

天天写SQL,这些神奇的特性你知道吗?

摘要: 不要歪了,我这里说特性它不是bug,而是故意设计的机制或语法,你有可能天天写语句或许还没发现原来还能这样用,没关系我们一起学下涨姿势。
本文分享自华为云社区《 【云驻共创】天天写SQL,你遇到了哪些神奇的特性? 》,作者: 龙哥手记 。
一 SQL的第一个神奇特性
日常开发我们经常会对表进行聚合查询操作,但只能在 SELECT子句中写下面3种内容:通过GROUP BY子句指定的聚合键、聚合函数(SUM 、AVG 等)、常量,不懂没关系我们来看个例子
听我解释
有学生班级表(tbl_student_class) 以及数据如下
DROP TABLE IF EXISTS tbl_student_class;
CREATE TABLE tbl_student_class (
id int(8) unsigned NOT NULL AUTO_INCREMENT COMMENT '自增主键',
sno varchar(12) NOT NULL COMMENT '学号',
cno varchar(5) NOT NULL COMMENT '班级号',
cname varchar(20) NOT NULL COMMENT '班级名',
PRIMARY KEY (id)
) COMMENT='学生班级表';
-- ----------------------------
-- Records of tbl_student_class
-- ----------------------------
INSERT INTO tbl_student_class VALUES ('1', '20190607001', '0607', '影视7班');
INSERT INTO tbl_student_class VALUES ('2', '20190607002', '0607', '影视7班');
INSERT INTO tbl_student_class VALUES ('3', '20190608003', '0608', '影视8班');
INSERT INTO tbl_student_class VALUES ('4', '20190608004', '0608', '影视8班');
INSERT INTO tbl_student_class VALUES ('5', '20190609005', '0609', '影视9班');
INSERT INTO tbl_student_class VALUES ('6', '20190609006', '0609', '影视9班');我想统计各个班(班级号、班级名)一个有多少人、以及最大的学号,我们该怎么写这个查询 SQL?我想大家用脚都写得出来
SELECT cno,cname,count(sno),MAX(sno)
FROM tbl_student_class
GROUP BY cno,cname;可是有人会想了, cno和cname本来就是一对一 ,cno一旦确定,cname 也就确定了吗,那SQL咱们是不是可以这么写?
SELECT cno,cname,count(sno),MAX(sno)
FROM tbl_student_class
GROUP BY cno;执行报错了
