为预防模型过拟合,我们可以采用预剪枝和后剪枝方法
1. 预剪枝:树构建过程,达到一定条件就停止生长
2. 后剪枝是等树完全构建后,再剪掉一些节点。
本文讲述后剪枝
,预剪枝请参考《
sklearn决策树预剪枝
》
一.CCP后剪枝简介
后剪枝一般指的是CCP代价复杂度剪枝法(Cost Complexity Pruning),
即在树构建完成后,对树进行剪枝简化,使以下损失函数最小化:
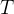 :叶子节点个数
:叶子节点个数
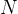 :所有样本个数
:所有样本个数
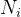 :第 i 个叶子节点上的样本数
:第 i 个叶子节点上的样本数
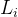 :第i个叶子节点的损失函数
:第i个叶子节点的损失函数
α :待定系数,用于惩罚节点个数,引导模型用更少的节点。
损失函数既考虑了代价,又考虑了树的复杂度,所以叫代价复杂度剪枝法,实质就是在树的复杂度与准确性之间取得一个平衡点。
备注:在sklearn中,如果criterion设为GINI,则是
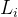 每个叶子节点的GINI系数,如果设为entropy,则是熵。
每个叶子节点的GINI系数,如果设为entropy,则是熵。
二.剪枝操作过程
具体操作过程如下:
(1) 查看CCP路径
计算CCP路径,查看alpha与树质量的关系:
构建好树后,我们可以通过clf.cost_complexity_pruning_path(X, y) 查看树的CCP路径:
# -*- coding: utf-8 -*-
from sklearn.datasets import load_iris
from sklearn import tree
import numpy as np
#----------------数据准备----------------------------
iris = load_iris() # 加载数据
X = iris.data
y = iris.target
#---------------模型训练---------------------------------
clf = tree.DecisionTreeClassifier(min_samples_split=10,ccp_alpha=0)
clf = clf.fit(X, y)
#-------计算ccp路径-----------------------
pruning_path = clf.cost_complexity_pruning_path(X, y)
#-------打印结果---------------------------
print("\n====CCP路径=================")
print("ccp_alphas:",pruning_path['ccp_alphas'])
print("impurities:",pruning_path['impurities'])
运行结果:
====sklearn的CCP路径=================
ccp_alphas: [0. 0.00415459 0.01305556 0.02966049 0.25979603 0.33333333]
impurities: [0.02666667 0.03082126 0.04387681 0.07353731 0.33333333 0.66666667]
它的意思是:
0<\alphaα <0.00415时,树的不纯度为 0.02666,
0.00415<\alphaα <0.01305时,树的不纯度为 0.03082,
0.01305<\alphaα <0.02966时,树的不纯度为 0.04387,
........
小贴士:ccp_path只提供树的不纯度,如果还需要alpha对应的其它信息,则可以将alpha代入模型中训练,从训练好的模型中获取。
备注:树的不纯度指的是损失函数的前部分
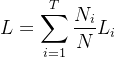 , 也即所有叶子的不纯度(gini或者熵)加权和。
, 也即所有叶子的不纯度(gini或者熵)加权和。
(2)根据CCP路径剪树
根据树的质量,选定alpha进行剪树
我们选择一个可以接受的树不纯度,找到对应的alpha,例如,我们可接受的树不纯度为0.0735,则alpha可设为0.1(在0.02966与0.25979之间)
对模型重新以参数ccp_alpha=0.1进行训练,即可得到剪枝后的决策树。
完整代码如下:
# -*- coding: utf-8 -*-
from sklearn.datasets import load_iris
from sklearn import tree
import numpy as np
#--------数据准备-----------------------------------
iris = load_iris() # 加载数据
X = iris.data
y = iris.target
#-------模型训练---------------------------------
clf = tree.DecisionTreeClassifier(min_samples_split=10,random_state=0,ccp_alpha=0)
clf = clf.fit(X, y)
#-------计算ccp路径------------------------------
pruning_path = clf.cost_complexity_pruning_path(X, y)
#-------打印结果---------------------------------
print("\n====CCP路径=================")
print("ccp_alphas:",pruning_path['ccp_alphas'])
print("impurities:",pruning_path['impurities'])
#------设置alpha对树后剪枝-----------------------
clf = tree.DecisionTreeClassifier(min_samples_split=10,random_state=0,ccp_alpha=0.1)
clf = clf.fit(X, y)
#------自行计算树纯度以验证-----------------------
is_leaf =clf.tree_.children_left ==-1
tree_impurities = (clf.tree_.impurity[is_leaf]* clf.tree_.n_node_samples[is_leaf]/len(y)).sum()
#-------打印结果---------------------------
print("\n==设置alpha=0.1剪枝后的树纯度:=========\n",tree_impurities)
运行结果:
====CCP路径=================
ccp_alphas: [0. 0.00415459 0.01305556 0.02966049 0.25979603 0.33333333]
impurities: [0.02666667 0.03082126 0.04387681 0.07353731 0.33333333 0.66666667]
==设置alpha=0.1剪枝后的树纯度:=========
0.0735373054213634
对于CCP路径的计算过程,可参考:
1.《
决策树后剪枝原理:CCP剪枝法
》
2.《
决策树(sklearn)中CCP路径计算的实现方式.py
》
《
深入浅出:决策树入门简介
》
《
一个简单的决策树分类例子
》
《
sklearn决策树结果可视化
》
《
sklearn决策树参数详解
》
《老饼讲解机器学习》http://ml.bbbdata.com/teach#103目录一.CCP后剪枝简介二.剪枝操作过程(1)查看CCP路径(2)根据CCP路径剪树为预防模型过拟合,我们可以采用预剪枝和后剪枝方法1. 预剪枝:树构建过程,达到一定条件就停止生长2. 后剪枝是等树完全构建后,再剪掉一些节点。本文讲述后剪枝,预剪枝请参考《sklearn决策树预剪枝》一.CCP后剪枝简介后剪枝一般指的是CCP代价复杂度剪枝法(Cost Complexity Prun.
