日常写代码经常会遇到数据统计的业务场景,分组查询 group by 结合 count 和 sum 的复杂语句写起来容易令人头大,在这里分享两个比较复杂的统计场景,提供详细分析思路和最终sql语句,希望能给大家带来帮助。
库表结构如下所示:
学生分数表:student_score
|
字段名
|
含义
|
字段类型
|
备注
|
|
id
|
自增编号
|
bigint
|
|
|
student_name
|
学生姓名
|
varchar
|
|
|
score
|
分数
|
double
|
|
|
sort
|
分数类型
|
int
|
1-加分;2-减分;
|
|
is_delete
|
删除标志位
|
int
|
默认为0;
|
一上来不着急写 sql,先来分析一下:
因为统计的是每个学生的分数,所以根据学生名称 student_name 进行 group by 分组查询。
需要获取的字段包括
学生名称 student_name,加分次数 add_count,扣分次数 sub_count,总加分 add_score,总扣分 sub_score
,其中,学生名称不需要计算,因此只需处理
次数和分数
。
我们知道,count() 主要用于求行的个数累计,所以当分数类型 sort 为 1,则增加加分次数,sort 为 2,则增加扣分次数;而 sum() 用于求和累加,因而使用 sum() 来计算总分,分数类型 sort 为 1,则加分,sort 为 2,则减分。
有了清晰的思路,sql就不难写了:
SELECT
student_name,
count(sort = 1 OR NULL) add_count,
count(sort = 2 OR NULL) sub_count,
sum(IF(sort = 1, score, 0)) add_score,
sum(IF(sort = 2, score, 0)) sub_score
student_score
WHERE
is_delete = 0
GROUP BY
student_name
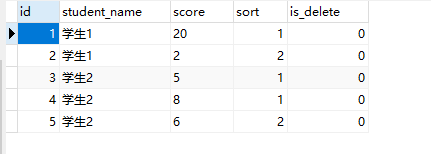
原始表数据:
统计结果:
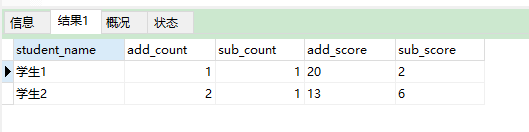
这里的次数和分数的条件判断是通过 if 语句来实现的,我们也可以通过 case when 语句来实现:
SELECT
student_name,
count(case when sort = 1 then 1 else null end) add_count,
count(case when sort = 2 then 1 else null end) sub_count,
sum(case when sort = 1 then score else 0 end) add_score,
sum(case when sort = 2 then score else 0 end) sub_score
student_score
WHERE
is_delete = 0
GROUP BY
student_name
体育测试中我们要根据不同的指标对学生进行打分,目前分为5项指标:800米,50米,立定跳远,仰卧起坐和坐位体前屈。总分为100分,每项的分数权重占比不一样,如下表所示:
| 项目 | 分数占比(%) |
|---|
| 800米 | 30 |
| 50米 | 15 |
| 立定跳远 | 20 |
| 仰卧起坐 | 15 |
| 坐位体前屈 | 20 |
其中立定跳远需要测试3次,每次都进行打分,需要根据这3次的得分计算出平均分作为最终得分,未来其他指标也可能采用这种方式进行打分。
需求明确了,先来设计数据库表,由于每项指标的权重是固定的,可以采用单独一个表来存储指标权重:
指标权重表:index_score
| 字段名 | 含义 | 字段类型 | 备注 |
|---|
| id | 自增编号 | bigint | |
| index_code | 指标编号 | varchar | |
| index_name | 指标名称 | varchar | |
| share | 指标权重 | int | |
| is_delete | 删除标志位 | int | 默认为0; |
由于库表中需要保存全量详细的体测记录,所以需要记录每个学生的指标和对应的评分。这里通过指标编号进行关联,结果记录表如下所示:
结果记录表:score_record
| 字段名 | 含义 | 字段类型 | 备注 |
|---|
| id | 自增编号 | bigint | |
| student_name | 学生名称 | varchar | |
| index_code | 指标编号 | varchar | |
| score | 对应指标得分 | double | |
| is_delete | 删除标志位 | int | 默认为0; |
我们需要通过一个sql关联 指标权重表 和 结果记录表 来获取每个学生的姓名和总得分。这个场景比较复杂,一步一步来分析:
首先先来处理最复杂的立定跳远项,先计算每个学生的3次得分的平均分,由于未来其他指标也可能采用这种方式进行打分,那么我们就要根据学生姓名和指标编号共同进行 group by 分组后再获取平均值:
SELECT
student_name,
index_code,
round(avg(score), 1) index_avg
score_record r
WHERE
r.is_delete = 0
GROUP BY
student_name, index_code
原始表数据:

统计结果:

统计出每个学生的各项指标得分就完成了第一步,第二步需要根据各项指标的权重结合得分计算总分。这就需要结合指标权重表来获取每项指标的权重占比 share,再乘以第一步计算出的平均值 index_avg 后,最后使用 sum() 来计算出总分。
