


利用Transformer建立时间序列预测模型(附代码)


作者小猴子
欢迎关注 @机器学习社区 ,专注学术论文、机器学习、人工智能、Python技巧
大家好,今天给大家分享一篇非常有趣的论文: Deep Transformer Models for Time Series Forecasting: The Influenza Prevalence Case 。这是一篇有关时间序列入门级论文,从头开始实现一个有趣的时间序列项目,可以帮助我们了解更多关于时间序列预测。
接下来我们就通过自己生成一些数据,复现该论文中所提到的利用Transformer建立时间序列预测模型。 喜欢记得关注、点赞、收藏。
完整代码已打包,文末欢迎加入技术交流、资料获取


论文地址: https:// arxiv.org/pdf/2001.0831 7.pdf
模型架构
本文中使用的模型是一个传统基于
编码器-解码器的Transformer
,其中编码器部分将时间序列的历史作为输入,而解码器部分以自回归的方式预测未来的值。
首先初始化模型
该部分初始化一些参数,定义输入输出的编码器和解码器等操作。
def __init__(
self,
n_encoder_inputs,
n_decoder_inputs,
channels=512,
dropout=0.1,
lr=1e-4,
super().__init__()
self.save_hyperparameters()
self.lr = lr
self.dropout = dropout
self.input_pos_embedding = torch.nn.Embedding(1024, embedding_dim=channels)
self.target_pos_embedding = torch.nn.Embedding(1024, embedding_dim=channels)
encoder_layer = nn.TransformerEncoderLayer(
d_model=channels,
nhead=8,
dropout=self.dropout,
dim_feedforward=4 * channels,
decoder_layer = nn.TransformerDecoderLayer(
d_model=channels,
nhead=8,
dropout=self.dropout,
dim_feedforward=4 * channels,
self.encoder = torch.nn.TransformerEncoder(encoder_layer, num_layers=8)
self.decoder = torch.nn.TransformerDecoder(decoder_layer, num_layers=8)
self.input_projection = Linear(n_encoder_inputs, channels)
self.output_projection = Linear(n_decoder_inputs, channels)
self.linear = Linear(channels, 1)
self.do = nn.Dropout(p=self.dropout)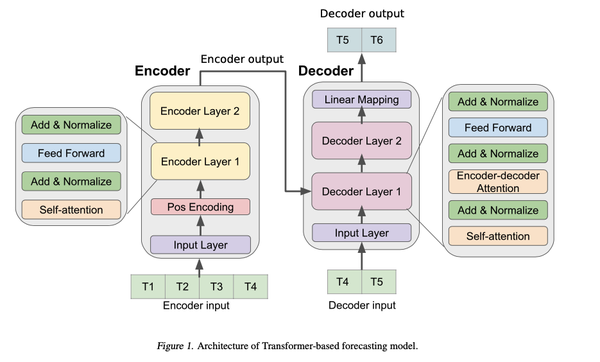
模型架构
解码器使用注意力机制与编码器连接。通过这种方式,解码器可以学习在做出预测之前“关注”时间序列历史值中最有用的部分。
解码器使用了掩蔽的自注意力,这样网络就不会在训练期间获取未来的值,不会导致信息的泄露。
编码器
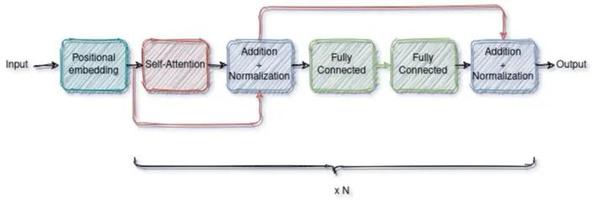
编码器由输入层、位置编码层和四个相同编码器层的堆栈组成。输入层将输入时间序列数据通过全连接网络映射到一个向量维模型。这一步对于模型采用多头注意机制是至关重要的。利用正弦和余弦函数的位置编码,通过将输入向量与位置编码向量按元素顺序相加,对时间序列数据中的顺序信息进行编码。所得的矢量被送入四个编码器层。每个编码器层包括两个子层:自注意子层和全连接的前馈子层。每个子层后面都有一个规范化层。编码器产生一个dmodel维向量来提供给解码器。
def encode_src(self, src):
src_start = self.input_projection(src).permute(1, 0, 2)
in_sequence_len, batch_size = src_start.size(0), src_start.size(1)
pos_encoder = (
torch.arange(0, in_sequence_len, device=src.device)
.unsqueeze(0)
.repeat(batch_size, 1)
pos_encoder = self.input_pos_embedding(pos_encoder).permute(1, 0, 2)
src = src_start + pos_encoder
src = self.encoder(src) + src_start
return src解码器
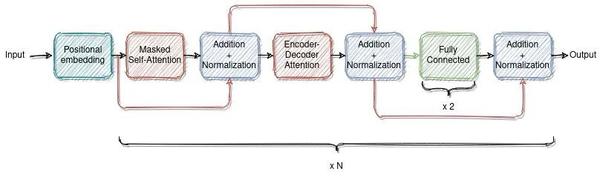
采用了类似于原始Transformer架构的解码器设计。解码器还由输入层、四个同频解码层和一个输出层组成。解码器输入从编码器输入的最后一个数据点开始。输入层将解码器输入映射到一个dmodel维向量。除了每个编码器层中的两个子层之外,解码器插入第三个子层以在编码器输出上应用自注意机制。最后,有一个输出层,它将上一解码器层的输出映射到目标时间序列。我们在解码器的输入和目标输出之间使用前向掩蔽和一位置偏移,以确保对时间序列数据点的预测只依赖于之前的数据点。
def decode_trg(self, trg, memory):
trg_start = self.output_projection(trg).permute(1, 0, 2)
out_sequence_len, batch_size = trg_start.size(0), trg_start.size(1)
pos_decoder = (
torch.arange(0, out_sequence_len, device=trg.device)
.unsqueeze(0)
.repeat(batch_size, 1)
pos_decoder = self.target_pos_embedding(pos_decoder).permute(1, 0, 2)
