|
|
|


在Notebook中执行交互式PySpark任务时往往需要借助Python第三方库来增强数据处理和分析能力。本文将以三种方式为您介绍如何在Notebook中安装Python第三方库。
背景信息
在交互式PySpark开发过程中,可以使用Python第三方库以提升数据处理与分析的灵活性及易用性。以下三种方式均能帮助您实现这一目标,建议根据实际情况选择最适合的方式。
|
方式 |
适用场景 |
|
在Notebook中处理与Spark无关的变量,例如处理通过Spark计算得到的返回值或是自定义的变量等。
重要
重启Notebook会话后需要重新安装这些库。 |
|
|
需要在PySpark中使用Python第三方库处理数据,且希望Notebook会话在每次启动时都能默认预装这些第三方库。 |
|
|
需要在PySpark中使用Python第三方库处理数据的场景,例如使用Python第三方库进行Spark分布式计算。 |
前提条件
-
已创建工作空间,详情请参见 创建工作空间 。
-
已创建Notebook会话,详情请参见 管理Notebook会话 。
-
已创建Notebook开发,详情请参见 Notebook开发 。
操作流程
方式一:使用pip安装 Python库
-
进入Notebook开发页面。
-
登录 E-MapReduce控制台 。
-
在左侧导航栏,选择 。
-
在 Spark 页面,单击目标工作空间名称。
-
在 EMR Serverless Spark 页面,单击左侧导航栏中的 数据开发 。
-
双击已创建的Notebook开发。
-
-
在一个Notebook的Python单元格中,输入以下命令安装scikit-learn库,然后单击
 图标。
图标。
pip install scikit-learn -
在一个Notebook的Python单元格中,输入以下命令,然后单击
图标。
# 导入库并准备相关数据集。 from sklearn import datasets # 加载内置的数据集,例如Iris数据集。 iris = datasets.load_iris() X = iris.data # 特征数据 y = iris.target # 标签 # 划分数据集。 from sklearn.model_selection import train_test_split # 划分训练集和测试集。 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42) # 使用向量机模型进行训练。 from sklearn.svm import SVC # 创建分类器实例。 clf = SVC(kernel='linear') # 使用线性核。 # 训练模型。 clf.fit(X_train, y_train) # 使用训练好的模型进行预测。 y_pred = clf.predict(X_test) # 评估模型性能。 from sklearn.metrics import classification_report, accuracy_score print(classification_report(y_test, y_pred)) print("Accuracy:", accuracy_score(y_test, y_pred))执行结果如下所示。
方式二:通过运行环境管理配置自定义Python环境
步骤一:创建运行环境
-
进入运行环境管理页面。
-
登录 E-MapReduce控制台 。
-
在左侧导航栏,选择 。
-
在 Spark 页面,单击目标工作空间名称。
-
在 EMR Serverless Spark 页面,选择左侧导航栏中的 运行环境管理 。
-
-
单击 创建运行环境 。
-
在 创建运行环境 页面,单击 添加库 。
更多参数信息,请参见 管理运行环境 。
-
在 新建库 中,使用 PyPI 来源类型,配置 PyPI Package 参数,然后单击 确定 。
在 PyPI Package 中填写库的名称及版本,不指定版本时,默认安装最新版本。例如,
scikit-learn。 -
单击 创建 。
创建后将开始初始化环境。
步骤二:使用运行环境
说明
在编辑会话之前,您需要先停止会话。
-
进入Notebook会话页签。
-
在 EMR Serverless Spark 页面,选择左侧导航栏中的 。
-
单击 Notebook会话 页签。
-
-
单击目标Notebook会话操作列的 编辑 。
-
在 运行环境 下拉列表中选择前一步骤创建的运行环境,单击 保存更改 。
-
单击右上角的 启动 。
步骤三: 利用Scikit-learn库进行数据分类
-
进入Notebook开发页面。
-
在 EMR Serverless Spark 页面,单击左侧导航栏中的 数据开发 。
-
双击已创建的Notebook开发。
-
-
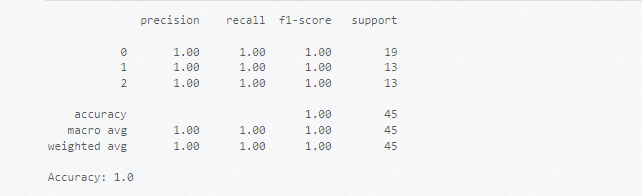
在一个Notebook的Python单元格中,输入以下命令,然后单击
