|
|
|


为什么pytorch多线程多GPU同时推理速度变慢了?
关注者
19
被浏览
40,063
8 个回答

可以用profile看一看,多卡的数据传输是怎么样的.
我在这里瞎猜一下,虽然四个GPU有自己的H-D engine,但是你CPU大概只有一个?开四个cpu线程往device送东西的过程,实际上是竞争bus的过程。
而且据我google的
“On systems with x86 CPUs (such as Intel Xeon), the connectivity to the GPU is only through PCI-Express (although the GPUs connect to each other through NVLink).”
X86 还只有PCIE可以用,消费级CPU一般就16个,PCIE通道,那么情况就变成了下图,
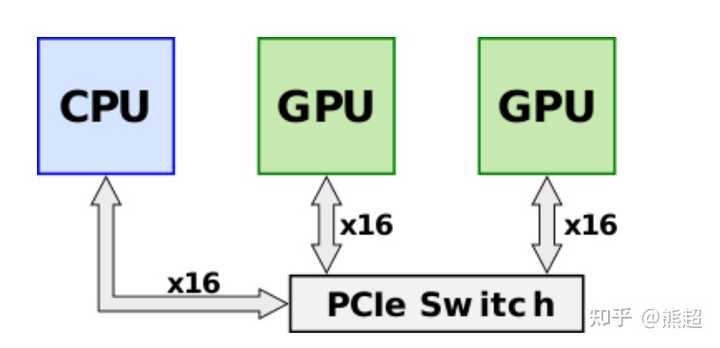

总之意思就是现在瓶颈变成了传输,你多开几个线程还增加了同步的overhead导致变慢,没看过torch内部怎么做显存管理的,可能还有额外的cost。
