|
|
|


如何绕过豆瓣对爬虫的限制,来爬取豆瓣上每个电影的标签?
我现在已经爬取豆瓣上的绝大部分电影的url,然后直接用python去爬去每个电影的标签。但是通常爬几十个网页,就会出现HTTP403Forbidden…
关注者
41
被浏览
15,981
登录后你可以
不限量看优质回答
私信答主深度交流
精彩内容一键收藏

相信有很多朋友喜欢看电影。但是电影这玩意儿,看着看着就很容易不知道看什么了。这几年电影行业不景气,一方面跟疫情有关,另一方面也的确是因为没什么好作品。那么历史的作品有没有什么好看的呢?
那就得想办法翻一下历史的电影库了,这方面国内的首选自然就是豆瓣了。今天我就教大家学会怎么快速的搞到豆瓣的电影列表,从而用电脑帮我们快速筛选我们喜欢的电影。
一、找到我们的目标网页
首先我们打开豆瓣电影的首页,
https://movie.douban.com
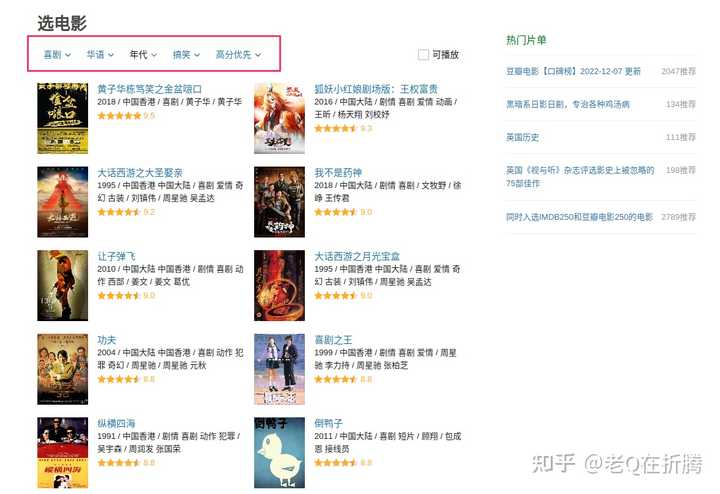
。因为我们这次的目标并不是看什么热门电影,而是想从历史的电影库中找到符合我们品味的电影。所以我们忽略首页推荐的这些榜单,直接在红框那里点击更多,看看是不是有更多的选择。
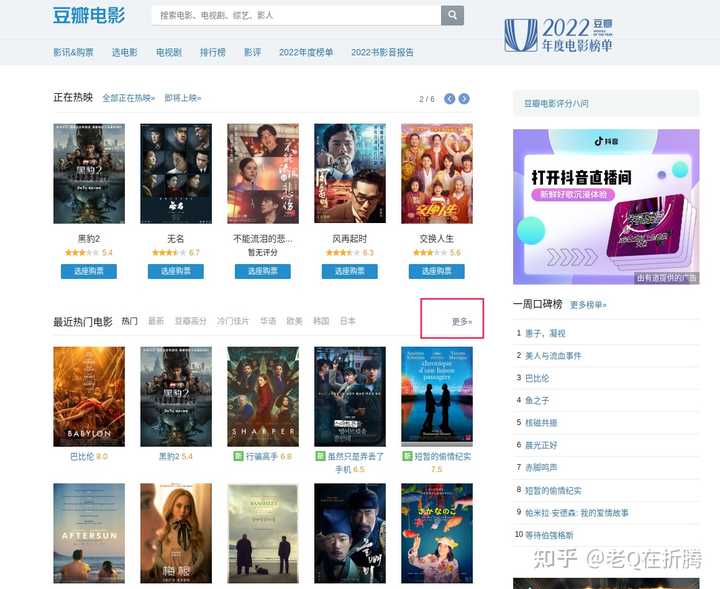
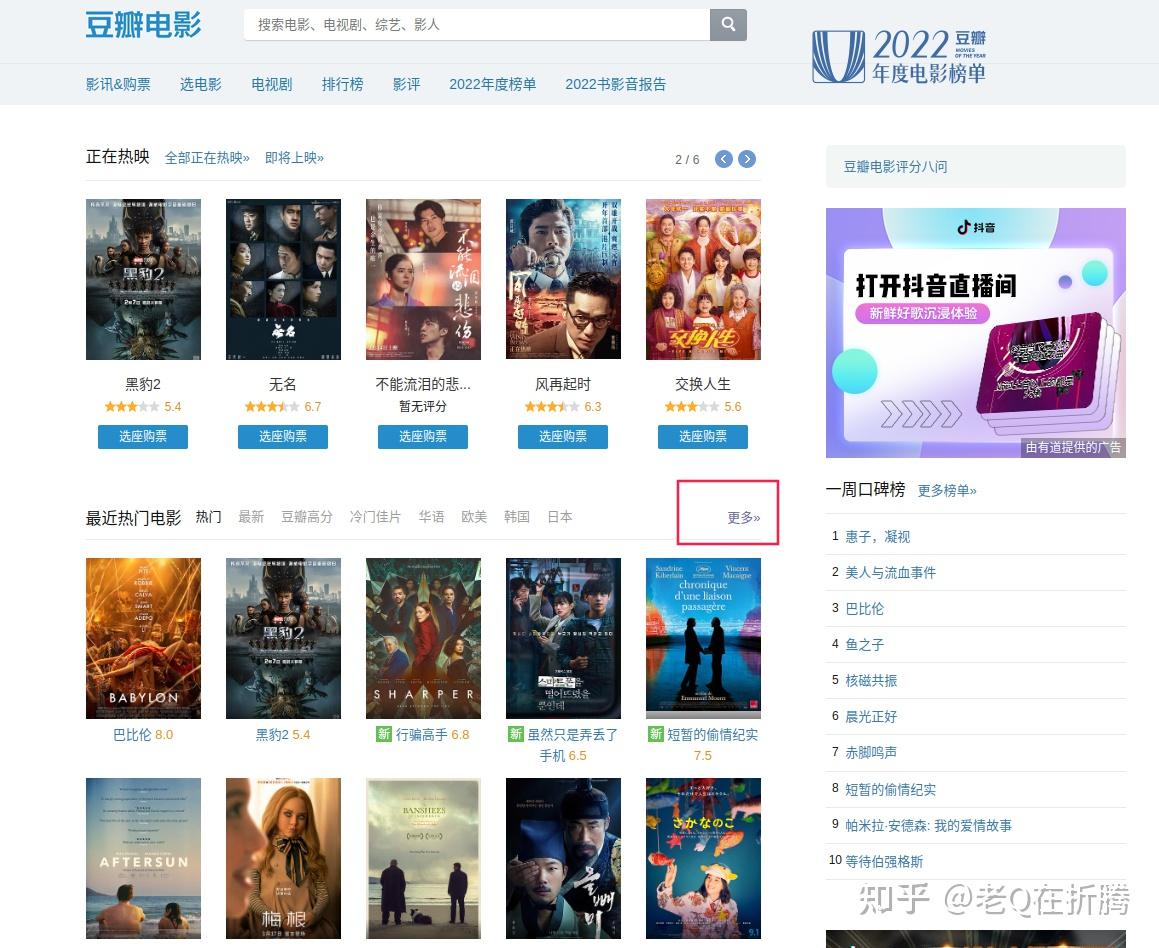
