

第17篇:Pandas-遍历DataFrame对象

DataFrame的遍历方式主要有三种
| DataFrame.iterrows() | 按行顺序优先,接着依次按列迭代 |
| DataFrame.iteritems() | 按列顺序优先,接着依次按行迭代 |
| DataFrame.itertuples() | 按行顺序优先,接着依次按列迭代 |
下图的DataFrame沿用上一篇的示例。
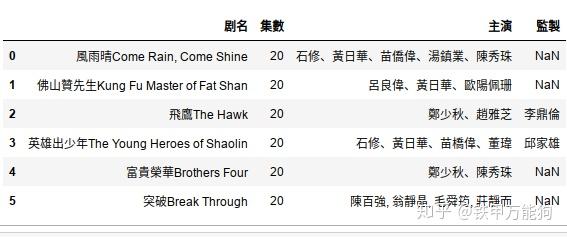
剧名,集數,主演,監製
"風雨晴Come Rain, Come Shine",20,石修、黃日華、苗僑偉、湯鎮業、陳秀珠,
佛山贊先生Kung Fu Master of Fat Shan,20,呂良偉、黃日華、歐陽佩珊,
飛鷹The Hawk,20,鄭少秋、趙雅芝,李鼎倫
英雄出少年The Young Heroes of Shaolin,20,石修、黃日華、苗橋偉、董瑋,邱家雄
富貴榮華Brothers Four,20,鄭少秋、陳秀珠,
突破Break Through,20,"陳百強, 翁靜晶, 毛舜筠, 莊靜而",读者实践本示例前,请使用Pandas.read_csv()函数加载该csv文件。
df=pd.read_csv('./result.csv')如下图所示

按行遍历
通过for迭代df.iterrows接口,idx是输出DataFrame内部的索引值,data输出每行单元格的值
for idx,data in df.iterrows():
print("[{}]: {}".format(idx,data))

输出如下


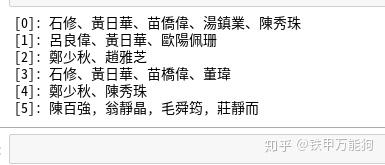
如果我们仅输出每一行特定的列,例如索引为2的列,那么我们使用如下代码
for idx,data in df.iterrows():
print("[{}]: {}".format(idx,data[2]))其工作的逻辑如下所示
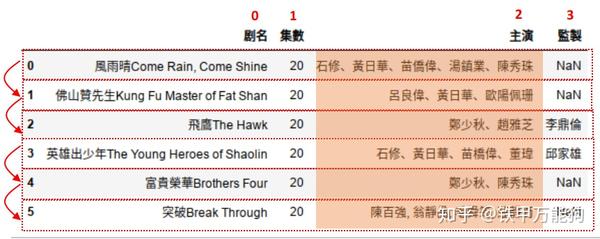

输出如下图
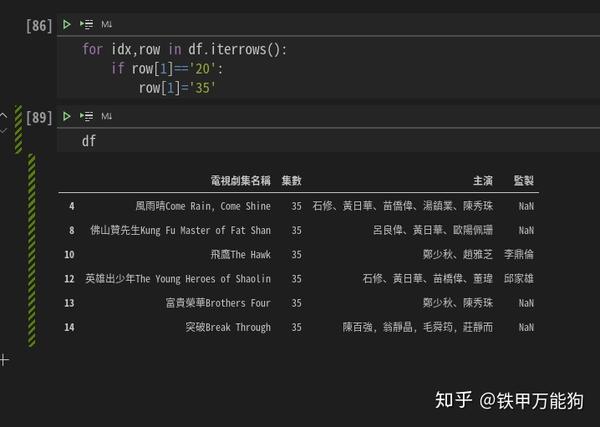
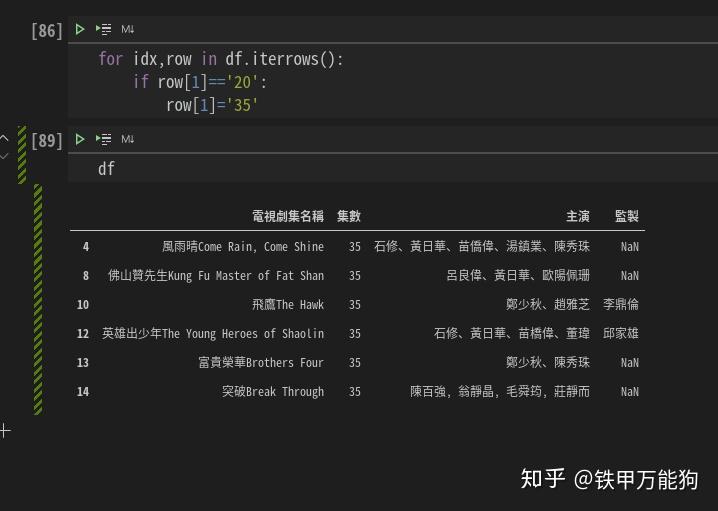
来一个有点实质意义的示例吧,例如我要将当前DataFrame中每行的第2列的所有值满足20,都改成35,但这种编程方式是不鼓励的,因为性能非常糟糕
for idx,row in df.iterrows():
if row[1]=='20':
row[1]='35'如下所示,需要注意的是,当前DataFrame除了索引列外,其他列的单元格,要么是str类型,要么是NaN类型
按行优先的遍历方式,还有itertuples( )函数,它将返回一个生成器,该生成器以元组生成行值。 让我们尝试一下:
for data in df.itertuples():