其实正儿八经的说,PDF文件名称这不算是一个乱码问题。
为什么这么说呢,因为我们看到的文件名称中杂乱无章的编码其实就是js把中文进行了编码而已,和真正的因为编码错误造成的乱码并不一样。
【心急的同学可以直接翻到最下面看:- 解决方法-】
我们看先错误出现的场景:
-
我使用pdf.js预览了一个叫做
02010204_钢筋安装检验批质量验收记录_02010204016.pdf
的文件,然后我点击pdf工具栏的下载时,给我生成的文件名是这样的:
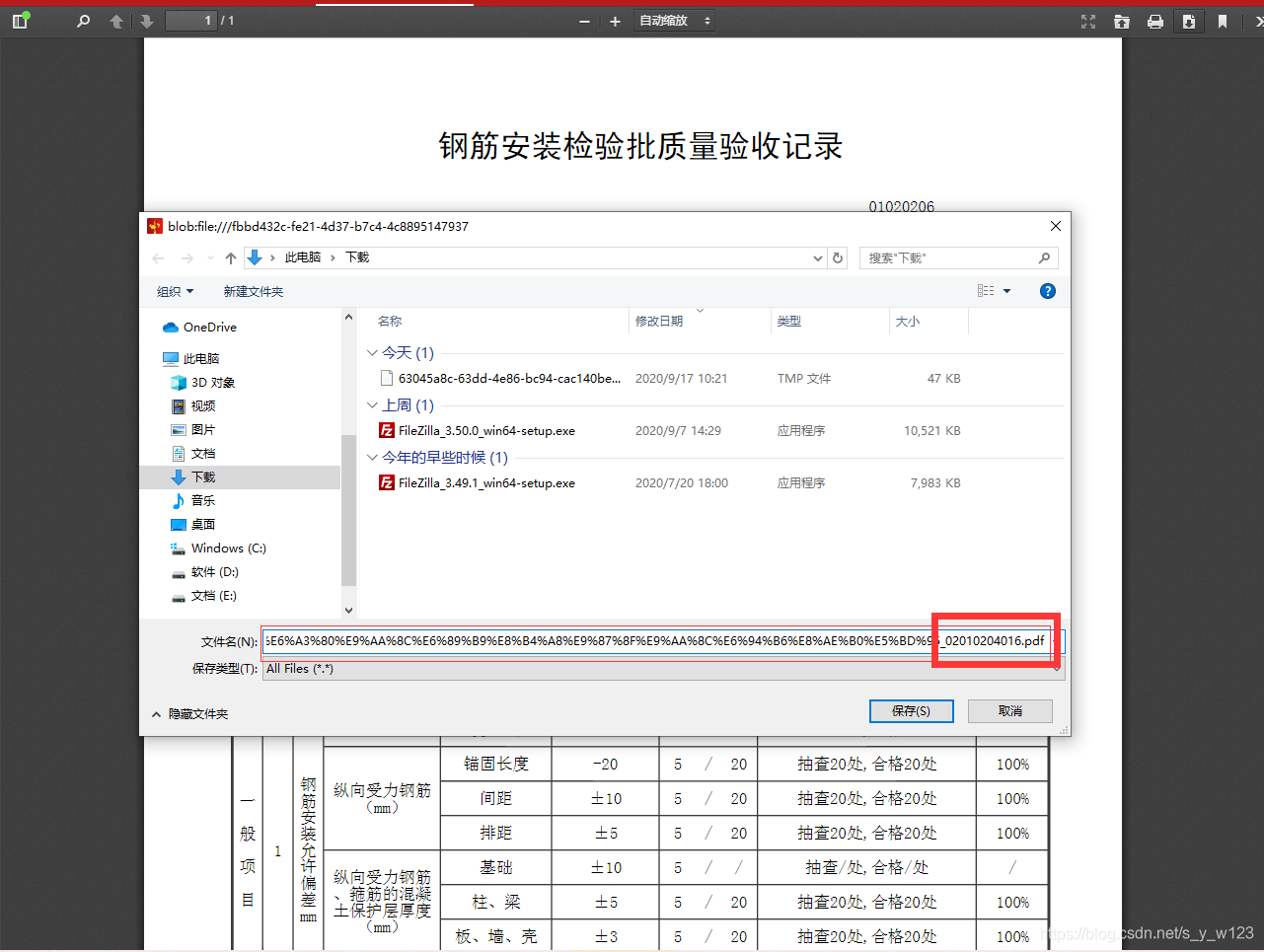
-
我们从这个生成的名称中,可以看出,文件名称中非中文的字符都是正常的,中文的字符是不正常的,我们要解决的就是这个问题。
造成的原因:
-
网上的方法我也看了很多,比较常见的就是把我们要预览的地址先进行编码,使用JavaScript的
encodeURIComponent()
方法,还有在
html中引入viewer.js 的script里指定charset="gb2312"
。这些方法我都试了一下,结论是:不适用我这个情况。【其实就是加没加没啥变化】
-
不得已,翻了一下viewer.js关于下载这一部分的代码,还真让我发现了原因:
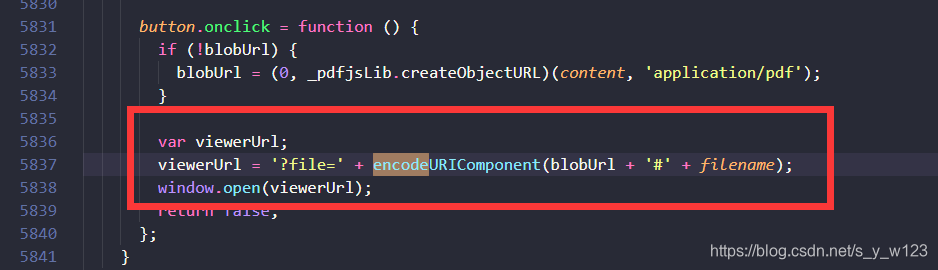
在这里,viewer.js已经帮我们对文件名称进行了编码,所以我下载时生成的文件名就是编码过后的。
解决方法:
-
知道了原因,那解决方法就不难想了,对文件名进行解码,使用JavaScript的
decodeURIComponent()
方法。
-
找到viewer.js中的
_download()
方法
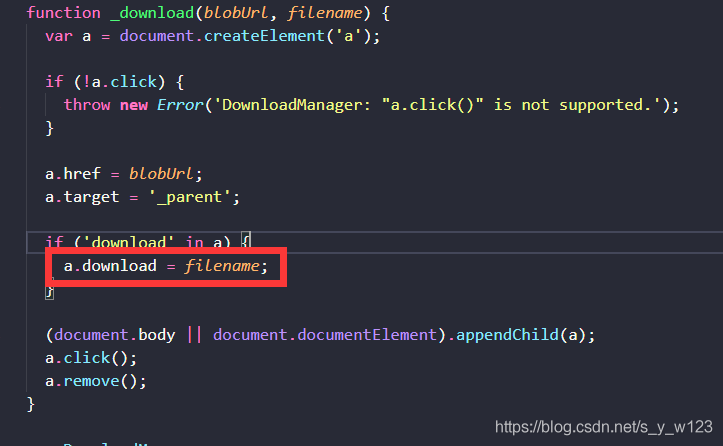
把我红框框柱的代码替换成下面的代码即可:
a.download = decodeURIComponent(filename);
最终效果:
