

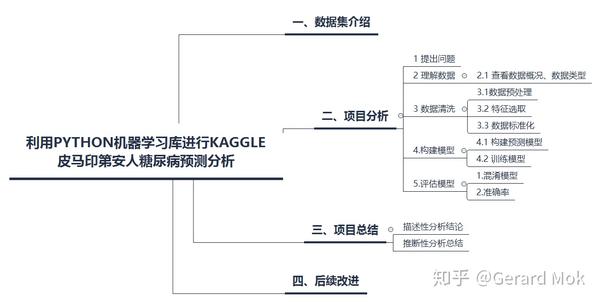
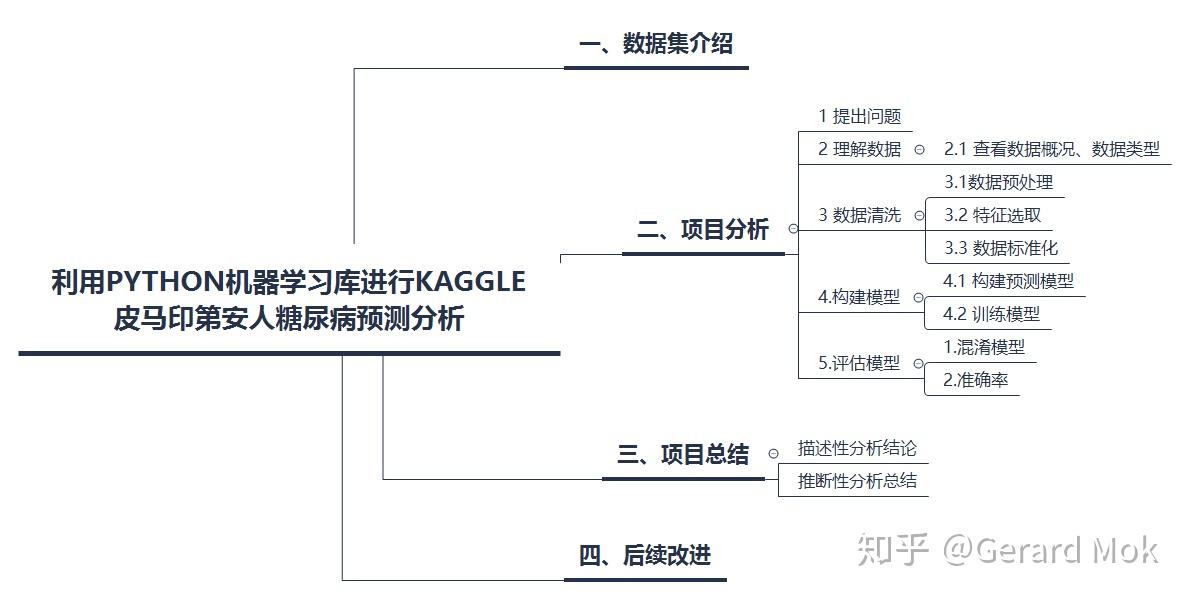
python机器学习库-Kaggle皮马印第安人糖尿病预测分析

项目摘要
本项目主要使用python对各医学参数与糖尿病之间的关系进行可视化分析、描述性分析。使用scikit-learn机器学习工具进行推断性分析,对数据标准化、使用逻辑回归算法对测试集数据进行预测,最后使用混淆模型和准确率对模型进行评估。
主要结论:
- 数据集768人中,有268人患病,500人不患病,患病率为34.90%;
- 糖尿病患者的平均葡萄糖浓度、平均舒张压、平均皮褶厚度、平均血清胰岛素、平均体重指数、平均糖尿病谱系功能都比正常人高。患病者一般在27~47岁之间,怀孕次数在1~8次之间;
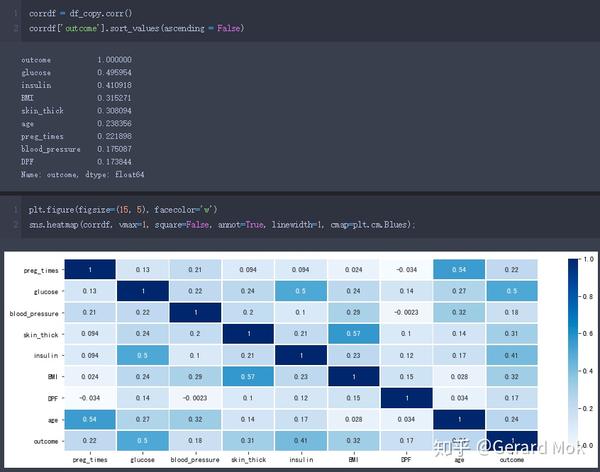
- 与糖尿病相关性较强的参数为glucose、insulin、BMI、skin_thick;
- 使用逻辑回归预测模型,在被预测的154名皮马印第安女性中,共124人被准确预测,预测准确率为80.5%。
