明白了for()循环和foreach()循环对于数组结构和链表结构遍历时的效率差别后,可以对示例中average方法进行一下小改进,以便实现不同的列表采用不同的遍历方式,代码如下:
* 求平均数
* @param scores 分数集合
* @return
本文实例分析了js的for in
循环和
java里
foreach循环的区别。分享给大家供大家参考。具体分析如下:
js里的for in
循环定义如下:
代码如下:for(var variable in obj) { … }
obj可以是一个普通的js对象或者一个数组。如果obj是js对象,那么variable在遍历中得到的是对象的属性的名字,而不是属性对应的值。如果obj是数组,那么variable在遍历中得到的是数组的下标。
遍历对象实验:
代码如下:var v = {};
v.field1 = “a”;
v.field2 = “b”;
for(var v in v) {
专栏原创出处:github-源笔记文件 ,github-源码 ,欢迎 Star,转载请附上原文出处链接和本声明。
Java 核心知识专栏系列笔记,系统性学习可访问个人复盘笔记-技术博客 Java 核心知识
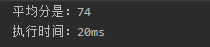
本节内容主要研究 for、foreach 循环的底层实现原理,再比较两种实现方式的性能。最后通过 RandomAccess 接口说明 JDK 让我们怎么去识别集合是否支持随机访...
foreach
从Java 5之后,Java提供了一种更简单的循环:foreach循环,这种循环遍历数组和集合更加简洁。使用foreach循环遍历数组和集合元素时,无需获得数组和集合长度,无需根据索引来访问数组元素和集合元素,foreach循环自动遍历数组和集合的每个元素。
foreach是for语句的简化,但是foreach并不能代替for循环。可以这么说,任何f
publicstaticvoidmain(String[]args){
LongstartTime=System.currentTimeMillis();
formMethod();
LongendTime=System.currentTimeMillis();...