- 至此,就搞定了,说了这么多其实就是换一行代码的事情,其实主要还是让大家了解一下寻找问题的过程,思想很重啊哟,哈哈。【附:效果图】。
在这里说一下.pdf后缀的问题:
有些时候我们下载pdf进入到上图(最终效果图)界面后会碰到文件名的后缀没有带 .pdf 的,这种情况下载下来的是pdf文件,但是没有后缀名,而且下载下来因为没有后缀名有时候没法直接打开,需要手动的加上.pdf后缀名。
要解决这个问题也很简单,还是从download的时候的文件名入手:
if(decodeURIComponent(filename).endsWith('.pdf')){
a.download = decodeURIComponent(filename);
} else {
a.download = decodeURIComponent(filename) + '.pdf'
只需要判断一下,如果没有.pdf后缀,如果在下载还是没有,那么接着往下看:
到这里其实细心的同志已经发现了,这一段代码里有a.href a.target a.download,这就是赤裸裸的给a标签加属性的啊,既然是a标签,那我们还可以给指定一下MIME类型。
所以在判断文件是不是以.pdf结尾之前,我们还可以指定type:
a.type = "application/pdf";
到这里,你下载文件的时候,文件名的地方应该就会给你带上.pdf了,如果还不带.pdf后缀,那么请看一下:你的电脑是不是隐藏了文件的扩展名。
注意:我也不能保证此方法就一定可以解决你的问题。毕竟出现问题的情况千变万化。这里只是给大家提供一种方法尝试。
由于项目中需要支持移动设备在线浏览pdf,苹果还好,天生支持,但是安卓中就不行了,需要第三方组件的支持。这里就找到了pdf.js,由于pdf数据太多,开始的时候没法一一测试,所以随便测试打开了几篇没问题后就直接上线了。但是后面就悲剧了,偶然收到反馈,有些pdf无法正常浏览,此为写本文的原因。具体的现像查找问题过程一、用火狐(火狐解析pdf是用的pdf.js)来直接打开这篇pdf,发现居然是对的,那...