当然这里需要根据学生姓名来进行分组,对于计算出的总分还要使用 round() 函数保留两位小数,最终 sql 如下:
SELECT
round(sum(s.share * t.index_avg) / 100, 2) score, t.student_name
SELECT
student_name,
index_code,
round(avg(score), 1) index_avg
score_record r
WHERE
r.is_delete = 0
GROUP BY
student_name,index_code
LEFT JOIN index_score s ON t.index_code = s.index_code
GROUP BY
t.student_name
统计结果:
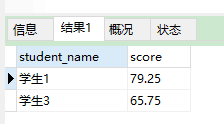
这样一个看起来有点复杂的 sql,采用从里到外逐步分析的方式,也就可以轻松写出来了。
日常写代码经常会遇到数据统计的业务场景,分组查询 group by 结合 count 和 sum 的复杂语句写起来容易令人头大,在这里分享几种常用的统计场景,做个记录的同时也希望能帮到大家。场景1:统计每个学生的加分次数/总加分 and 减分次数/总减分库表结构如下所示:学生分数表:student_score字段名含义字段类型备注id自增编号bigintstudent_name学生姓名varcharscore分数doublesort分数类
在介绍
GROUP BY 和 HAVING 子句前,我们必需先讲讲
sql语言中一种特殊的函数:聚合函数,
例如
SUM,
COUNT, MAX, AVG等。这些函数和其它函数的根本区别就是它们一般作用在多条记录上。
SELECT
SUM(population) FROM bbc
这里的
SUM作用在所有返回记录的population字段上,结果就是该
查询只返回一个结果,即所有
国家的总人口数。
having是分组(
group by)后的筛选条件,分组后的数据组内再筛选
where则是在分组前筛选
通过使用
GROUP BY 子句,可以让
SUM 和
COUNT 这些函数对属于一组的数据起作用。
sql统计类代码
select type,count(*) as 总数量,
sum(case when level='一级' then 1 else 0 end) as 一级,
sum(case when level='二级' then 1 else 0 end) as 二级,
sum(case when level='三级' then 1 else 0 end) as 三级
from table group by type
SQL中Group By的使用1. 概述2. 原始表3. 简单分组4. Group by 和 Order by5. Group By中Select指定的字段限制6. 多列分组7. Group By与聚合函数8. Having与Where的区别9. Compute 和 Compute By
1. 概述
Group By从字面意义上理解就是根据By指定的规则对数据进行分组,所谓的分组就是将一个数据集划分成若干个小区域,然后针对若干个小区域进行数据处理。
2. 原始表
3. 简单分组
select
开始写的
语句大体是:
select
count(m.fbrandid) from table as m
group by m.fbrandid, month(fdate);
数据库中的数据为:
+----------+------
一、汇总分析常用的汇总分析函数有下面几种。例如从成绩表中查询成绩求和(所用数据表在第一课已共享)select sum(成绩)
from score;从成绩表中查询成绩平均值select avg(成绩)
from score;从成绩表查询成绩最大值和最小值select max(成绩),min(成绩)
from score;二、分组SQL分组:group byselect 性别,count(*)
org.apache.ibatis.exceptions.TooManyResultsException: Expected one result (or null) to be returned by selectOne(), but found: 5
报错的意思是:期望的是一条数据,但是返回的是五条数据
在看一下报错的SQL语句
SELECT
count( ma.goods_id ) AS num
machin
原文:https://www.cnblogs.com/jimleestone/p/
sql_001.html
当表数据量很庞大, 需要使用
sql的limit功能来分页时, 需要发送两条
sql才能
实现分页
SELECT * FROM tablename WHERE conditions LIMIT pagestart, pagesize
SELECT
COUNT(*) FROM tablename WHERE conditions
其中第二条是在UI上显示总结果数量以及进行分页的操作;
SELECT count(*) FROM 表名 WHERE 条件 // 这样查出来的是总记录条
SELECT count(*) FROM 表名 WHERE 条件 GROUP BY id //这样统计的会是每组的记录条数.
如何获得 第二个sql语句的总记录条数?
则是,如下:
select count(*) from(SELECT count(*) FR...
进行数据分析时,
GroupBy分组
统计是非常常用的操作,也是十分重要的操作之一。基本上大部分的数据分析都会用到该操作,本文将对Python的
GroupBy分组
统计操作进行讲解。
1.
GroupBy过程
首先看看分组聚合的过程,主要包括拆分(split)、应用(Apply)和合并(Combine)
2.创建DataFrame
import pandas as pd
ipl_data = {...

