


python自动爬取pdf中表格

题记:最开始写爬虫代码的时候仅仅是因为觉得爬虫这个工具看起来更具有黑客的感jio,但随着读书的深入,简单的爬虫知识在广泛的应用场景下体现的作用有限,因此激发了想结合一些业务场景进行挖掘的coding。
本文仅为了个人在成长历程的记录,不包含最基础的教学,有问题可以进行探讨,但是由于本人金工非cs专业毕业,所学定有不足~。
展示:
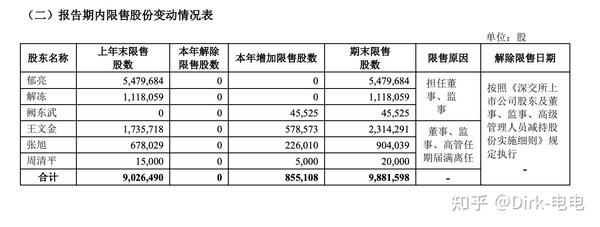
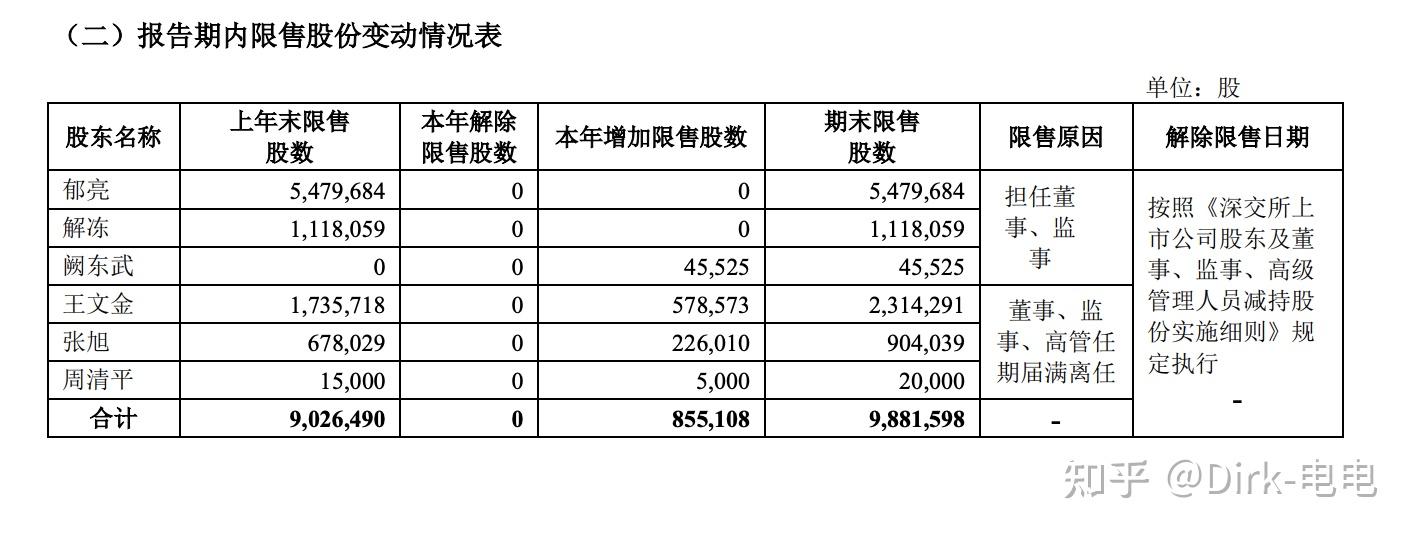
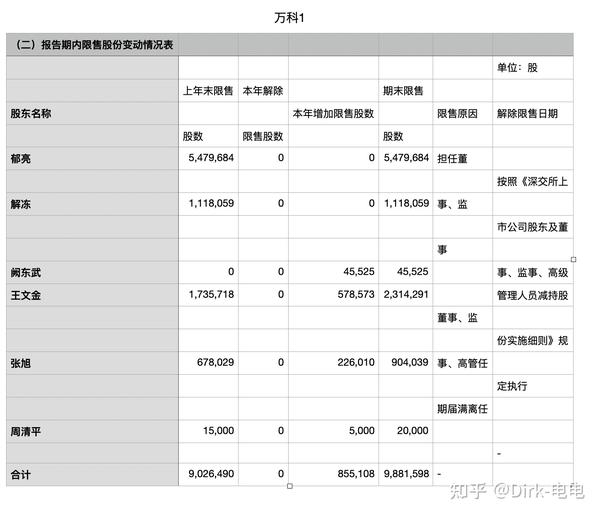
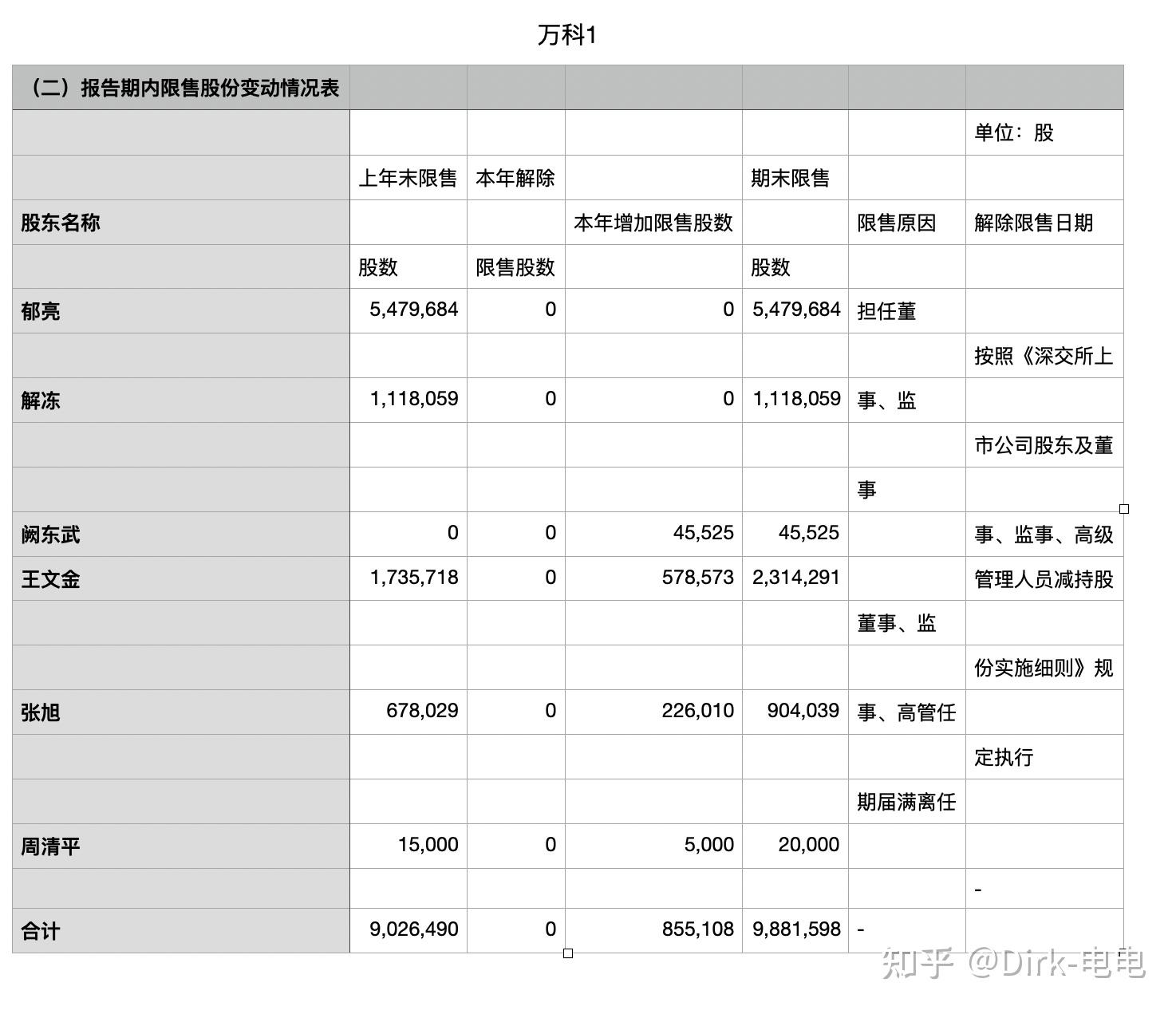
可见,pdf转excel其实还是有些不足,如有些文字无法按人为意愿进行单元格切分,但是用python进行数据分析时,却可以提供一种不错的方法。
网上有很多已经有的版本,但实际操作时,网上的有些代码由于部分包已经过时,无法再继续使用,因此对部分代码进行改动。
自动爬取pdf文件中的表格程序,是由于一个资产管理的老哥想要获取N多家地产上市公司的年报中关于某细项中的某特定表格而产生的需求,但是面临的主要挑战在于:
- 每家公司年报中跟此细项有关的内容所在页面不为固定页。
- pdf无法将标准的表格读取下来。
- 公司太多,无法很快整理。
针对此需求,我们制定方案:
- 定向读取网页中某pdf文件
- 根据细项中某固定文字判定页码。
- 根据页码读取此页所有表格。
- 将读取的表格输出到本地。
缺点:
读取速度过慢。
以下为读取的代码。
#本文件请下载以下包
#pdfminer3k 版本为1.3.4
#pdfminer.six版本为20201018
#opencv-python版本为4.5.1.48
#requests版本为2.22.0
#camelot-py版本为0.8.2
#pip install pdfminer3k
#pip install opencv-python
#pip install camelot-py[cv]
#pip install requests
from pdfminer.pdfparser import PDFParser
from pdfminer.pdfdocument import PDFDocument
from pdfminer.pdfinterp import PDFResourceManager
from pdfminer.pdfinterp import PDFPageInterpreter
