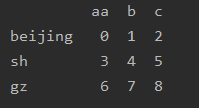
DataFrame修改index索引和columns列名修改索引index1、采取直接赋值的方法:df1=pd.DataFrame(np.arange(9).reshape(3,3),index=['bj','sh','gz'],columns=['a','b','c'])print(df1)#修改index,直接给index重新赋值df1.index=['beijing','shan...
df.set_index([Column], inplace=True)
以上这篇Python将DataFrame的某一列作为index的方法就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持软件开发网。
您可能感兴趣的文章:python 给DataFrame增加index行名和columns列名的实现方法用pandas中的DataFrame时选取行或列的方法python中pandas.DataFrame对行与列求和及添加新行与列示例pandas数据处理基础之筛选
dataframe.rename(columns = {"old_name": "new_name"})
dataframe.rename(columns = {"old1": "new1", "old2":"new2"}, inplace=True)
lambda:
from pandas import DataFrame
1、使用二维数组创建
df1=DataFrame(np.random.randint(0,10,(4,4)),index=[1,2,3,4],columns=['a','b','c','d'])
print(df1)
创建了一个4行4列由0-10随机整数组成的二维数组
列名为a、b、c、d
索引为:1、2、3、4
输出结果为:
2、使用字典创建
dict={
'province':['Gua
在pandas中,可以使用set_index()方法来修改DataFrame的索引。它有两个参数:第一个是用作新索引的列名或列编号,第二个是一个布尔值,用于指示是否在原始DataFrame中保留该列。
例如,如果你有一个名为df的DataFrame,其中有一列叫做'index_col',你想要将它设置为新的索引,而不在原始DataFrame中保留该列,可以这样做:
df = df.set_inde...
一般常用的有两个方法:
1、使用DataFrame.index = [newName],DataFrame.columns = [newName],这两种方法可以轻松实现。
2、使用rename方法(推荐):
DataFrame.rename(mapper = None,index = None,columns = None,axis = None,copy = True,inplace = Fa...
data = [['AMB_TEMP', '14', '14', '14', '13', '12', '12', '12', '12', '15',
'17', '20', '22', '22', '22', '22', '22', '21', '19', '17', '16',
'15', '15', '15', '15'],
['CH4', '1.8', '1.8', '1.8', '1.8', '1.8', '1.8', '1.8', ...
goodsList.append(pd.Series([spiderTime, id[0], xingzhi, shopName[0], item_loc[0], price[0], view_sales[0], title[0]]))
columns = ['采购时间', 'id', '性质', '店铺名称', '发货地', '价格', '收货人数', '名称']
goodsInfo ...
columns
#显示结果
Index(['Rank', 'Title', 'Genre', 'Description', 'Director', 'Actors', 'Year',
'Runtime (Minutes)', 'Rating', 'Votes', 'Revenue (Millions)',
df1=pd.DataFrame({'id':[1,2,3,4],'name':['aa','bb','cc','dd'],'class':[1,1,2,2]})
id name class
0 1 aa 1
1 2 bb 1
2 3 cc 2
3 4 dd 2
使用rename函数更改列名
df2=df1.rename(columns={'name':'stu_name','clas...
可以使用set_index()函数将dataframe的第一列作为索引,具体代码如下:
df.set_index(df.columns[], inplace=True)
其中,df是你的dataframe,df.columns[]表示第一列的列名,inplace=True表示直接在原dataframe上修改。