path = clf.cost_complexity_pruning_path(Xtrain, Ytrain)
#cost_complexity_pruning_path:返回两个参数,
#第一个是CCP
剪枝
后
决策树
序列T0,T1,...,Tt对应的误差率增益率α;第二个是
剪枝
后
决策树
所有叶子节点的不纯度
ccp_alphas, im
在不加限制的情况下,一棵
决策树
会生长到衡量不纯度的指标最优,或者没有更多的特征可用为止。这样的
决策树
往往会过拟合,这就是说,它会在训练集上表现很好,在测试集上却表现糟糕。我们收集的样本数据不可能和整体的状况完全一致,因此当一棵
决策树
对训练数据有了了过于优秀的解释性,它找出的规则必然包含了训练样本中的噪声,并使它对未知数据的拟合程度不足。
为了让
决策树
有更好的泛化性,我们要对
决策树
进行
剪枝
。
剪枝
策略...
图1 未
剪枝
前的
决策树
基于上图,后
剪枝
首先考虑纹理,若将其领衔的分支剪除,则相当于把纹理替换成叶节点,替换后的叶节点包含编号{7,15},于是,该叶节点的类别标记为“好瓜”,此时
决策树
验证集的精确度提升至57.1%。于是后
剪枝
策略决定
剪枝
。
机器学习
sklearn
——
决策树
剪枝
什么是
剪枝
?为甚么要
剪枝
?怎样
剪枝
?(1)REP—错误率降低
剪枝
(2)PEP—悲观
剪枝
算例:
什么是
剪枝
?
剪枝
是指将一颗子树的子节点全部删掉,根节点作为叶子节点,以下图为例:
为甚么要
剪枝
?
决策树
是充分考虑了所有的数据点而生成的复杂树,有可能出现过拟合的情况,
决策树
越复杂,过拟合的程度会越高。
考虑极端的情况,如果我们令所有的叶子节点都只含有一个数据点,那...
剪枝
理论学习请参考如下网址:机器学习算法——
决策树
4(
剪枝
处理)_Vicky_xiduoduo的博客-CSDN博客_
剪枝
机器学习
不管是预
剪枝
还是后
剪枝
,都需要对
决策树
进行“泛化能力”的评估。本节的实例
讲
解采用留出法评估
决策树
的泛化能力。故需要预留一部分数据用作“训练集”,一部分用作“验证集/测试集”。将西瓜2.0数据集随机划分成两部分,如下表所示。
表1 西瓜数据集2.0划分出的训练集
sklearn
中的
决策树
模块提供了多种功能和方法来构建和使用
决策树
。其中,可以使用tree.DecisionTreeClassifier来构建分类树,使用tree.DecisionTreeRegressor来构建回归树。还可以使用tree.export_graphviz将生成的
决策树
导出为DOT格式,以便进行可视化。此外,还有tree.ExtraTreeClassifier和tree.ExtraTreeRegressor等高随机版本的分类树和回归树可供选择。\[2\]
在不加限制的情况下,
决策树
会生长到衡量不纯度的指标最优,或者没有更多的特征可用为止。然而,这样的
决策树
往往会过拟合,即在训练集上表现很好,但在测试集上表现糟糕。为了避免过拟合,我们需要对
决策树
进行
剪枝
。
剪枝
策略对
决策树
的泛化性能有很大影响,选择正确的
剪枝
策略是优化
决策树
算法的关键。
sklearn
提供了不同的
剪枝
策略供我们选择和使用。\[3\]
#### 引用[.reference_title]
- *1* *2* [
sklearn
(一)、
决策树
](https://blog.csdn.net/weixin_44784088/article/details/124789687)[target="_blank" data-report-click={"spm":"1018.2226.3001.9630","extra":{"utm_source":"vip_chatgpt_common_search_pc_result","utm_medium":"distribute.pc_search_result.none-task-cask-2~all~insert_cask~default-1-null.142^v91^koosearch_v1,239^v3^insert_chatgpt"}} ] [.reference_item]
- *3* [机器学习
sklearn
-
决策树
](https://blog.csdn.net/kongqing23/article/details/122394210)[target="_blank" data-report-click={"spm":"1018.2226.3001.9630","extra":{"utm_source":"vip_chatgpt_common_search_pc_result","utm_medium":"distribute.pc_search_result.none-task-cask-2~all~insert_cask~default-1-null.142^v91^koosearch_v1,239^v3^insert_chatgpt"}} ] [.reference_item]
[ .reference_list ]

