|
|
|
相关文章推荐

|
儒雅的皮带 · 猜数游戏,随机生成一个1~100的数进行猜测 ...· 2 年前 · |
|
|
宽容的凉茶 · excel怎么统计符合多条件时出现次数-掘金· 2 年前 · |
|
|
打酱油的野马 · C#之winform捕获Console.Wr ...· 2 年前 · |
|
|
面冷心慈的花卷 · Verilog HDL - 知乎· 3 年前 · |

作者:Vladimir Iglovikov
机器之心编译
机器之心编辑部
那些被遗忘的竞赛项目代码、权重可能也是一笔宝藏。
很多人可能参加过许多比赛,做过许多项目,但比赛或项目结束之后,曾经写过的代码、用过的模型就被丢到了一边,甚至不久就被删掉。
这种情况并不只存在于比赛中,在学术领域同样存在。当学生训练完模型、写完论文并被学术会议接收后,该模型的 pipeline 就会被抛弃,训练数据也随之被删除。这是不是有点太可惜了?
长期参加 Kaggle 比赛的 Vladimir Iglovikov 在自己的博客中指出了这个问题,并提出了一些重新利用这些资源的建议。
Vladimir Iglovikov 是一位 Kaggle Grandmaster,曾在 Kaggle 全球榜单中排名第 19,拿到过 Carvana 图像遮蔽挑战的冠军。

在他看来,竞赛中曾经用到的代码、权重等资源是一笔宝贵的财富,可以帮助你 巩固技术知识、树立个人品牌、提高就业机会 。
为了解释这些资源资源的价值,他还专门创建了一个 GitHub 项目(retinaface)来讲述文本的建议。
项目链接:https://github.com/ternaus/retinaface
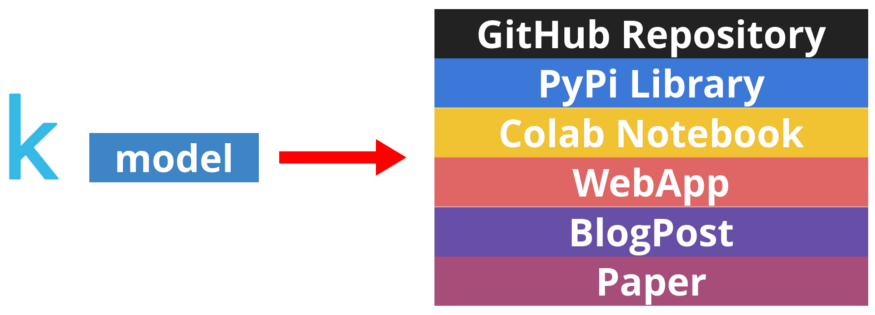
以下是博客的具体内容。
花 5 分钟将代码发布到公开的 GitHub 存储库
很多时候,你的代码可能已经存到 GitHub 上了,但是是存在私人库里。那公开又有什么损失呢?
某些情况下,有些代码确实不宜公开,但你在 Kaggle 里做的那些练手项目、解决方案和论文或许没这个必要。
为什么有些人不愿公开呢?因为很多人认为,「所有公开发布的代码都应该是完美的,否则就会遭到批判。」
但实际情况是,其他人根本不 care,你只管发布就行。
公开代码是心理防线的一次重大突破,公开不完美的代码更是一个自信、大胆的举动。所有后续步骤也都在这一步的基础上展开。
花 20 分钟提升代码可读性
你可以通过添加语法格式化工具和检查工具来提升 python 代码的可读性。
这并不困难,也并不费时。检查工具和格式化程序不会将烂代码变成好代码,但其可读性会有所提升。以下是具体步骤:
步骤 1:文件配置
将这些文件添加到存储库的根目录。
setup.cfg — flake8 和 mypy 的配置。
pyproject.toml — black 的配置。
步骤 2:requirements
用以下命令安装所需的库:
pip install black flake8 mypy
步骤 3:black
格式化代码的方法有 100500 多种。诸如 black 或 yapf 之类的格式化工具会按照一组预定义的规则来修改代码。
阅读具有一定标准的代码库会更加容易。当你花费几个小时编写代码并需要在不同的编码风格之间切换语境时,你的意志力会被消耗殆尽。因此,没有充分的理由就不要这么做。
运行以下命令将重新格式化所有的 python 文件以遵循 black 的规则。
black .