trg = pos_decoder + trg_start
trg_mask = gen_trg_mask(out_sequence_len, trg.device)
out = self.decoder(tgt=trg, memory=memory, tgt_mask=trg_mask) + trg_start
out = out.permute(1, 0, 2)
out = self.linear(out)
return out
def gen_trg_mask(length, device):
mask = torch.tril(torch.ones(length, length, device=device)) == 1
mask = (
mask.float()
.masked_fill(mask == 0, float("-inf"))
.masked_fill(mask == 1, float(0.0))
return mask
编码器-解码器
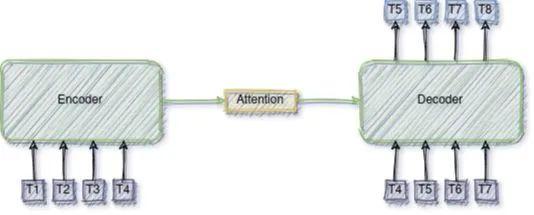
forward函数定义
def forward(self, x):
src, trg = x
src = self.encode_src(src)
out = self.decode_trg(trg=trg, memory=src)
return out⚠精华内容:
这个架构可以通过以下方式使用PyTorch构建:
encoder_layer = nn.TransformerEncoderLayer(
d_model=channels,
nhead=8,
dropout=self.dropout,
dim_feedforward=4 * channels,
decoder_layer = nn.TransformerDecoderLayer(
d_model=channels,
nhead=8,
dropout=self.dropout,
dim_feedforward=4 * channels,
self.encoder = torch.nn.TransformerEncoder(encoder_layer,
num_layers=8)
self.decoder = torch.nn.TransformerDecoder(decoder_layer,
num_layers=8)接下来对该部分内容进行更近一步的解析。
数据
数据生成及预处理
每当我实现一种新方法时,我喜欢首先在合成数据上尝试它,以便更容易理解和调试。这降低了数据的复杂性,并将重点更多地放在实现/算法上。
def add_date_cols(dataframe: pd.DataFrame, date_col: str = "timestamp"):
# add time features like month, week of the year ...
dataframe[date_col] = pd.to_datetime(dataframe[date_col], format="%Y-%m-%d")
dataframe["day_of_month"] = dataframe[date_col].dt.day / 31
dataframe["day_of_year"] = dataframe[date_col].dt.dayofyear / 365
dataframe["month"] = dataframe[date_col].dt.month / 12
dataframe["week_of_year"] = dataframe[date_col].dt.isocalendar().week / 53
dataframe["year"] = (dataframe[date_col].dt.year - 2015) / 5
return dataframe, ["day_of_month", "day_of_year",
"month", "week_of_year", "year"]
def add_basic_lag_features(
dataframe: pd.DataFrame,
group_by_cols: List,
col_names: List,
horizons: List,
fill_na=True,):
group_by_data = dataframe.groupby(by=group_by_cols)
new_cols = []
for horizon in horizons:
dataframe[[a + "_lag_%s" % horizon for a in col_names]] = group_by_data[
col_names
].shift(periods=horizon)
new_cols += [a + "_lag_%s" % horizon for a in col_names]
if fill_na:
dataframe[new_cols] = dataframe[new_cols].fillna(0)
return dataframe, new_cols
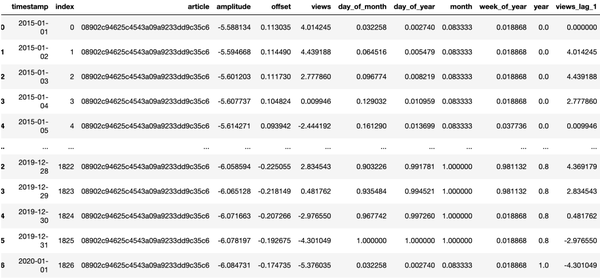
划分训练集和测试集
时间序列训练集的划分同一般数据集划分略有不同,需要将一部分数据作为历史数据,将该历史数据的未来一部分数据作为目标数据。历史数据时间窗定义为history_size,目标数据的时间窗定义为horizon_size。
因此在划分数据集时,同一般做法一样,关键在于需要确定 start_index,label_index,end_index 三个索引值。因此具体做法如下图所示。
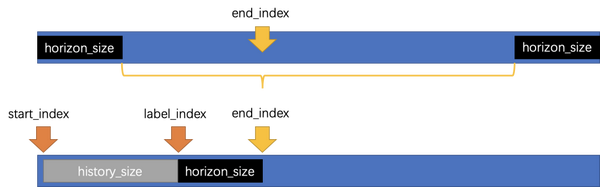
这里重点是在上图黄色大括号中随机选取end_index,并根据其计算 start_index 和 label_index。具体代码如下所示。
def split_df(
df: pd.DataFrame, split: str,
history_size: int = 120,
horizon_size: int = 30
Create a training / validation samples
验证示例是最后的horizon_size行
if split == "train":
end_index = random.randint(horizon_size + 1, df.shape[0] - horizon_size)