图片上传后被严重压缩,如图法无法看清,请移步至CSDN论坛:
https://
blog.csdn.net/Gerard_mo
k/article/details/99778829
一、数据集介绍
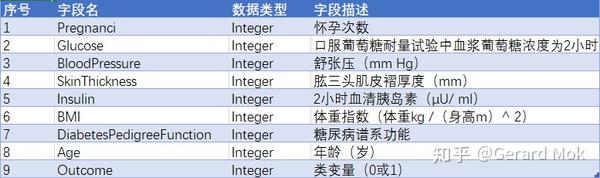
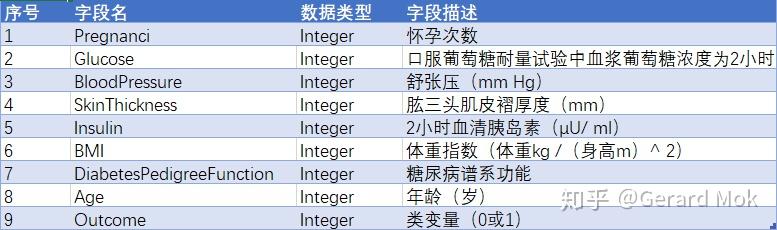
该数据集源至美国国家糖尿病、消化及肾脏疾病研究所。 数据集的目的是根据已有诊断信息来预测患者是否患有糖尿病。 但该数据库存在一定局限性,特别是数据集中的患者都是年龄大于等于21岁的皮马印第安女性。
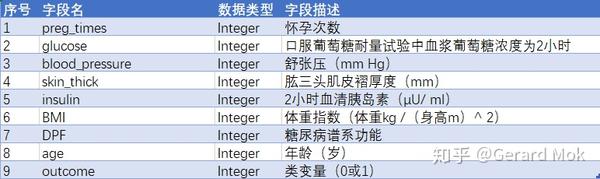
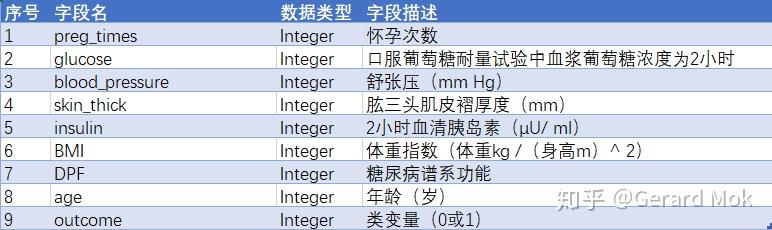
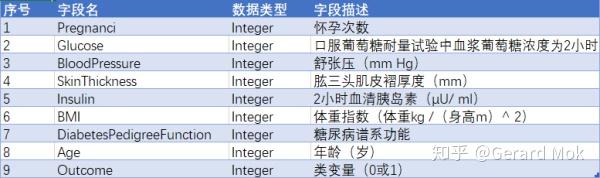
数据集由若干医学预测变量和一个目标变量Outcome组成,共九个字段。 预测变量包括患者的怀孕次数,BMI,胰岛素水平,年龄等。
二、项目分析
1 提出问题
是否可以利用现有数据准确预测人是否患有糖尿病?