1.首先需要一个支持中文的字体ttf文件,可以在网上下载,也可以使用本地window/font/路径下的文件(选择一个自己需要的),这个文件将在步骤3中用到
2.下载jspdf
方式1:使用命令git clone https://github.com/MrRio/jsPDF.git
方式2:下载zip文件
3.下载后找到fontconverter目录中的fontconver
因此,要解决这种方式中文乱码的问题,其实就是解决 html2canvas 库对中文的不支持问题,其解决方式是通过设置 html2canvas 的字体。中的字体转换器,可以将字体的ttf文件转换为base64编码字符串的形式。使用 jspdf.js 生成 PDF 文件有两种方式:一种是创建 jsPDF 实例后,手动使用 addPage、text 等 api 把获取到的数据排版生成 PDF 文件;jsPDF支持 .ttf 文件,因此,如果你想在 PDF 中使用中文文本,则字体必须具有包含必要的中文字形的功能。
场景描述:本问题也是之前谈论的pdf转化为图片的项目,之前有聊到过由于不能正常展示印章而把pdf转化成了PNG图片来展示。而其他的条款由于没有印章这个问题,所以就使用了pdf.js这个插件进行展示,之前展示的文件名都是用的英文是没有问题的。但是后来发现ios里面会展示出来这个名字,被用户看到后不便于理解,所以就想着要改为中文,那么问题就来了。具体操作解决方案接着说,直接将文件名改成中文后,发现一切并
我就像一个哑巴一样
今天分享一下完美解决jsPDF生成pdf出现乱码的问题,包括文本,表格表头已经表格内部出现乱码的问题~首先老规矩把代码clone下来
gitclonehttps://github.com/MrRio/jsPDF.git复制代码
然后打开文件根目录会看到一个fontconverter的文件夹
打开里面的html文件,然后把选择你的本地文件,填上name最好要填中文!然...
@RequestMapping("/{id}/download")
@ResponseBody
public ResponseEntity<byte[]> downLoadRpt(@PathVariable("id") Integer companyId) {
CreditOrder creditOrder = creditOrderService.getCredit
由于项目中需要支持移动设备在线浏览pdf,苹果还好,天生支持,但是安卓中就不行了,需要第三方组件的支持。
这里就找到了pdf.js,由于pdf数据太多,开始的时候没法一一测试,所以随便测试打开了几篇没问题后就直接上线了。
但是后面就悲剧了,偶然收到反馈,有些pdf无法正常浏览,此为写本文的原因。
具体的现像
查找问题过程
一、用火狐(火狐解析pdf是用的pdf....
git clone https://gitee.com/mirrors/jspdf.git
2.依次找到 jspdf 》fontconverter文件夹,在浏览器打开fontconverter.html网页,输入想要字体名,例如Deng,选择C盘》Windows 》fonts文件夹下的字体,例如等线字体,点击create按钮,生成Deng-norrmal.js文件。
注意:如果没有权限,则把字体复制一份到桌面再选择。
3.将新生成的Deng

