


自动生成测试 -- Automatic Test Generation

程序员也要被 AI 抢饭碗了?
可能你还不知道,Google 早已在 2014 年的 4 月 1 日, 宣布 他们已经掌握了自动生成代码的技术。在给 Google Brain 训练了数十亿行代码后,Google Brain 已经具备了通过分析测试代码自动生成程序代码的能力。Google 的员工以后只需要写测试代码就可以了,他们实现了真正的 Test Driven Development(TDD)!
(OMG!这一秒感觉活在 Matrix 里。)
当然,这只是 Google 跟大家开的一个愚人节玩笑而已。
而这个玩笑的背后,可并不那么简单。虽然目前自动生成代码并没有普及,但自动生成测试技术已经是一个非常流行的话题,并被广泛应用在工业界中了。
猴子也能做测试?
你一定听说过这样一个理论:
让一只猴子在打字机上随机地按键,当按键时间达到无穷时,几乎必然能够打出任何给定的文字,比如莎士比亚的全套著作。
这个理论叫做无限猴子定理( Infinite monkey theorem )。
测试中常见的 Monkey Testing 中的 Monkey 一词,正是来源于此。Monkey Testing,是指通过随机的向程序输入数据,并监控程序的行为,以发现程序中的 bug,例如 crash,内存泄露等。
我们来看看 Monkey Testing 是如何找到 bug 的。
例如有如下函数:
int foo(int x) {
int y = x + 3;
if (y == 3) abort(); // error
return 0;
这里有一个明显的 bug,当函数进入 y == 3 的情况下,会触发程序崩溃。
#include <stdlib.h>
int main() {
while (true) {
foo(rand());
我们可以通过反复生成一个随机数并调用 foo 函数,直到程序崩溃为止。总有机会满足 y == 3 的要求并触发 bug。这就是 Monkey Testing 的最简单的一个示例。
从这里,我们可以看出 Monkey Testing 的核心思想,通过随机生成测试数据,并作为输入提供给程序(或函数),尽可能的覆盖全部的代码路径,从而找出 bug。而在这过程中,随机生成测试数据的过程,就被称作 Test Generation。由于整个过程中不需要人工参与,所以也叫做 Automatic Test Generation。
猴子的局限
看到这里,可能有人会比较惊讶,Monkey Testing 不就是穷举么,这么简单,只不过效率低点罢了。而类似的思想也早在 1950 年代就 已经诞生 ,当时还是纸带打孔时代,程序员从垃圾堆里面随便找出一堆纸带并输入给程序,如果程序有超出预期的行为,则可能是发现了 bug。
Monkey Testing 最大的局限是,纯随机生成的测试数据中,大部分测试数据覆盖的是重复的代码路径,这导致效率十分低下。在上面的例子中,为了覆盖两个代码路径,最差情况可能需要生成 2 的 32 次方个测试数据。假设生成一个随机数,并调用一次 foo 函数,共需要 10 纳秒的时间,在最坏情况共需要 42 秒的时间才能完成覆盖,并发现 bug。
而这仅仅是 4 字节的输入数据,一个函数,三行代码,一个分支的覆盖。对于一个完整的应用程序,可能存在数百万行代码和数十万个分支,如果将分支进行组合,可能存在的代码路径将是天文数字(Path Explosion)。而输入数据的范围也可能是无限的,这样通过 Monkey Testing 的方式遍历所有的代码路径,将是一个无法完成的任务。当然,我们可以通过并发的方式缩短测试的时间,但整体消耗的机器时间是不变的。
假如我们对上面的 foo 函数进行少许修改:
#include <stdlib.h>
int foo(int x1, int x2) {
int y1 = x1 + 3;
int y2 = x2 + 3;
if (y1 == 3 && y2 == 3) abort(); // error
return 0;
int main() {
while (true) {
foo(rand(), rand());
则触发 bug 的概率降为 2 的 64 次方分之一,最差情况需要 5849 年的机器时间。。。(此处请忽略 rand 函数本身伪随机属性对概率的影响,我们假设 rand 函数是真正随机的)
猴子走了,兔子来了
聪明的你一定在思考,Monkey Testing 的思路倒是靠谱,但是有没有更高效的穷举方法呢?答案显然是存在的。从这里开始,我们将介绍 Fuzz Testing (也称作 Fuzzing)。
我们再回过头来看看前面提到的方法,漫无目的的生成随机测试数据,我们称之为 Monkey Testing,也可以称作是 Blackbox Fuzz Testing。因为我们在生成测试数据的过程中,假设不知道程序内部的运行状态,而完全是依靠随机的方式。而更高效的方法是 Greybox Fuzz Testing。