2 理解数据
简单查看表格内容。首先需要更改列名为更好的理解和使用。
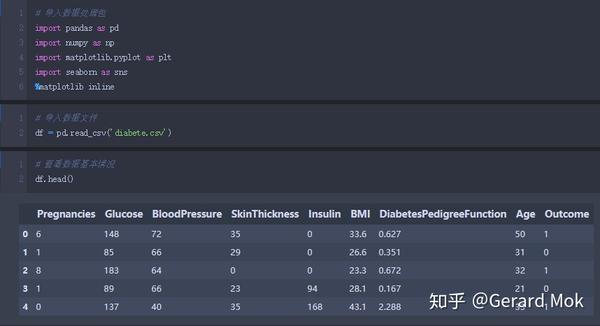
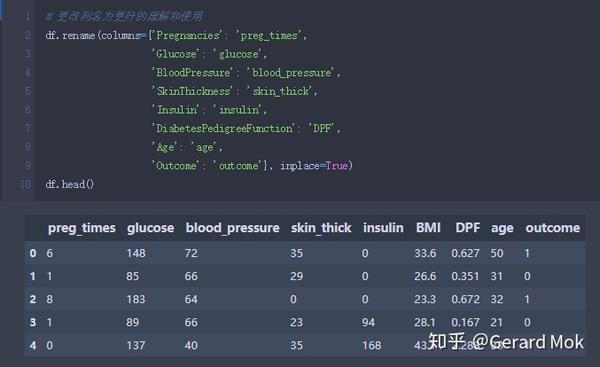
新表列名信息如下:
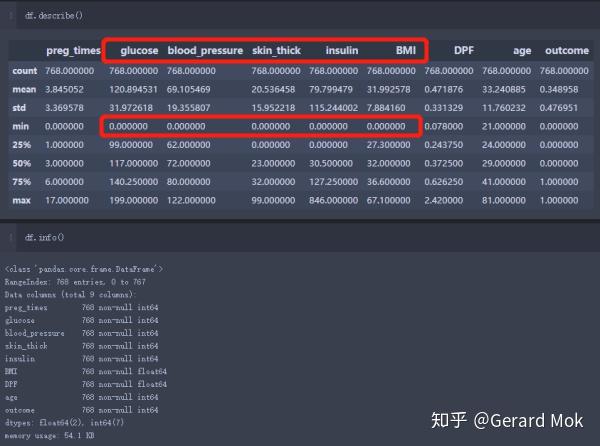
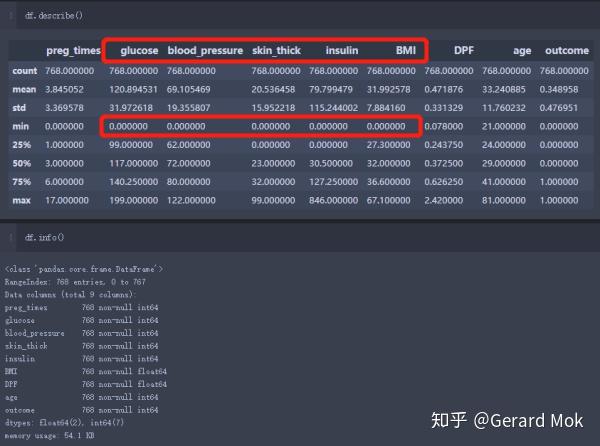
2.1 查看数据概况、数据类型
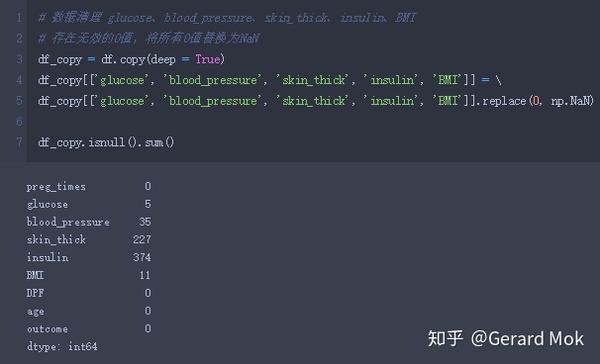
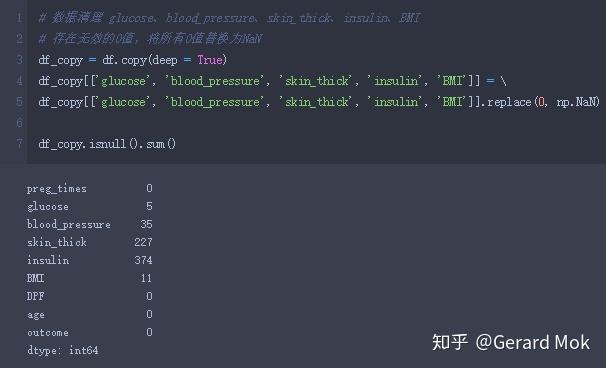
