个" - " 号即可
newDropList = [9,10,11,12,22,50,51,60,61]
newDB = newDB[-newDB['groupId'].isin(newDropList)] 14、pands把dataframe或series转换成list
df = pd.DataFrame([3, 5, 6, 2, 4, 6, 7, 8, 7, 8, 9])
df.values.tolist()
把series转换为list
Series.tolist()15、 pandas实现row_number()over()
'''
dataset: DataFrame格式数据集
partionby:分组依据字段
orderby:排序依据字段
asc:是否为升序;1:升序;0:降序
return series格式:序号
def row_number(dataset, partionby, orderby, asc):
return dataset[orderby].groupby(dataset[partionby]).rank(ascending=asc, method='first')
16、pandas.str.cat()函数
用给定的分隔符连接序列/索引中的字符串
Series.str.cat(others=None, sep=None, na_rep=None)
others:序列/索引,默认为None,如果为None则连接本身的元素 (用sep)
sep:不同元素/列之间的分隔符,默认情况下用空字符串
na_sep:为缺省值插入
可以看cat的源码中的例子