步骤 4:flake8
运行以下命令不会修改代码,但会检查代码中的语法问题并将其输出到屏幕上。然后修改这些问题。
flake8
步骤 5:mypy
Python 没有强制性的静态类型化,但还是建议将类型添加至函数参数并返回类型。例如:
class MyModel (nn.Module) :
....
def forward (x: torch.Tensor) -> torch.Tensor:
....
return self.final(x)
你应该在代码中添加键入内容。这会让代码读起来更容易。你可以使用 mypy 包检查参数和函数类型的一致性。更新代码后,在整个存储库上运行 mypy:
mypy .
如果 mypy 出现问题,修复它们。
步骤 6:预提交钩子(hook)
一直手动运行 flake8、black 和 mypy 会觉得厌倦。一个名为 pre-commit 的钩子能够解决这个问题。要启用它,可以将以下文件复制到你的存储库中:https://github.com/ternaus/retinaface/blob/master/.pre-commit-config.yaml
你需要使用以下命令安装 pre-commit 包。
pip install pre-commit
使用以下命令进行初始化:
pre-commit install
安装完成后,每次提交都会经历一组检查。当提交中有错误时,检查不会允许提交通过。这和手动运行 black、flake8 以及 mypy 的不同之处在于,它不会乞求你修复问题,而是强制要求你做这件事。因此,这种方法不会浪费你的意志力、
步骤 7:Github 操作
你已经向 pre-commit 钩子中添加了检查步骤,并在本地运行了这些步骤。但是你还需要第二道防线——让 GitHub 在每个拉取请求上运行这些检查步骤。
你要做的就是将以下文件添加到存储库中:https://github.com/ternaus/retinaface/blob/master/.github/workflows/ci.yml
执行以下代码来告诉 GitHub 要检查什么:
- name: Install dependencies
run: |
python -m pip install --upgrade pip
pip install -r requirements.txt
pip install black flake8 mypy
- name: Run black
run:
black --check .
- name: Run flake8
run: flake8
- name: Run Mypy
run: mypy retinaface
我还建议放弃将代码直接推送到 master 分支的做法。你可以创建一个新的分支、修改代码、提交、放到 Github 上、创建 PR 请求,然后合并到 master。这是一项行业标准,但是在学术研究和 Kaggle 参赛者中却不常见。如果你对这些工具不熟悉,可能需要花 20 分钟添加它们并修复错误和警告。
记住这次的操作。在下个项目中,你可以在没写代码之前就在第一次提交中添加这些检查。从这个时候开始,每次小的提交都会被检查,你每次最多只需要修复几行代码。这么做开销很小,也是一个良好的习惯。
花 20 分钟写一个优秀的 readme
好的 readme 有两个作用:
对你自己而言:可能你认为你永远都不会再用到这些代码了,但实际上并不一定。下次用的时候你可能也记不得它的具体内容了,但 readme 可以帮到你。
对其他人而言:readme 是一个卖点。如果人们看不出该存储库的用途以及它所解决的问题,大家就不会使用它,你所做的所有工作都不会对他人产生积极影响。
一个机器学习库的最低要求是说明以下问题:
用一张图来说明任务是什么以及如何解决,而不需要任何文字。在花了几周解决问题之后,你可能有 100500 张图,但你不能把他们放在 readme 里;
数据放在哪里;
怎样开始训练;
如何进行推理。
如果你需要写 100500 个词来描述怎样运行训练或者推理,那就说明你的项目存在问题了。 你需要重构代码,使它对用户更加友好。
人们经常会问:如何提高写代码的能力?这便是一个锻炼你的机会。你可能需要重写代码,尝试站在别人的角度看待你的 Readme。
这是一个很好的锻炼机会,它能够让你学会从用户的角度看待问题。
花 20 分钟提高模型易用性
我猜你会编写如下代码来加载预训练模型权重。
model = MyFancyModel()
state_dict = torch.load()
model.load_state_dict(state_dict)
这样的方法虽然有用且步骤清晰,但是它需要磁盘上的权重,并且要知道它们的位置。一个更好的解决方案是在 TensorFlow 或 Keras 上使用 torchvision 中的 torch.utils.model_zoo.load_url 函数:
from retinaface.pre_trained_models import get_model