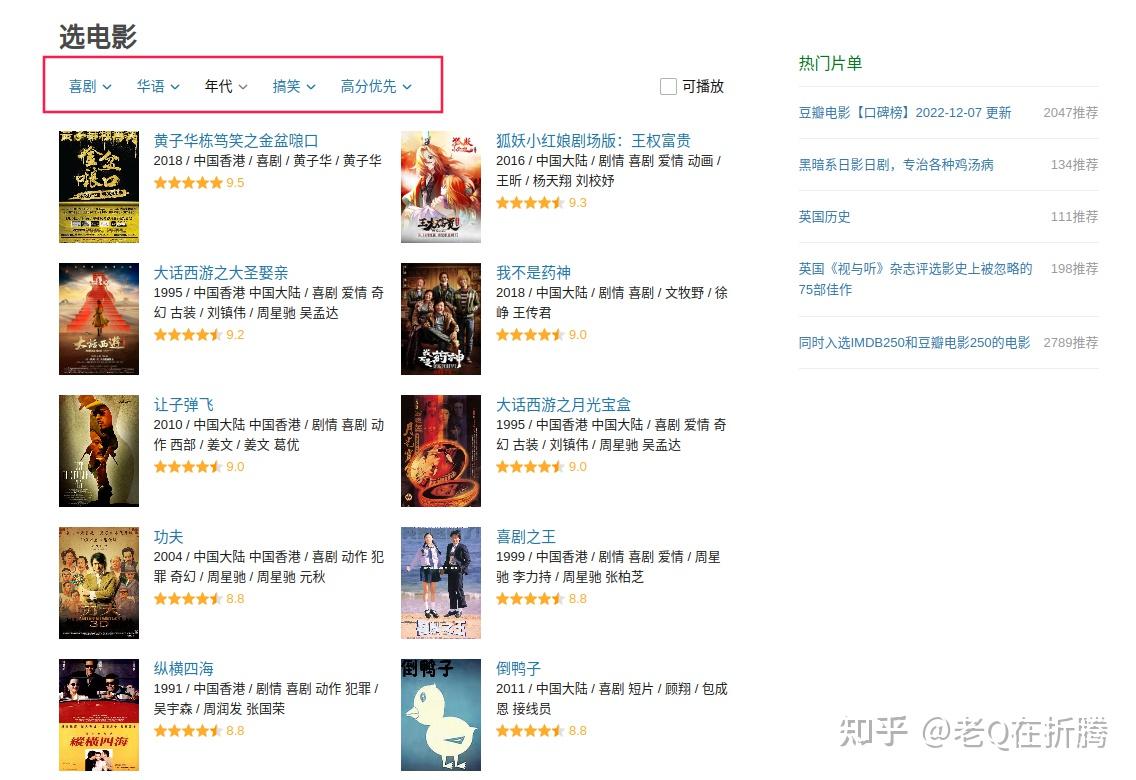
进来以后,我们发现这里的模块叫“选电影”。这里支持我们通过类型、地区、年代、标签等进行筛选,还支持我们按照一定的规则进行排序。
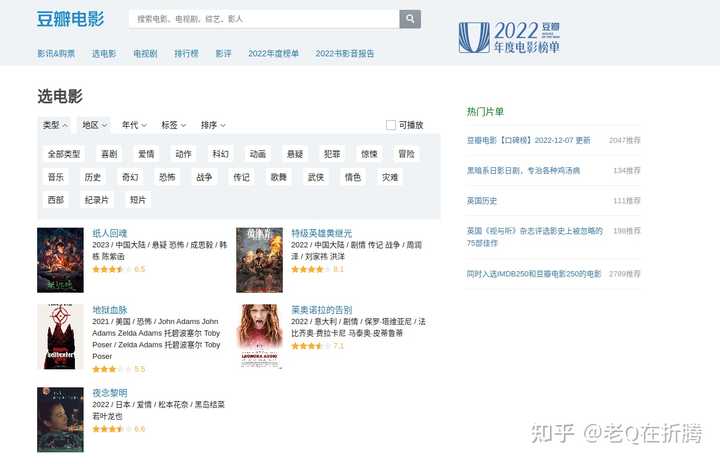
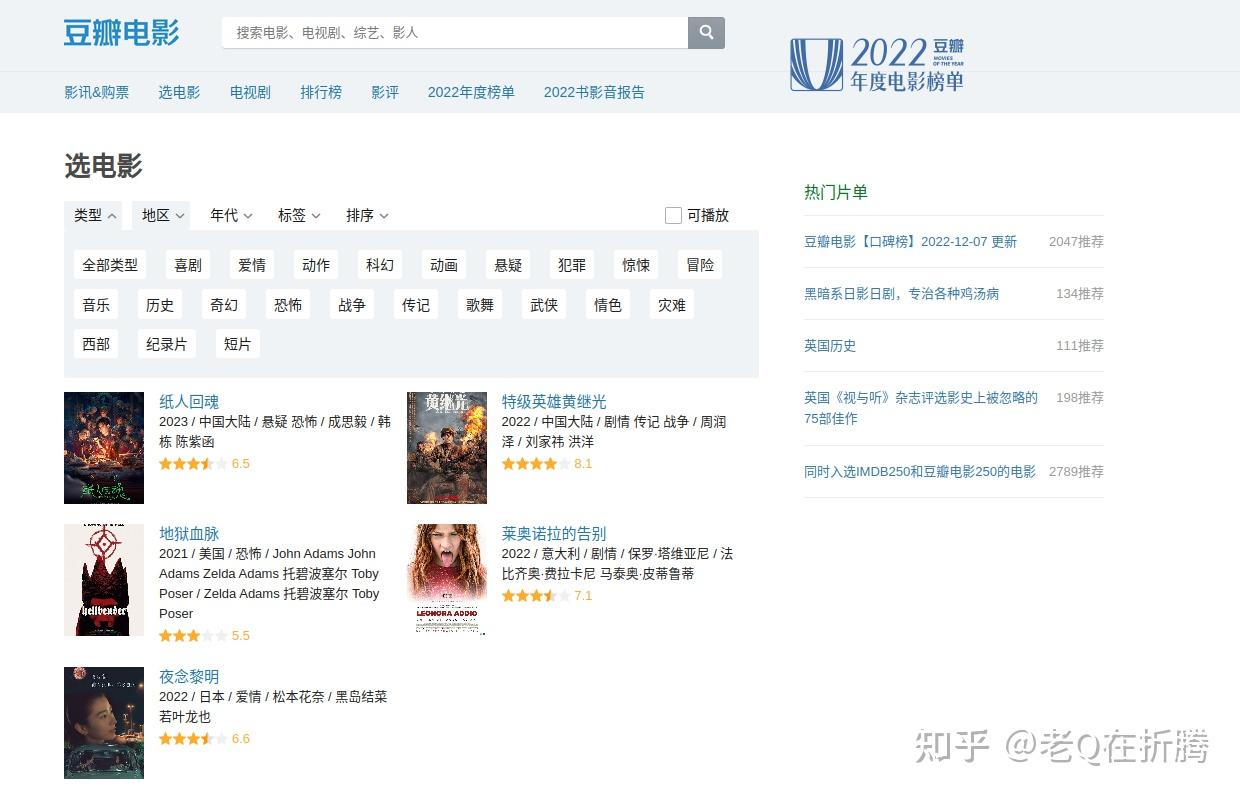
我们稍微做下选择试试看。老Q喜欢看喜剧,那就先这么试着筛选一下看看。出来了很多作品,但是肉眼翻看也太多了,那我们就试着用爬虫来抓一下吧。
二、分析网络请求
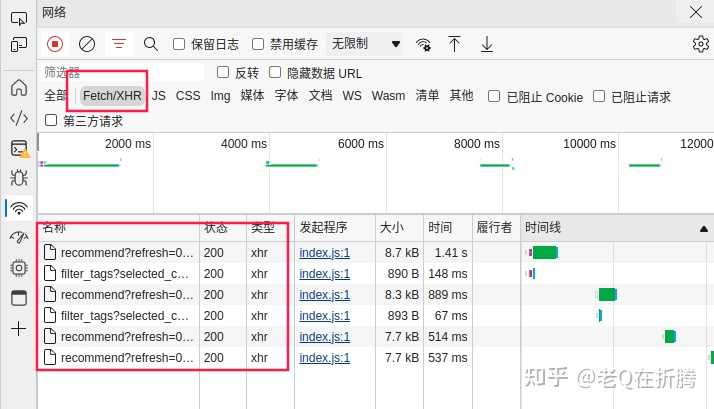
我们右键点击检查,或按F12进入开发者模式,然后点击进入网络选项卡,刷新一下页面,然后清除所有的历史请求。
然后我们重新进行我们刚才的选择,看下浏览器发起的网络请求是怎么样的。我们注意到,我们每做一次筛选,右侧的网络请求就会多出一大堆。因为我们最后的那一次选择才是输出我们希望结果的选择,所以我们重点关注最后发出的那些请求。
前面我们讲过,现在很多网站会通过异步的方式来加载网页内容,尤其是这种我们点击了筛选之后只有局部更新的页面,更是如此。
所以我们先重点关注下
XHR
类型。可以看到,筛选之后,只剩下没几条记录了。
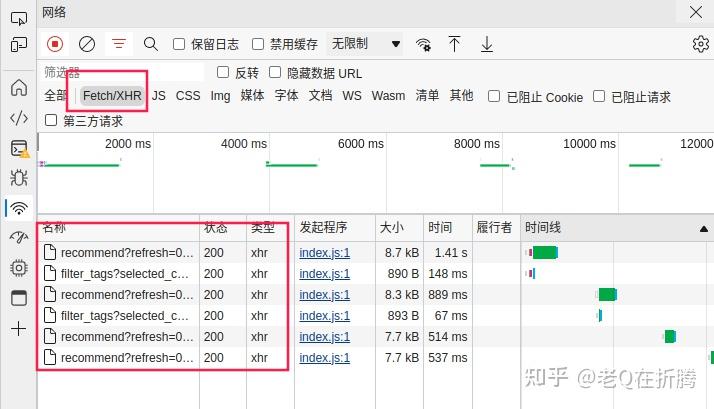
