

python下载b站音频视频

# 一.找到视频链接存储的地方 找到需要爬取的视频,我选用我自己的b站视频(小声bb,大家可以关注以下,嘻嘻嘻) 爬取的视频地址
查看页面源代码,经过查找可以发现视频在“playinfo”处,图片并不完整,大家可以自行搜取:


二.python下载
1.导入库
import pprint
import requests
import re
import json2.请求页面,找到数据
session = requests.session()
url = 'https://www.bilibili.com/video/BV13E411A77B'
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36 Edg/106.0.1370.37',
"Referer": "https://www.bilibili.com",
resp = session.get(url,headers=headers)
# print(resp.text)利用session代替requests进行请求,session可以认为是一连串的请求,在这个过程中的cookie不会丢失。 referer代表防盗链,请求头中没有这一项将请求不到内容。防盗链可以在抓包工具中查找
3.数据解析
title = re.findall(r'<title data-vue-meta="true">(.*?)_哔哩哔哩_bilibili',resp.text)[0]
play_info = re.findall(r'<script>window.__playinfo__=(.*?)</script>',resp.text)[0]
'''print(title)
print(play_info,type(play_info)) '''
json_data = json.loads(play_info)
pprint.pprint(json_data) #格式化输出,便于观看
audio_url = json_data['data']['dash']['audio'][0]['backupUrl'][0] #音频地址 [0]清晰度最高
video_url = json_data['data']['dash']['video'][0]['backupUrl'][0] #视频地址请求到页面源代码后,解析提取“playinfo”即视频链接项,使用正则表达式(python中re库)进行提取。
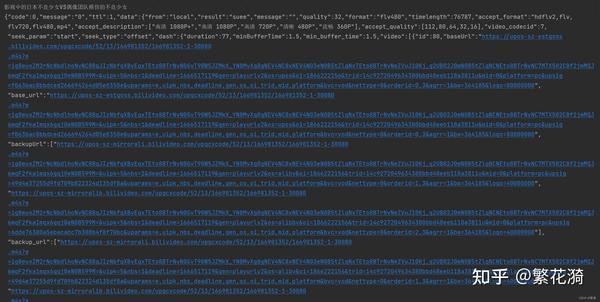

利用json库将提取数据转化为字典数据,并利用pprint库进行格式化输出进行分析
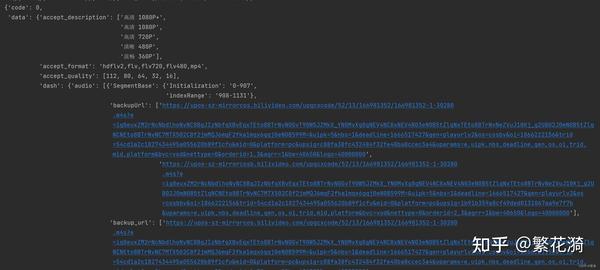

(注意!!!上述两图由于数据多只截取开头一部分) 有我们分析,数据中包含视频和音频两种内容,故b站的视频和音频是分开的,我们都要下载下来,然后用其他工具合成。 上面已经把提取数据转化为字典,然后利用字典找到音频audio_url 和视频地址video_url。
4.音频视频下载
audio_content = session.get(audio_url,headers=headers).content #音频二进制内容
video_content = session.get(video_url,headers=headers).content #视频二进制内容
with open(r'D:\python\python_study\爬虫练习\video/'+title+'.mp3','wb') as f:
f.write(audio_content)
with open(r'D:\python\python_study\爬虫练习\video/'+title+'.mp4','wb') as f:
f.write(video_content)请求音频和视频地址,并下载下来。

嘿嘿嘿!!!下载完毕!!!
三.python完整代码
import pprint
import requests
import re
import json
session = requests.session()
url = 'https://www.bilibili.com/video/BV13E411A77B'
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36 Edg/106.0.1370.37',
"Referer": "https://www.bilibili.com",
resp = session.get(url,headers=headers)
#print(resp.text)
title = re.findall(r'<title data-vue-meta="true">(.*?)_哔哩哔哩_bilibili',resp.text)[0]
play_info = re.findall(r'<script>window.__playinfo__=(.*?)</script>',resp.text)[0]
'''print(title)
print(play_info,type(play_info)) '''
json_data = json.loads(play_info)
#pprint.pprint(json_data) #格式化输出,便于观看
#print(type(json_data))
audio_url = json_data['data']['dash']['audio'][0]['backupUrl'][0] #音频地址 [0]清晰度最高
video_url = json_data['data']['dash']['video'][0]['backupUrl'][0] #视频地址