model = get_model( "resnet50_2020-07-20" , max_size= 2048 )
用上面的代码从 retinaface.pre_trained_models 中引入 get_modelmodel = get_model("resnet50_2020-07-20", max_size=2048)。
如果权重不在磁盘上,那就会从网络上先下载下来再缓存到磁盘上。初始化模型,并加载权重,这对用户来说是很友好的,也是你在 torchvision 和 timm 库中所看到的。
步骤 1:托管预训练模型的权重
这对我来说是最大的障碍。如果不想使用 AWS、GCP,我要把模型的权重放在哪里?GitHub 上的 releases 是一个不错的选择。
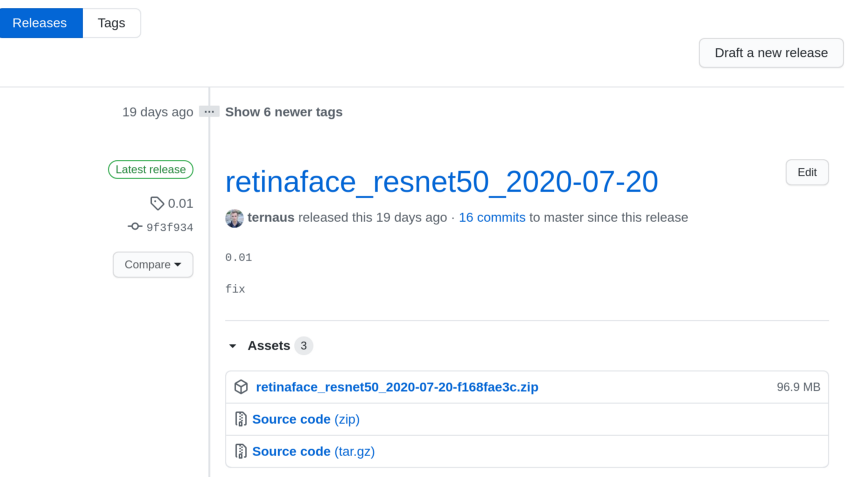
每个文件的大小限制是2Gb,对大多数深度学习模型来说够用了。
步骤 2:编写一个初始化模型和加载权重的函数。
我给出的示例代码如下:
# https://github.com/ternaus/retinaface/blob/master/retinaface/pre_trained_models.py
from collections import namedtuple
from torch.utils import model_zoo
from retinaface.predict_single import Model
model = namedtuple( "model" , [ "url" , "model" ])
models = {
"resnet50_2020-07-20" : model(
url= "https://github.com/ternaus/retinaface/releases/download/0.01/retinaface_resnet50_2020-07-20-f168fae3c.zip" , # noqa: E501
model=Model,
)
}
def get_model (model_name: str, max_size: int, device: str = "cpu" ) -> Model:
model = models[model_name].model(max_size=max_size, device=device)
state_dict = model_zoo.load_url(models[model_name].url, progress= True , map_location= "cpu" )
model.load_state_dict(state_dict)
return model
在构建 Colab Notebook 和 WebApp 时会用到这个函数。
花 20 分钟创建一个库
这一步是为了降低你模型的入口点。
步骤 1: 向 requirements.txt 中添加必要的依赖,你可以手动更新或使用如下代码:
pip freeze > requiements.txt
步骤 2:改变存储库的文件结构
创建一个「主文件夹」,在我给出的示例中,这个文件夹叫「retinaface」。
将所有重要代码都放进这个文件夹,但不要把 helper 图像、Readme、notebook 或 test 放进去。手动操作这一步骤并更新所有的 import 会很累。PyCharm 或者类似的 IDE 会为你执行这一步骤。
这是存储库中构建代码结构的常用方法。如果你想让其更加结构化,请查看 Cookie Cutter 包。
步骤 3:添加配置文件
向根目录中添加 setup.py,内容类似于示例文件「setup.py」中的内容。添加包的版本,在我的示例中,我将它添加到了主文件夹的 init 文件中。
步骤 4:在 PyPI 上创建一个账户。
步骤 5:搭建一个库并上传到 PyPI 上。
python setup.py sdist
python setup.py sdist upload
你的存储库是一个库,每个人都可以使用如下命令安装它:
pip install
如果你在 PyPI 上查看包的页面,你就会看到它使用你存储库中的 Readme 文件来陈述项目。我们将会在 Google Colab 和 Web App 上使用这一步的功能。
花 20 分钟创建 Google Colab notebook
将 Jupiter notebook 添加到存储库是一个好习惯,以展示如何初始化模型和执行推理功能。
在前两个步骤中,我们使用了模型初始化和 pip install。接下来创建 Google Golab notebook。
现在,只需要一个浏览器,就会有更多的人尝试你的模型了。别忘了在 readme 中添加 notebook 的链接,并在 PyPi 上更新版本。
花 20 分钟创建 WebApp