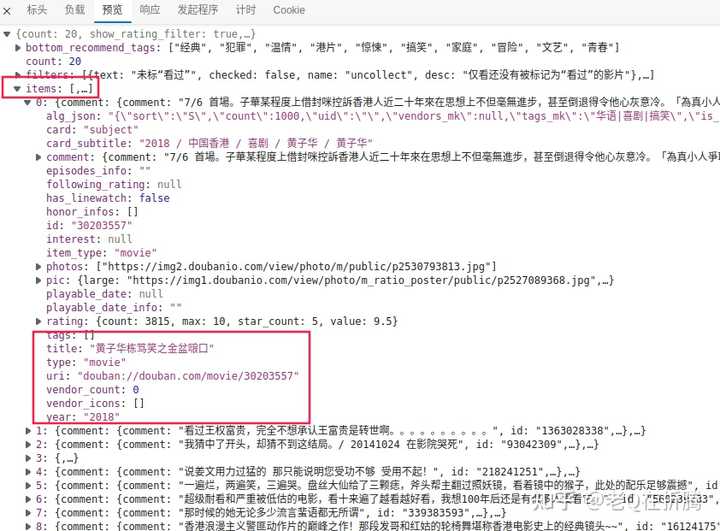
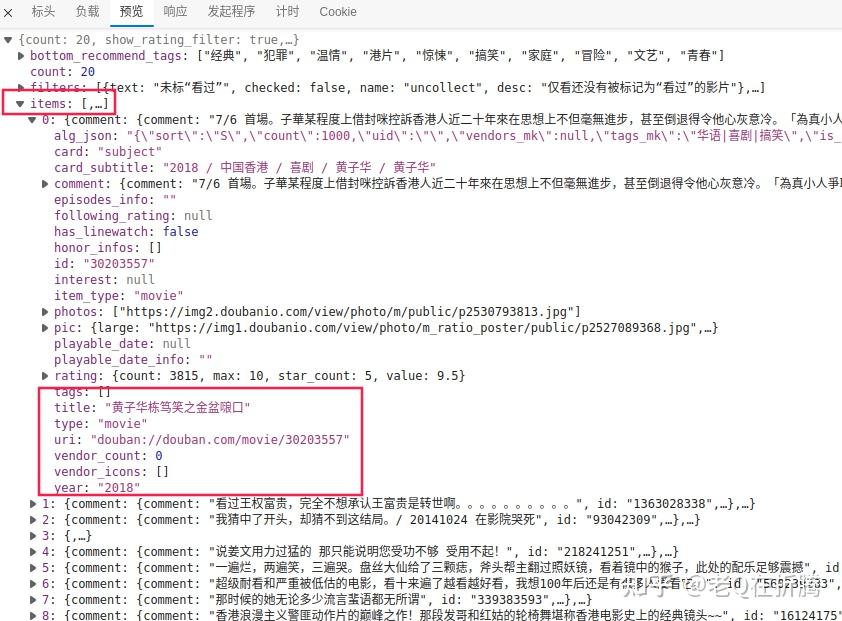
我们点开最后一条看一下。在预览里我们看到,服务器返回的结果是
JSON
格式的数据,其中有一个
items
的关键字,对应了一个列表,其中每条记录就对应了网页上的一部电影。很好,很轻松就找到了。
那我们再来分析一下请求的URL。看起来这个URL里包含中文,被转化为了URL编码的内容。我们可以尝试着解析一下,看看这里的参数都是什么。代码里内容忘记了的同学,记得去历史文章里复习、补课哦。
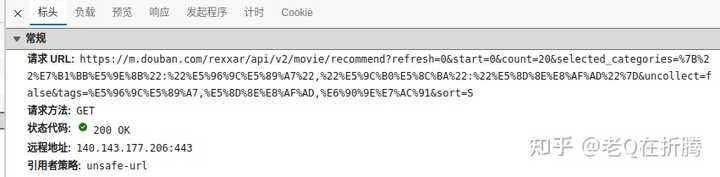
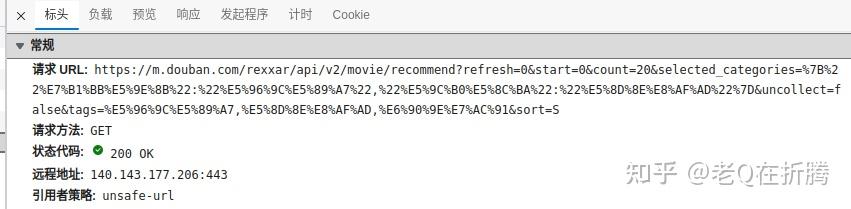
import urllib
url_init = ('https://m.douban.com/rexxar/api/v2/movie/recommend?refresh=0&start=0'
'&count=20&selected_categories=%7B%22%E7%B1%BB%E5%9E%8B%22:%22%E5%96%9C%E5%89%A7%22,'
'%22%E5%9C%B0%E5%8C%BA%22:%22%E5%8D%8E%E8%AF%AD%22%7D&uncollect=false&'