Greybox Fuzz Testing 的核心思想是,现实世界中,程序的输入数据大部分是存在某种特定语义的,基于一组有效语义的 seed 数据以及各种 Fuzzing Strategy 所生成的测试数据,更容易覆盖更多有效的代码路径。例如我们在为一个图片浏览器程序生成数据时,如果是纯粹随机的数据,那么大部分的测试数据都是无效的,会因文件不符合某种格式而走入相同的代码路径。这显然极其低效。而基于有效的图片文件进行比特翻转,或文件大小调整,则更容易避免这种情况,从而尽可能高效的生成有效测试数据。
再比如,我们在上一篇文章 《扒一扒 Linux 文件系统的黑历史》 中,就提到了 Vegard Nossum 和 Quentin Casasnovas 使用 AFL(American Fuzzy Lop,原意是一种兔子) 对 Linux 文件系统进行测试,就是将一组有效的文件系统镜像(Image)作为 seed 数据,就很容易发现文件系统的 bug。 而可以触发 bug 的镜像,还可以被保存下来并用于后续的 regression 测试。
我们通过一个直观的例子来介绍 AFL:
首先,创建一个文件 http:// foo.cc
#include <stdlib.h>
#include <iostream>
int foo(int x) {
if (x == 1 << 20) abort();
return 0;
int main() {
int x;
std::cin >> x;
foo(x);
通过 afl-g++ 进行编译,并通过 afl-fuzz 命令执行:
[kyle@localhost]$ /tmp/afl-2.51b/afl-g++ foo.cc
[kyle@localhost]$ mkdir in
[kyle@localhost]$ echo 0 > in/0
[kyle@localhost]$ /tmp/afl-2.51b/afl-fuzz -i in -o out -- ./a.out就可以看到以下界面
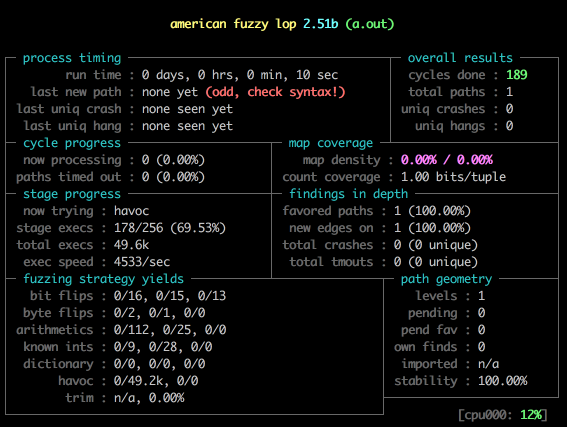
其中,in/0 就是 seed 文件。
这里再补充一篇 博客 ,作者介绍了基于 AFL 发现 Perl 解释器 bug 的过程,仅用 48 小时就发现了 10 个 bug。你也可以用类似的方法,为其他的编译器,或其他类型的程序找 bug。
LLVM 社区的 LibFuzzer 和 AFL 具有类似的思想。Google 的 ClusterFuzz 就是基于 LibFuzzer 的。
和 Monkey Testing 相比,Greybox Fuzz Testing 生成有效测试数据的效果提升非常明显,并且在具体应用过程中也有着非常好的效果。然而尽管如此,从本质上讲,Greybox Fuzz Testing 还是一种基于暴力的方式,他不保证能够准确的覆盖到全部代码路径。例如我们上面提供的 http:// foo.cc 文件,对于 AFL 来说,想要找到 bug 依然还是需要花费非常非常久的时间。
兔子的进化
那么是否存在不暴力的精确生成测试数据的方法呢?答案当然也是肯定的。
2005 年,当时还在贝尔实验室工作的 Patrice Godefroid (目前已在微软研究院工作),在 PLDI '05 上发表了一篇 文章 ,通过符号执行( Symbolic Execution )技术,分析所有分支路径的符号约束(Symbolic Constrains),来指导如何生成新的测试数据(Guided Test Generation),以保证每一个代码路径尽可能的只执行一次,这样就可以大大的提高分支覆盖的效率,避免生成的测试数据重复的走入同一个代码路径。这种方式也被称作为 Whitebox Fuzz Testing。
符号执行 (Symbolic Execution)是一种程序分析技术。其可以通过分析程序来得到让特定代码区域执行的输入。
这里我们还是以最简单的程序进行举例,看看 Patrice Godefroid 是怎么通过 Symbolic Execution 解决这个问题的:
int foo(int x) {
int y = x + 3;
if (y == 3) abort(); // error
return 0;
首先,我们随机生成一个 x 的值,假设是 100,并调用 foo 函数,y 将被赋值为 103。接下来,将执行 if 分支判断。由于 y 是 103,不等于 3,则进入 else 分支。为了得到如何进入另一个分支的条件,我们将 x 替换成一个 Symbolic,例如 λ,那么进入另一个分支的条件是 λ + 3 == 3,也就是分支约束(Path Constrains)。根据这个条件,可以推导出 λ 为 0 时,可以进入这一分支,而 λ 为 0 就是符号约束(Symbolic Constrains)。而整个推导的过程,被称为 Constrains Solving。根据这个符号约束,我们可以在第二次执行时,直接将 x 赋值为 0,并调用 foo 函数。这样一来,只需要执行两次,就会完成代码路径覆盖并发现 bug。
而对于复杂的 foo 函数也是一样:
int foo(int x1, int x2) {