[Err] 1055 - Expression #2 of SELECT list is not in GROUP BY clause and contains nonaggregated column 'test.tbl_student_class.cname' which is not functionally dependent on columns in GROUP BY clause; this is incompatible with sql_mode=only_full_group_by
提示信息:SELECT 列表中的第二个表达式(cname)不在 GROUP BY 的子句中,同时它也不是**聚合函数**;这与 sql 模式:ONLY_FULL_GROUP_BY 不相容的哈那为什么GROUP BY之后不能直接引用原表(不在GROUP BY子句)中的列 ?莫急,我们慢慢往下看就明白了
1.0 SQL 模式
MySQL服务器可以在不同的SQL模式下运行,并且可以针对不同的客户端以不同的方式应用这些模式,具体取决于sql_mode系统变量的值。 DBA可以设置全局SQL模式以匹配站点服务器操作要求 ,并且每个应用程序可以将其会话SQL模式设置为其自己的要求。
模式会影响 MySQL 支持的SQL语法以及它执行的数据验证检查,这使得在不同环境中使用MySQL以及将MySQL与其他数据库服务器一起使用变得更加容易。更多详情请查官网自己找:Server SQL Modes
MySQL版本不同,内容会略有不同(包括默认值),查阅的时候注意与自身的MySQL版本保持一致哈
SQL模式主要分两类:语法支持类和数据检查类,常用的如下
语法支持类
-
ONLY_FULL_GROUP_BY
对于GROUP BY聚合操作,如果在SELECT中的列、HAVING或者ORDER BY子句的列,没有在GROUP BY中出现,那么这个SQL是不合法的 -
ANSI_QUOTES
启用ANSI_QUOTES后,不能用双引号来引用字符串,因为它被解释为识别符。设置它以后,update t set f1="" …,会报 Unknown column ‘’ in field list这样的语法错误 -
PIPES_AS_CONCAT
把 || 视为字符串的连接操作符而非 或 运算符,这种和Oracle数据库是一样的哈,也和字符串的拼接函数 CONCAT()有点类似 -
NO_TABLE_OPTIONS
使用SHOW CREATE TABLE时不会输出MySQL特有的语法部分,如ENGINE,这个在使用mysqldump 跨DB种类迁移的时候 需要考虑 -
NO_AUTO_CREATE_USER
字面意思不自动创建用户,在给MySQL用户授权时,我们习惯用GRANT … ON … TO dbuser,顺道一起创建用户。设置该选项后就与oracle操作类似,授权之前必须先建立好用户
1.1 数据检查类
- NO_ZERO_DATE
认为日期‘0000-00-00’非法,与是否设置后面的严格模式有关系
1、如果设置了严格模式,则NO_ZERO_DATE自然满足。但如果是 INSERT IGNORE或UPDATE IGNORE ,’0000-00-00’依然允许且只显示warning;
2、如果在非严格模式下,设置了NO_ZERO_DATE,效果与上面一样,’0000-00-00’ 允许但显示warning;如果没有设置NO_ZERO_DATE,no warning,当做完全合法的值;