from pdfminer.converter import PDFPageAggregator
from pdfminer.layout import LTTextBoxHorizontal
from pdfminer.layout import LAParams
from pdfminer.pdfpage import PDFPage
import requests
import camelot.io as camelot
import cv2
from urllib.request import urlopen
#url: pdf网址
#url='http://static.cninfo.com.cn/finalpage/2020-08-28/1208280699.PDF'
#pdf_outputfile:存储pdf的位置
#pdf_outputfile='/Users/dirk/metadata.pdf'
#xlsx_output_file输出所需表格的文件路径
#xlsx_output_file='/Users/dirk/'
#本程序需要确保pdf所需的表格样式在统一索引位置,此处为方便截取
#想要定位的文字附近出现的表格word_list=['报告期内限售股份变动情况表']
#xlsx_name
#xlsx_name=万科
# TakeForm('http://static.cninfo.com.cn/finalpage/2020-08-28/1208280699.PDF',['报告期内限售股份变动情况表'],'/Users/Dirk/万科.pdf','/Users/Dirk','万科')
def TakeForm(url , word_list, pdf_output_file , xlsx_output_file , xlsx_name):
r = requests.get(url, stream=True)
with open(pdf_output_file, 'wb') as fd:
fd.write(r.content)
except Exception as e:
print('请确保文件路径正确'+e)
parsePDFtoTXT(pdf_output_file,xlsx_output_file)
page=get_word_page(word_list,xlsx_output_file)
print('*'*10)
print('将抓取第%s页' %page)
tables = camelot.read_pdf(pdf_output_file, pages='{}'.format(page),flavor='stream')