elif split in ["val", "test"]:
end_index = df.shape[0]
else:
raise ValueError
label_index = end_index - horizon_size
start_index = max(0, label_index - history_size)
history = df[start_index:label_index]
targets = df[label_index:end_index]
return history, targets构建数据集
这里构建的数据集中有三点细节需要注意:
第一,由于随机选取终止点,因此会导致部分历史数据不足目标值(expected_size = history_size),因此需要进行填充处理。
第二,每次获取一批数据,该批数据是以一个group为批次,即按照article聚合处理的数据。
第三,解码器输入数据的特征,包括目标数据所预测的前一个时刻的目标变量,即数据处理中的
views_lag_1
。它是目标变量
views
向后一天平移所得到的结果。简单来说,对于某天前一天的目标数据是
views_lag_1
,当天的目标数据是
views
。
def pad_arr(arr: np.ndarray, expected_size: int = 120):
# 如果历史数据不够时,需要用0填充
arr = np.pad(arr, [(expected_size - arr.shape[0], 0), (0, 0)], mode="edge")
return arr
def df_to_np(df):
arr = np.array(df)
arr = pad_arr(arr)
return arr
class Dataset(torch.utils.data.Dataset):
def __init__(self, groups, grp_by, split, features, target):
self.groups = groups
self.grp_by = grp_by
self.split = split
self.features = features
self.target = target
def __len__(self):
return len(self.groups)
def __getitem__(self, idx):
group = self.groups[idx]
df = self.grp_by.get_group(group) # 按照一个 article 最为一条数据
src, trg = split_df(df, split=self.split)
src = src[self.features + [self.target]]
src = df_to_np(src)
# src.shape = (120, 6)
trg_in = trg[self.features + [f"{self.target}_lag_1"]]
# 自变量 加上 经过平移 一个 单位 的目标变量
# df.groupby(by="article")["views"].shift(periods=1)
trg_in = np.array(trg_in) # trg_in.shape = (30, 7)
trg_out = np.array(trg[self.target]) # trg_in.shape = (1,)
# 转换为tensor
src = torch.tensor(src, dtype=torch.float)
trg_in = torch.tensor(trg_in, dtype=torch.float)
trg_out = torch.tensor(trg_out, dtype=torch.float)
return src, trg_in, trg_out获取数据集
horizon_size = 30
feature_target_names = {
"features": cols,
"target": "views",
"group_by_key": "article",
"lag_features": ["views_lag_1"], }
# 删除缺失值
data_train = data[~data[feature_target_names["target"]].isna()]
grp_by_train = data_train.groupby(by=feature_target_names["group_by_key"])
groups = list(grp_by_train.groups) # article
full_groups = [
grp for grp in groups if grp_by_train.get_group(grp).shape[0] > 2 * horizon_size]
train_data = Dataset(
groups=full_groups,
grp_by=grp_by_train,
split="train",
features=feature_target_names["features"],
target=feature_target_names["target"])
train_loader = DataLoader(
train_data,
batch_size=batch_size,
num_workers=10,
shuffle=True)训练和验证
def training_step(self, batch, batch_idx):
src, trg_in, trg_out = batch
y_hat = self((src, trg_in))
y_hat = y_hat.view(-1)
y = trg_out.view(-1)
loss = smape_loss(y_hat, y)
self.log("train_loss", loss)
return loss
def validation_step(self, batch, batch_idx):
src, trg_in, trg_out = batch
y_hat = self((src, trg_in))
y_hat = y_hat.view(-1)
y = trg_out.view(-1)
loss = smape_loss(y_hat, y)
self.log("valid_loss", loss)