


Auto-Sklearn的理解

文章介绍:
Efficient and Robust Automated Machine Learning
发表于NIPS 2015,Matthias Feurer, Aaron Klein, Katharina Eggensperger, etc. University of Freiburg, Germany.
这篇文章最大的贡献是提出了Auto-Sklearn的框架,包括了MI-SMBO和Ensemble selection。MI-SMBO是指Initializing SMBO With Configurations Suggested by Meta-Learning;Ensemble是指Automated emsemble construction of models evaluated during optimization。
文章相关工作和问题:
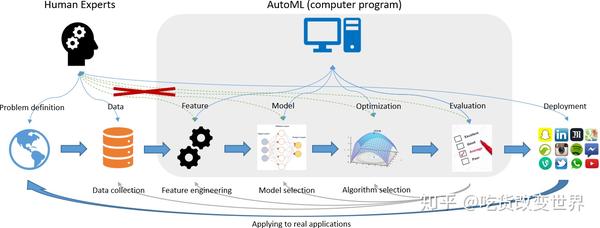
Auto ML其实是一个很大的领域,其目的就是在机器学习的各个环节中,减小人工干预,减小计算代价。如下图所示,目前Auto ML的工作主要集中在特征工程、模型选择、优化算法,以及评估这四个环节。
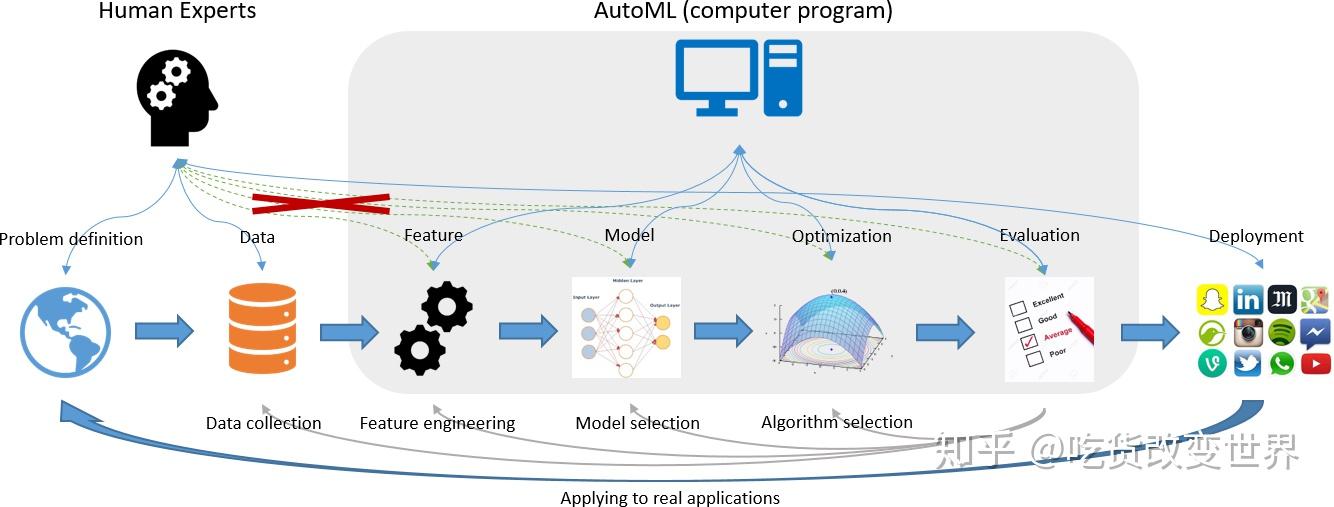
这篇文章提出的Auto-sklearn的架构见下图:


基本上,这篇文章的工作覆盖了Auto ML的所有环节,其输入就是训练集(含标签)、测试集、资源预算b(计划花费多少时间来学习)、损失函数L(目标函数)。然而在实际中,它主要被用于模型的选择和模型超参的选择。框架内的贝叶斯优化很重要,它是基于模型的非梯度下降优化方法,但不是本文的创新点。这里简单介绍一下。
贝叶斯优化的原理是利用现有的样本在优化目标函数中的表现,构建一个后验模型。该后验模型上的每一个点都是一个高斯分布,即有均值和方差。若该点是已有样本点,则均值就是该点的优化目标函数取值,方差为0。而其他未知样本点的均值和方差是后验概率拟合的,不一定接近真实值。那么就用一个采集函数,不断试探这些未知样本点对应的优化目标函数值,不断更新后验概率的模型。由于采集函数可以兼顾Explore/Exploit,所以会更多地选择表现好的点和潜力大的点。因此,在资源预算耗尽时,往往能够得到不错的优化结果。即找到局部最优的优化目标函数中的参数。见下图:
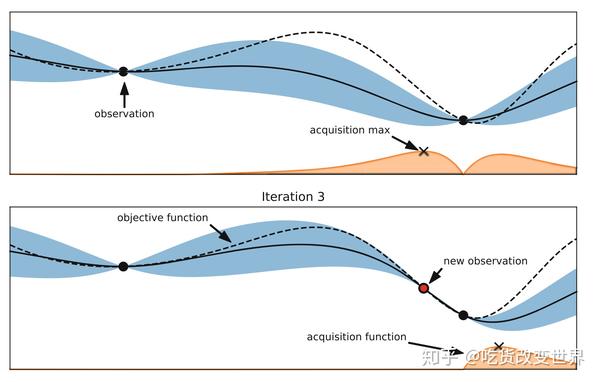

图中,横坐标为优化目标函数的参数,纵坐标为优化目标函数值。虚线为真实的优化目标函数,实线为后验概率模型。可以看出,在已知优化目标函数的参数位置,后验概率与真实目标函数值是重合的,且方差为0,即对该结果的不确定程度是0。而方差大的蓝色区域,表示后验拟合的不确定程度高。而下方黄色区域是采集函数的曲线。采集函数可以有多种策略,只要兼顾利用已有信息——后验中的最佳,和对方差大的潜力区域的探索,就能让优化目标函数的最优取值更快收敛。
举一个Auto Sklearn利用贝叶斯优化的具体例子。假设在训练分类模型时,指定只用XGBoost,但是XGBoost有很多超参数,例如树高限制、迭代次数限制、学习率等。如果用Grid-search,那么就需要将所有取值进行离散化,然后组合进行尝试,搜索空间非常大,是一种暴力搜索方式,非常耗费资源。而贝叶斯优化相当于在搜索的过程中,根据已经搜索的参数组合,构建了一个后验概率模型,这个模型拟合了损失函数(优化目标函数)在不同超参组合上的表现。这个后验概率就探索最优解的过程提供了一定依据,在兼顾探索和利用的情况下,通常能够更快的收敛,即找到一组不错的超参组合,让loss最小。而且,不论超参是离散还是连续的,都可以直接进行搜索,而不像Grid Search那样需要先离散化。
本文采用的方法:
1. MI-SMBO
SMBO(Sequential Model-based Bayesian Optimization)就是上面提到的贝叶斯优化,sequential是指新的待探索样本是基于前面的可行解搜索结果的。SMBO算法如下:




其中,f为k-fold交叉验证的Loss函数,loss函数以超参组合θ为参数,优化的目标就是让Loss最小化。
该算法的核心思路就是先初始化 \theta_{1}......\theta_{t} t个超参配置(组合),通常是随机化的。然后基于这些θ得到的f值构建后验模型M,然后基于M上的采集函数a,选择下一个待尝试的超参配置。最后,计算这个采集出的超参配置对应的f值,并将其补充到已知超参配置的集合中。在下一轮循环,会根据加入的超参配置及f值,更新后验概率M。不断循环,直到达到迭代总次数T(资源预算)。结束循环后,从探索过的所有超参配置中,选择让Loss最小的超参配置返回。
本文的创新点就是在初始化 \theta_{1}......\theta_{t} t个超参配置时,不是随机进行配置,而是采用了元学习meta learning,见下图。


所谓Meta-Learning,就是将之前数据集上训练的超参配置和效果作为经验进行学习,以指导新数据集上的超参初始化。也就是,如果两个数据集在一些特征上很类似,例如都是图片集,图片大小和数量接近,而且任务都是分类,那么我们有理由相信第一个数据集上配置的较成功的超参组合,对第二个数据集也是不错的。在对第二个数据集进行SMBO时,将其初始化的超参选择为历史上第一个数据集中表现不错的超参配置,那么第二个数据集的SMBO可能收敛更快,从而在相同资源预算的情况下会用更多的资源去探索更高质量的超参配置。
因此,上面算法的第1步实际上是在对历史上训练过的数据集与待训练的新数据集的相似程度进行排序。具体地,
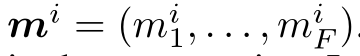
数据集i还有F个元特征,形成了一个向量mi。这个元特征向量之间的距离,就表示了两个数据集的相似程度,如下所示:
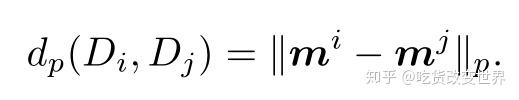