for i in range(len(tables)):
print(tables[i].df)
tables[i].to_csv(xlsx_output_file+xlsx_name+str(i)+'.csv')
def parsePDFtoTXT(pdf_path,xlsx_output_file):
fp = open(pdf_path, 'rb')
parser = PDFParser(fp)
document= PDFDocument(parser)
# parser.set_document(document)
# document.set_parser(parser)
# document.initialize()
# if not document.is_extractable:
# print('出现了一个错误')
# else:
rsrcmgr=PDFResourceManager()
laparams=LAParams()
device=PDFPageAggregator(rsrcmgr,laparams=laparams)
interpreter=PDFPageInterpreter(rsrcmgr,device)
for page in PDFPage.create_pages(document):
interpreter.process_page(page)
layout=device.get_result()
print(layout)
output=str(layout)
for x in layout:
if (isinstance(x,LTTextBoxHorizontal)):
text=x.get_text()
output+=text
with open(xlsx_output_file+'过渡文件.txt','a',encoding='utf-8') as f:
f.write(output)
def get_word_page(word_list,xlsx_output_file):
f=open(xlsx_output_file+'过渡文件.txt',encoding='utf-8')
text_list=f.read().split('<LTPage')
n=len(text_list)
for w in word_list:
page_list=[]
for i in range(1,n):
if w in text_list[i]:
page_list.append(i)