3、NO_ZERO_IN_DATE情况与上面类似,不同的是控制日期和天,是否可为 0 ,即 2010-01-00 是否合法;
- NO_ENGINE_SUBSTITUTION
使用ALTER TABLE或CREATE TABLE指定ENGINE时, 需要的存储引擎被禁用或未编译,该如何处理 。启用 NO_ENGINE_SUBSTITUTION时,那么直接抛出错误;不设置此值时,CREATE用默认的存储引擎替代,ATLER不进行更改,并抛出一个warning
- STRICT_TRANS_TABLES
设置它,表示启用严格模式。注意STRICT_TRANS_TABLES不是几种策略的组合,单独指INSERT、UPDATE出现少值或无效值该如何处理:
1、前面提到的把 ‘’ 传给int,严格模式下非法,若启用非严格模式则变成 0,产生一个warning;
2、Out Of Range,变成插入最大边界值;
3、当要插入的新行中,不包含其定义中没有显式DEFAULT子句的非NULL列的值时,该列缺少值
1.2 默认模式
当我们没有修改配置文件的情况下,MySQL是有自己的默认模式的; 版本不同,默认模式也不同
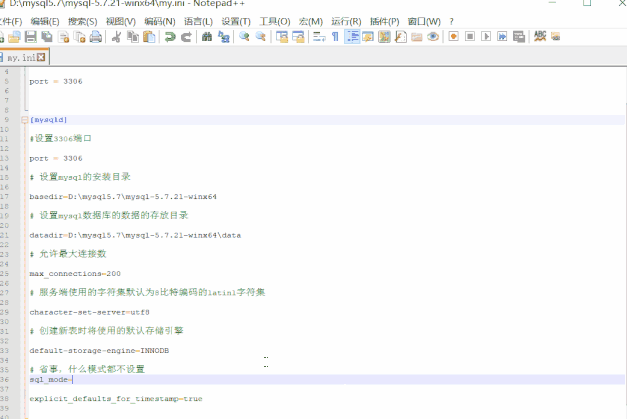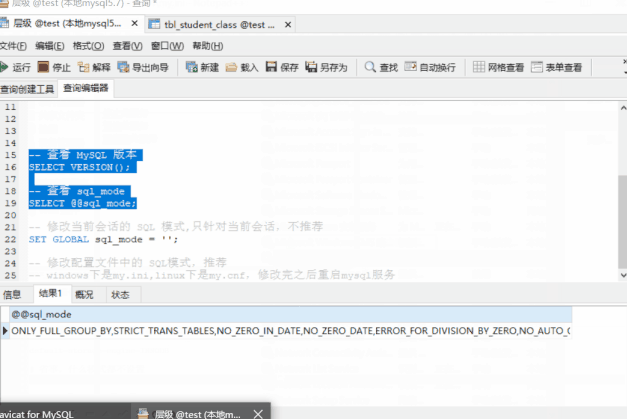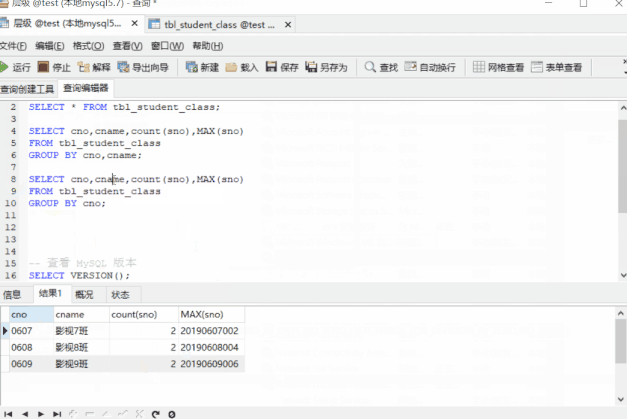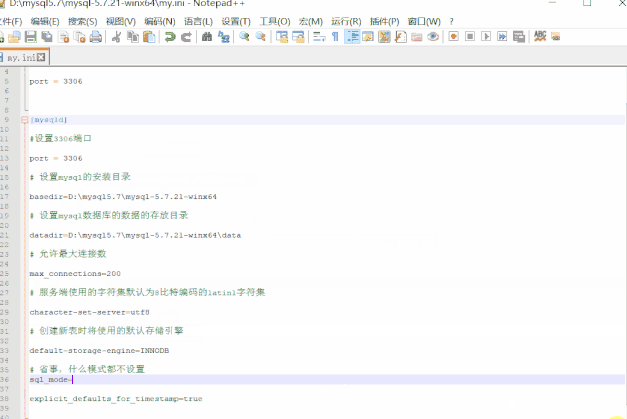
-- 查看 MySQL 版本
SELECT VERSION();
-- 查看 sql_mode
SELECT @@sql_mode;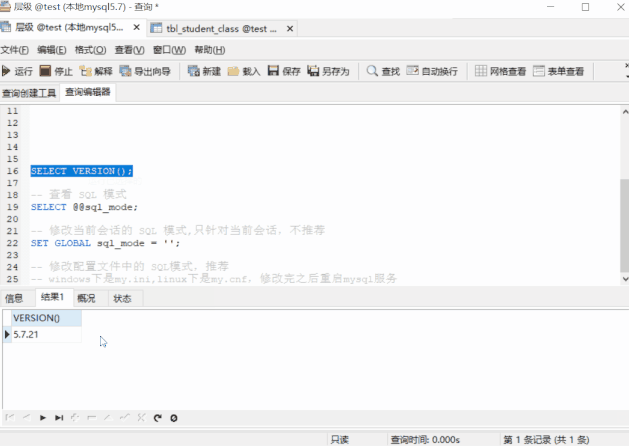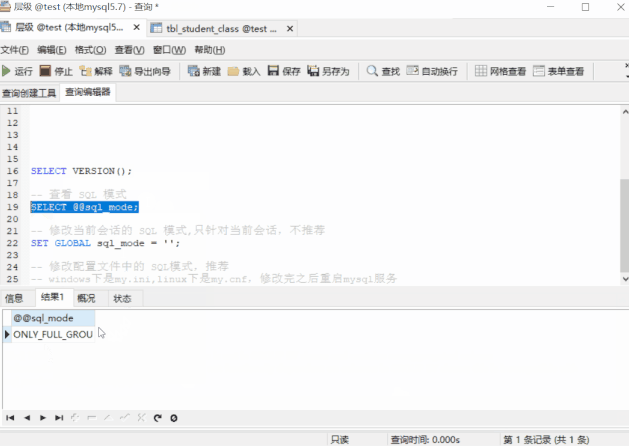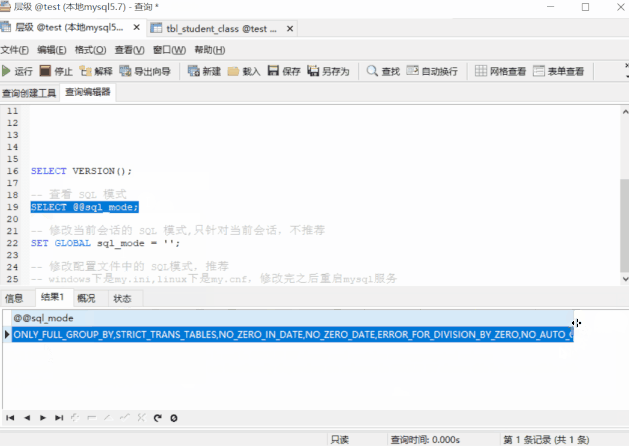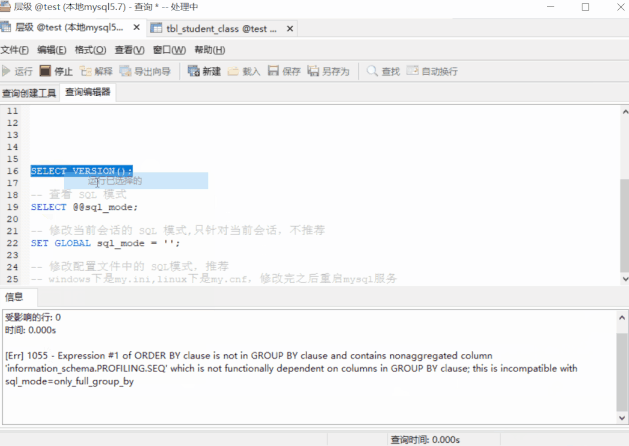

我们可以看到,5.7.21 的默认模式包含
ONLY_FULL_GROUP_BY,STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION而第一个:ONLY_FULL_GROUP_BY就会约束:当我们进行聚合查询的时候,SELECT的列不能直接包含非 GROUP BY子句中的列。那如果我们去掉该模式(从“严格模式”到“宽松模式”)呢?

我们发现,上述报错的SQL
-- 宽松模式下 可以执行
SELECT cno,cname,count(sno),MAX(sno)
FROM tbl_student_class
GROUP BY cno;能正常执行了,但是一般情况下不推荐这样配置,线上环境往往是“严格模式”,而不是“宽松模式”;虽然案例中,无论是“严格模式”,还是“宽松模式”,结果都是对的,那是因为cno与cname唯一对应的,如果cno与cname不是唯一对应,那么在“宽松模式下” cname的值是随机的,这就会造成难以排查的问题,有兴趣的可以去试下;
二 SQL的第二个神奇特性
2.1 问题描述下
今天我想比较两个数据集