其中,dp表示向量相减的p范式。
最后,再解释一下这些元特征是什么,见下图。
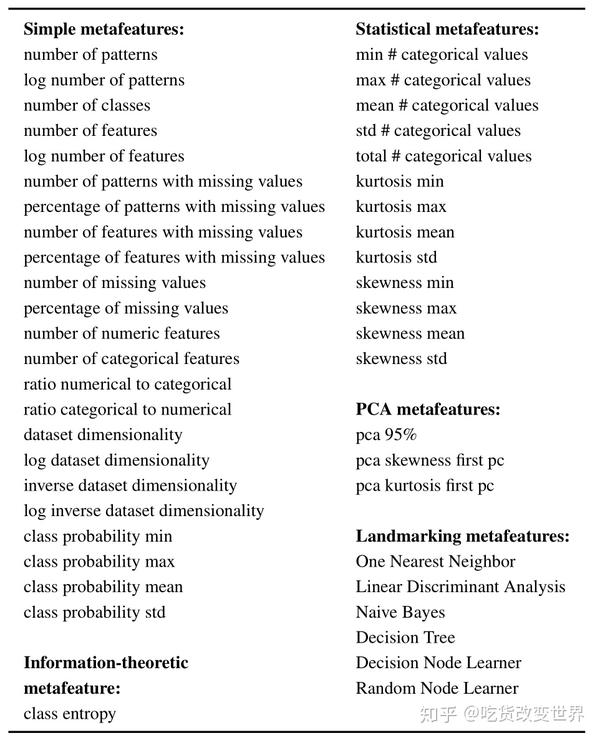

2. Ensemble Selection
Ensemble Selection的思想非常好理解,其本质就是觉得在模型选择和超参选择的Bayeisan优化过程中,如果只给出一个最优的结果,就浪费了其他也较好的结果。因此,这篇文章提出了用一种贪心策略,将验证效果最好的模型和参数组合一起加到集成模型中。即每次加入新模型,都要最大化集成模型的验证性能。要注意的是,在加入新模型时,都是以相同的权重加入的,但是同一个模型和超参配置可以添加多次,因此会造成事实上的不同模型和超参组合的权重是不同的。
3. Auto Sklearn可搜索优化的部分
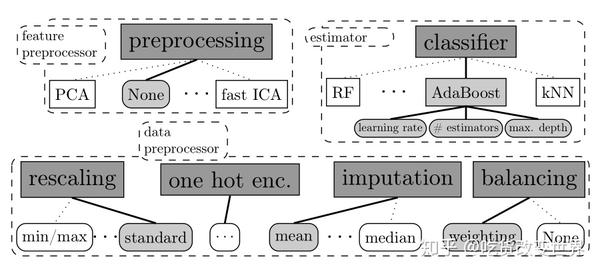

评价
这篇论文提出的Auto-Sklearn是AutoML领域的重要工作之一,已经被广泛应用在模型选择和超参选择方面。但是Auto-Sklearn目前仅在中小数据集和中小任务中表现较好,对于大量数据集是难以应用的。毕竟就算有Bayesian优化来加快模型选择和超参选择过程的收敛,但是每次验证一个模型和超参组合仍然是非常耗费资源的,所以大数据集上Auto-Sklearn尚无法胜任。
总结
这篇文章提出了Auto-Sklearn的架构和技术,包括在SMBO过程中引入Meta-Learning,在模型输出时采用了集成模型,充分利用了之前模型选择和超参选择时的探索结果。因此,它符合了Auto-ML的初衷,减小人工干预,并在给定资源预算的情况下得到更好的结果。Meta-learning提高了SMBO初始值的质量,使更多的资源用于探索更好的可行解。集成模型的使用,使得之前的搜索结果没有被浪费,进一步提高了模型的泛化性,这对于小数据集是非常有效的。