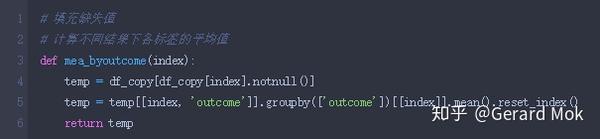
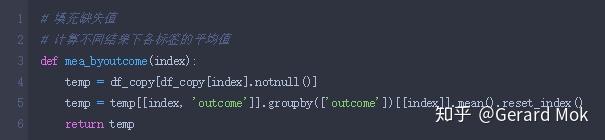
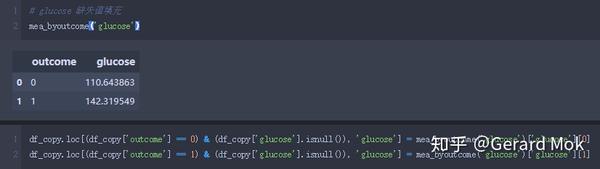
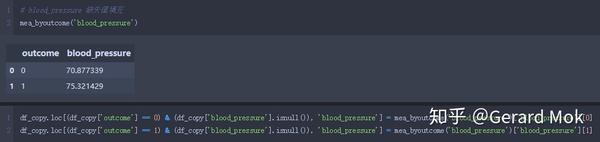
glucose、blood_pressure、skin_thick、insulin、BMI 最小数据不应为0,可理解这些数据列没有数据录入,存在数据缺失。处理思路:1.将这些列的0值转换成NaN值;2.根据outcome的结果计算出各列的平均值;3.使用平均值填充缺失值。
数据类型都为数值类型。
3 数据清洗
3.1数据预处理