表A一共 50,000,000 行,其中有一列叫「ID」,表B也有一列叫「ID」。我想查的是有A表里有多少ID在B表里面,数据库用的是snowflake,它是一种一种多租户、事务性、安全、高度可扩展的弹性数据库,或者叫它实施数仓也行,具备完整的SQL支持和schema-less数据模式,支持ACID的事务,也提供用于遍历、展平和嵌套半结构化数据的内置函数和SQL扩展,并支持JSON和Avro等流行格式;
用query:
with A as
select distinct(id) as id from Table_A
select distinct(id) as id from Table_B
result as
select * from A where id in (select id from B)
select count(*) from result返回结果是26,000,000
也就是说,A应有24,000,000行不在B里面,对吧
可是我把第11行的in改成not in后,情况有点出乎我的意料
with A as
select distinct(id) as id from Table_A
select distinct(id) as id from Table_B
result as
select * from A where id not in (select id from B)
select count(*) from result返回结果竟然是0,而不是24,000,000
于是我在snowflake论坛搜了下,发现5年前在这帖子下面有人回复到:
If you use NOT IN (subquery), it compares every returned value and in case of NULL on any side of comparison it stops immediately with non defined result if you use NOT IN (subquery), it compares every returned value and in case of NULL on any side of comparison it stops immediately with non defined result
就是说,当你用not in,subquery(例如上面第11行的select id from B)里 如果有Null,那么它就会立刻停止,返回未定义的结果 ,所以最后结果是0;
该如何解决?很简单
2.2 去掉null值
在第7行加了限定where id is not null后,结果正常了
with A as
select distinct(id) as id from Table_A
select distinct(id) as id from Table_B where id is not null
result as
select * from A where id not in (select id from B)
select count(*) from result最终返回结果为24,000,000,这样就对了啊
2.3 用not exists代替not in
注意第11行,用了not exists代替not in
with A as
select distinct(id) as id from Table_A
select distinct(id) as id from Table_B where id is not null