均值方差归一化,也称为标准化。英文也叫作Z-score Normalization,它是把所有数据归到均值为0,方差为1的分布中。即确保最终得到的数据均值为0,方差为1。
均值方差归一化的公式为如下:
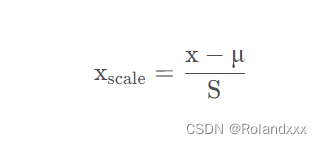
其中x为要归一化的值,μ为样本均值,S为样本的标准差:
首先减去均值就相当于把数据分布进行平移,即改变平均值。使数据的平均值都为0。这样并不会改变数据分布中各个点之间的距离。然后因为标准差可以理解为平均每个点距离平均值的距离,除以标准差就相当于以前平均每个点距离0的距离为S,现在变成了1。这样的话,对于数据中每个点的所有特征维度距离0的量纲就保持一致了。最后数据就都为均值为0,方差为1的正态分布了。
文章目录为什么要进行数据
归一化
什么是数据
归一化
最值
归一化
(Normalizat
ion
)最值
归一化
的适用性
均值
方差
归一化
(
Standardizat
ion
)为什么要这么
归一化
呢?参考文献
为什么要进行数据
归一化
我们来考虑这样一个场景,我要使用KNN
算法
来预测一个人的职业。目前我们提取到了一批数据,如下:
该技术通过将数据的
均值
转换为0,同时缩放数据的范围,使得数据的标准差为1。这样做的目的是将数据集中在0附近,同时缩小不同特征之间的尺度差异,有助于提高学习
算法
的性能和收敛速度。,否则可能会导致出现负数等异常情况,因此在使用该方法时需要先检查数据分布是否满足要求。
均值
和
方差
归一化
是一种数据预处理技术,也称为。需要注意,
均值
和
方差
归一化
要求。
由google2015年提出,深度神经网络训练的技巧,主要是让数据的分布变得一致,从而使得训练深层神经网络更加容易和稳定。
BN的作用就是将这些输入值或卷积网络的张量进行类似标准化的操作,将其放缩到合适的范围,从而加快训练速度;另一方面使得每一层可以尽量面对同一特征分布的输入值,减少了变化带来的不确定性
3.操作阶段
4.操作流程
计算每一层深度的
均值
和
方差
对每一层设置2个参数,γ和β。假设第1深度γ=2、β=3;第2深度γ=5、β=8。
使用缩放因子γ和移位因子β来执行此操作。
随着训练的进行,这些γ和β也通过反向传播学习以提高准确性。这就要求为每一层学习2个
我们可发现纵坐标的数据远远大于横坐标的数据。这样在我们进行计算时,由于发现时间的影响远大于肿瘤大小的影响,所以预测相当于只采用了一个特征。:它是把所有数据归到
均值
为0,
方差
为1的分布中。即确保最终得到的数据
均值
为0,
方差
为1。举个例子,例如我们要使用KNN
算法
来预测肿瘤为良性肿瘤或恶性肿瘤。观察上图,并未发现任何问题。以上述例子为例:对发现时间的特征进行
均值
方差
归一化
。以上述例子为例:对发现时间的特征进行最值
归一化
。:把所有数据映射到0-1之间。根据以上数据,画出散点图。
数据在前处理的时候,经常会涉及到数据标准化。将现有的数据通过某种关系,映射到某一空间内。常用的标准化方式是,减去平
均值
,然后通过标准差映射到均至为0的空间内。系统会记录每个输入参数的平均数和标准差,以便数据可以还原。
很多ML的
算法
要求训练的输入参数的平
均值
是0并且有相同阶数的
方差
例如:RBF核的SVM,L1和L2正则的线性回归
sklearn.preprocessing.StandardSc...
标准化 / 标准差
归一化
/ Z-Score
归一化
的
算法
是:先求出数据集(通常是一列数据)的
均值
和标准差,然后所有元素先减去
均值
,再除以标准差,结果就是
归一化
后的数据了。经标准差
归一化
后,数据集整体将会平移到以0点中心的位置上,同时会被缩放到标准差为1的区间内。要注意的是数据集的标准差变为1,并不意味着所有的数据都会被缩放到[-1,1]之间,下文有示例为证。
先行知识——量纲、
方差
、标准差、均
方差
、均方误差的概念
量纲——量纲(dimens
ion
h)是指物理量的基本属性。均方误差物理学的研究可定量地描述各种物理现象,描述中所采用的各类物理量之间有着密切的关系,即它们之间具有确定的函数关系。为了准确地描述这些关系,物理量可分为基本量和导出量。基本量是具有独立量纲的物理量,导出量是指其量纲可以表示为基本量量纲组合的物理量;一切导出量均可从基本量中导出,由...
将数组标准化为单位长度,即0..1范围。 请参阅。
const normalize = require ( 'array-normalize' )
normalize ( [ 0 , 50 , 100 ] ) // [0, .5, 1]
normalize ( [ 0 , 0 , .1 , .2 , 1 , 2 ] , 2 ) // [0, 0, .1, .1, 1, 1]
normalize ( [ 0 , .25 , 1 , .25 ] , 2 , [ 0 , .5 , 1 , .5 ] ) // [0, .5, 1, .5])
array = normalize(array,stride = 1,bounds?)
使用n维度的可选跨度对n维数组进行
归一化
。 对于2d数据布局为[x, y, x, y, ...] 。
每个维度均独立标准化,例如。 2d数组被标
本篇谈一谈数据
归一化
,谈谈什么时候要使用数据
归一化
和数据
归一化
的作用,介绍数据
归一化
的方法(最值
归一化
和
均值
方差
归一化
)
1 数据
归一化
机器学习
算法
中要求样本间的距离就要使用数据
归一化
,把数据映射到同一尺度。
数据
归一化
是为了解决量纲的问题,使数据映射到同一尺度。举2个例子:比如两个特征为月收入和和身高。月收入范围5000元-30000元,身高为1m-2.5m,在计算两个特征的欧式距离时,由于取...