将glucose、blood_pressure、skin_thick、insulin、BMI 0值替换为NaN值。
自定义计算各列平均值的函数。
glucose 缺失值填充。
blood_pressure 缺失值填充。
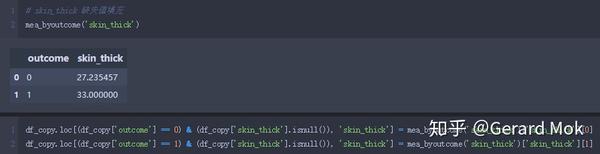
skin_thick 缺失值填充。
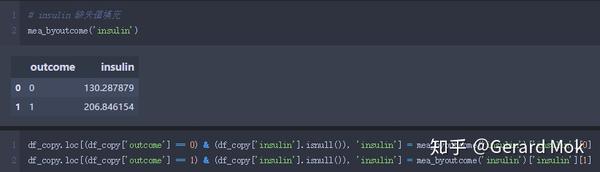
insulin 缺失值填充。
BMI 缺失值填充。
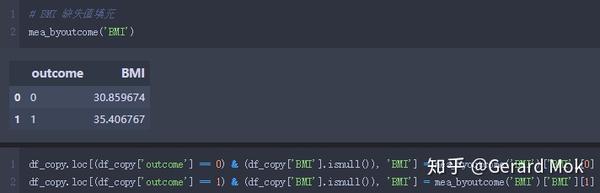
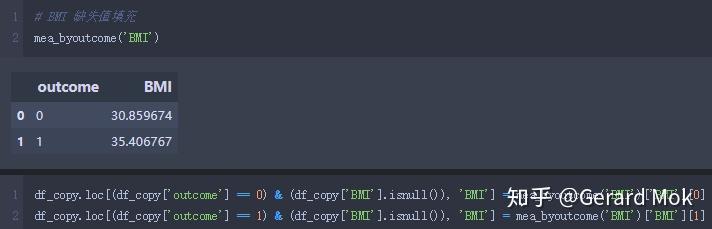
填充完毕后,查看各列缺失值,数据集无缺失值。