'tags=%E5%96%9C%E5%89%A7,%E5%8D%8E%E8%AF%AD,%E6%90%9E%E7%AC%91&sort=S')
url = urllib.parse.unquote(url_init)
print(url)输出结果为:
https://m.douban.com/rexxar/api/v2/movie/recommend?refresh=0&start=0&count=20&selected_categories={"类型":"喜剧","地区":"华语"}&uncollect=false&tags=喜剧,华语,搞笑&sort=S我们知道,在问号后边的部分是查询的参数,以key=value的形式呈现,多个参数间以&符号拼接。那么我们可以试着将这些参数解析为字典格式,这样看着会更舒服。
query = urllib.parse.urlparse(url).query
params = urllib.parse.parse_qs(query)
params输出为:
{'refresh': ['0'],
'start': ['0'],
'count': ['20'],
'selected_categories': ['{"类型":"喜剧","地区":"华语"}'],
'uncollect': ['false'],
'tags': ['喜剧,华语,搞笑'],
'sort': ['S']}
嗯,看起来这里是通过
start
配合
count
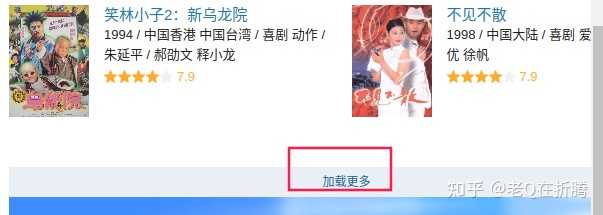
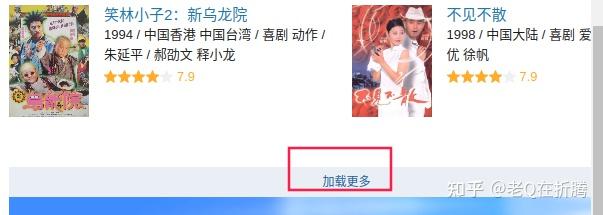
来翻页,其他的几个参数包含了分类、标签、排序等。我们点击页面下方的加载更多按钮,观察一下新出现的网络请求。
可以看到,每次新出现的请求中,
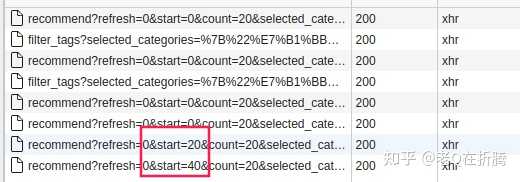
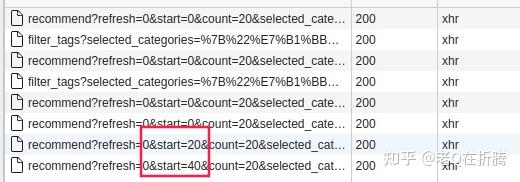
start
参数的值会增加20。也就是说,我们每点一次加载更多,相当于再跟服务器请求20条记录。
好了,到了这一步,其实抓取的代码就很明朗了。
三、开始抓取
我们看下接口地址对应的爬虫协议。
https://m.douban.com/robots.txt
。
User-agent: *
Disallow: /book_search
Disallow: /group/topic_search
Disallow: /group/search
Disallow: /j/wechat/signature
Disallow: /rexxar/api/v2/notification_chart
Disallow: /rexxar/api/v2/market