图标。
# 导入库并准备相关数据集。 from sklearn import datasets # 加载内置的数据集,例如Iris数据集。 iris = datasets.load_iris() X = iris.data # 特征数据 y = iris.target # 标签 # 划分数据集。 from sklearn.model_selection import train_test_split # 划分训练集和测试集。 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42) # 使用向量机模型进行训练。 from sklearn.svm import SVC # 创建分类器实例。 clf = SVC(kernel='linear') # 使用线性核。 # 训练模型。 clf.fit(X_train, y_train) # 使用训练好的模型进行预测。 y_pred = clf.predict(X_test) # 评估模型性能。 from sklearn.metrics import classification_report, accuracy_score print(classification_report(y_test, y_pred)) print("Accuracy:", accuracy_score(y_test, y_pred))执行结果如下所示。
方式三:通过Spark参数配置自定义Python环境
在使用该方式时,需确保已安装ipykernel和jupyter_client,并且ipykernel的版本应不低于6.29,jupyter_client的版本应不低于8.6,Python版本需不低于3.8,且需在Linux环境下进行打包。
步骤一:Conda环境构建与部署
-
通过以下命令安装Miniconda。
wget https://repo.continuum.io/miniconda/Miniconda3-latest-Linux-x86_64.sh chmod +x Miniconda3-latest-Linux-x86_64.sh ./Miniconda3-latest-Linux-x86_64.sh -b source miniconda3/bin/activate -
构建使用Python 3.8和numpy的Conda环境。
# 创建并激活conda环境 conda create -y -n pyspark_conda_env python=3.8 conda activate pyspark_conda_env # 安装第三方库 pip install numpy \ ipykernel~=6.29 \ jupyter_client~=8.6 \ jieba \ conda-pack # 打包环境 conda pack -f -o pyspark_conda_env.tar.gz
步骤二:上传资源文件至OSS
上传打包好的
pyspark_conda_env.tar.gz
至阿里云OSS,并记录下完整的OSS路径,上传操作可以参见
简单上传
。
步骤三: 配置并启动Notebook会话
说明
在编辑会话之前,您需要先停止会话。
-
进入Notebook会话页签。
-
在 EMR Serverless Spark 页面,选择左侧导航栏中的 。
-
单击 Notebook会话 页签。
-
-
单击目标Notebook会话操作列的 编辑 。
-
在 Spark配置 中,添加以下配置信息,单击 保存更改 。
spark.archives oss://<yourBucket>/path/to/pyspark_conda_env.tar.gz#env spark.pyspark.python ./env/bin/python说明配置中的
<yourBucket>/path/to,请替换为您实际的OSS上传路径。 -
单击右上角的 启动 。
步骤四:利用Jieba分词处理文本数据
说明
Jieba是一个中文文本分词Python第三方库,其开源许可证请参见 LICENSE 。
-
进入Notebook开发页面。
-
在 EMR Serverless Spark 页面,单击左侧导航栏中的 数据开发 。
-
双击已创建的Notebook开发。
-
-
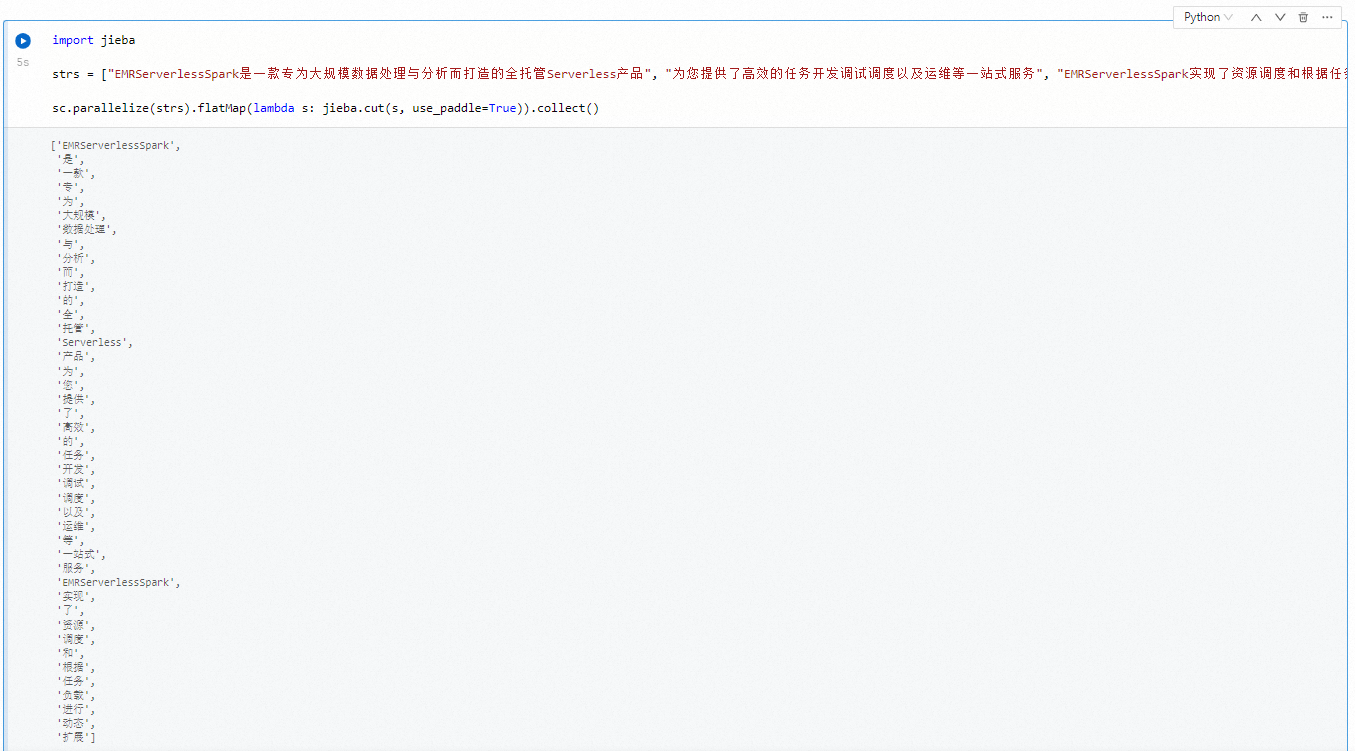
在新的一个Python单元格中,输入以下命令以使用Jieba进行中文分词,然后单击
图标。
import jieba strs = ["EMRServerlessSpark是一款专为大规模数据处理与分析而打造的全托管Serverless产品", "为您提供了高效的任务开发调试调度以及运维等一站式服务", "EMRServerlessSpark实现了资源调度和根据任务负载进行动态扩展"] sc.parallelize(strs).flatMap(lambda s: jieba.cut(s, use_paddle=True)).collect()执行结果如下所示。