许多数据科学家认为构建 web 应用程序是一个复杂的过程,需要专业知识。这种想法是正确的。一个复杂项目的 web 应用程序确实需要很多数据科学家并不具备的专业知识,但构建一个简单的 web 应用程序来展示模型还是很容易的。
我为一个 web 应用程序创建了一个单独的 GitHub 存储库。不过,你仍然可以在你的存储库中用你的模型来操作。这里有一篇描述具体细节的技术博客:https://towardsdatascience.com/deploy-streamlit-on-heroku-9c87798d2088。
步骤 1:为应用程序添加代码:
"""Streamlit web app"""
import numpy as np
import streamlit as st
from PIL import Image
from retinaface.pre_trained_models import get_model
from retinaface.utils import vis_annotations
import torch
st.set_option( "deprecation.showfileUploaderEncoding" , False )
@st.cache
def cached_model () :
m = get_model( "resnet50_2020-07-20" , max_size= 1048 , device= "cpu" )
m.eval()
return m
model = cached_model()
st.title( "Detect faces and key points" )
uploaded_file = st.file_uploader( "Choose an image..." , type= "jpg" )
if uploaded_file is not None :
image = np.array(Image.open(uploaded_file))
st.image(image, caption= "Before" , use_column_width= True )
st.write( "" )
st.write( "Detecting faces..." )
with torch.no_grad():
annotations = model.predict_jsons(image)
if not annotations[ 0 ][ "bbox" ]:
st.write( "No faces detected" )
else :
visualized_image = vis_annotations(image, annotations)
st.image(visualized_image, caption= "After" , use_column_width= True )
步骤 2:添加配置文件
你需要添加以下文件:
setup.sh — 该文件可以直接使用,不需要更改。
Procfile — 你需要使用应用程序修改文件的路径。
步骤 3:添加 requirements.txt 文件
步骤 4:在 herokuapp 上注册
步骤 5:执行以下代码:
heroku login
heroku create
git push heroku master
花 4 小时写一篇技术博客
很多人低估了他们研究的价值。实际上你的文章很可能能够帮助别人,并且能够为自己的职业生涯提供更多的机会。
如果要写机器学习方面的文章,我建议你包含以下内容:
研究问题是什么?
你是如何解决这个问题的?
示例如下:
项目:https://www.kaggle.com/c/sp-society-camera-model-identification
博客:http://ternaus.blog/machine_learning/2018/12/05/Forensic-Deep-Learning-Kaggle-Camera-Model-Identification-Challenge.html
花时间写篇论文,描述你在这场机器学习竞赛中的解决方案
即使你的论文中没有重大突破,它也会被发表并帮到别人。撰写学术论文也是一项技能。你现在可能还不具备这种技能,但你可以与擅长学术写作的人合作。
下面是我的 Google Scholar 引用情况,这几年引用量的猛增都得益于我写的那些总结机器学习竞赛的论文。
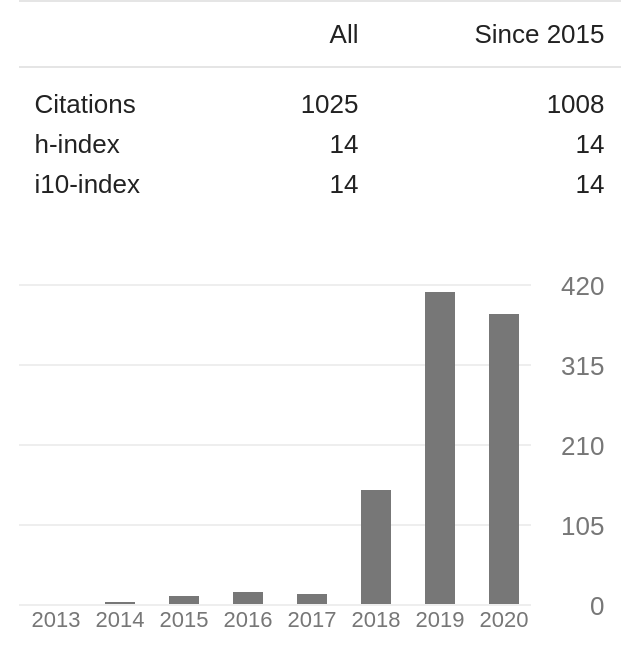
当然,你的论文也包含在一个大包里,这个包里还有:
GitHub 存储库,里面有整洁的代码和良好的 readme 文件。
非机器学习人员能够使用的库。
允许在浏览器中用你的模型进行快速实验的 Colab notebook。
吸引非技术受众的 WebApp。
用人类语言讲故事的博客文章。
有了这些之后,它就不再只是一篇论文,而是一种综合性的策略,可以显示你对该项目的所有权,还能帮助你与他人进行沟通。这两者对于你的职业生涯都是至关重要的。