Sitemap: https://m.douban.com/sitemap_index.xml
Sitemap: https://m.douban.com/sitemap_updated_index.xml
User-agent: Wandoujia Spider
Disallow: /可以看到,这里没有对抓取频率做限制,我们保险起见可以每次抓取休息一秒,避免被封IP,毕竟我们也不是很赶时间。
我们要用的接口
https://m.douban.com/rexxar/api/v2/movie/
很明显并不在禁止列表里,那我们就可以放心抓取了。
抓取原始数据的代码如下:
import requests
import json
import time
import pandas as pd
def get_one_request(url, headers, params):
res = None
cnt = 0
while cnt <= 3:
req = requests.get(url, headers=headers, params=params)
if req.status_code == 200:
res = json.loads(req.text)
break
else:
cnt += 1
continue
return res
def get_origin_data(page_cnt=50):
res_list = []
headers = {
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/110.0.0.0 Safari/537.36 Edg/110.0.1587.41',
'Referer': 'https://movie.douban.com/explore'
url_base = 'https://m.douban.com/rexxar/api/v2/movie/recommend?'
params = {
'refresh': ['0'],
'start': ['0'],
'count': ['20'],
'selected_categories': ['{"类型":"喜剧","地区":"华语"}'],
'uncollect': ['false'],
'tags': ['喜剧,华语,搞笑'],
'sort': ['S']
for i in range(page_cnt):
start = str(i * 20)
params['start'] = [start]
res = get_one_request(url_base, headers, params)
res_list.append(res)
time.sleep(1)
return res_list
if __name__ == '__main__':