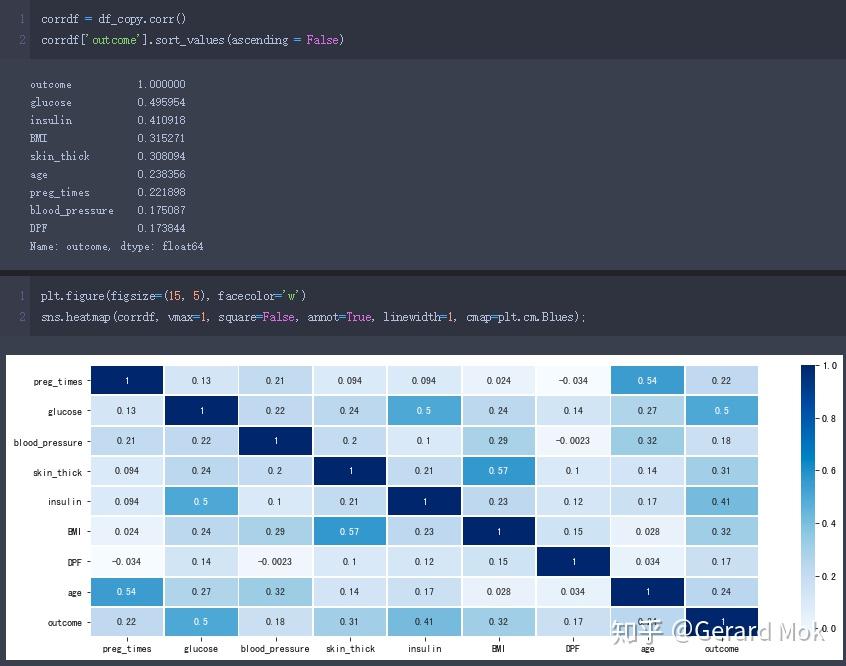
以outcome为标准作热力图,可以查看各参数的数据分布及它们之间的相关数据分布,本项目不对参数的组合影响做更多的拆解分析。
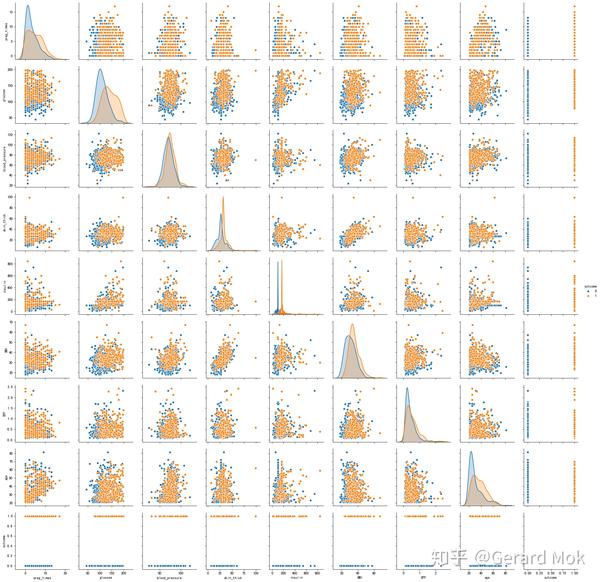
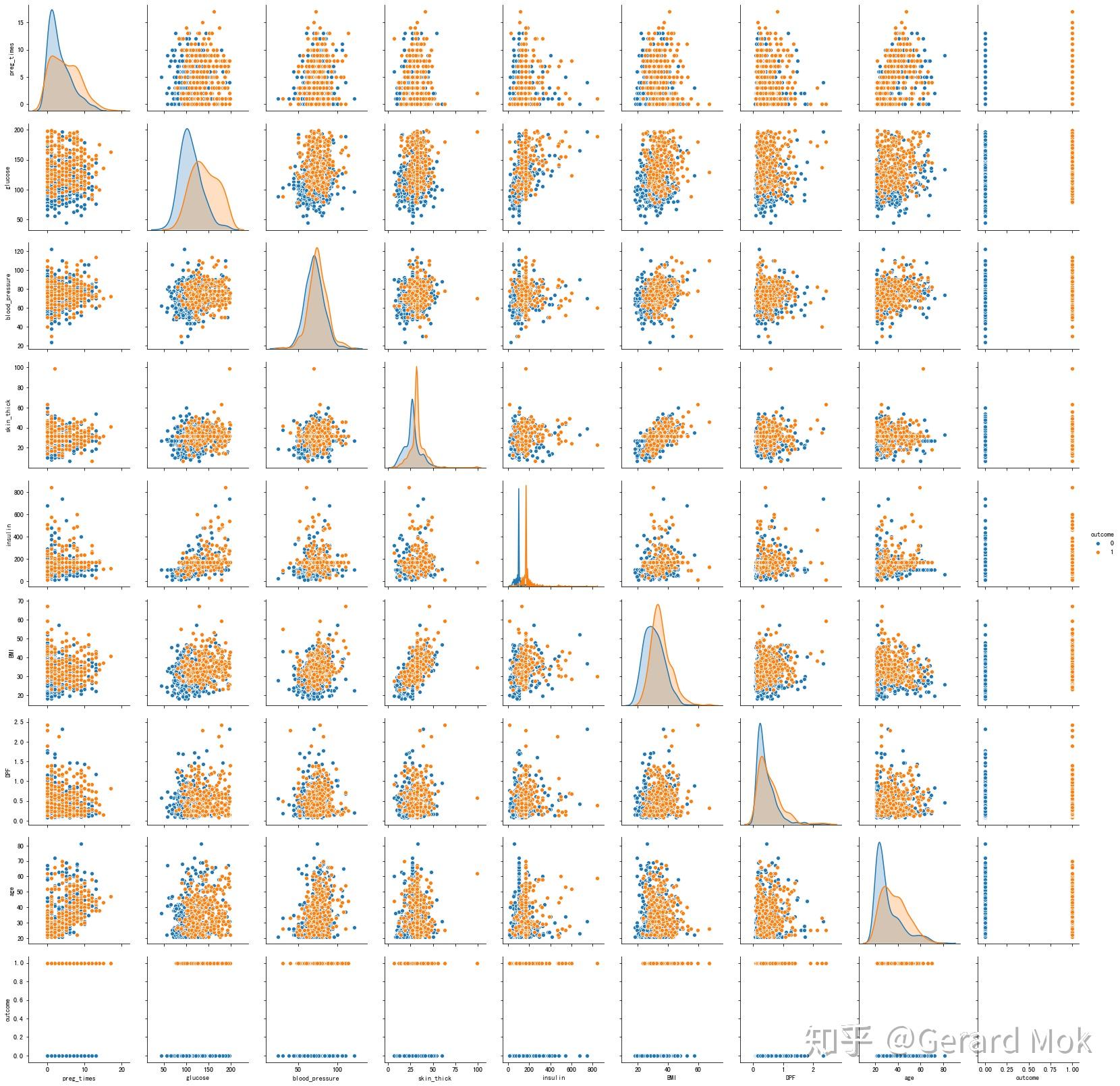
3.2 特征选取
在特征选取中采用相关系数法,可见各参数与outcome的相关系都较高,且都为正相关关系,因此所有参数都应在预测时被考虑。相关性较强的前三参数是glucose、insulin、BMI,相关系数分别为0.50、0.41、0.32。
另外值得注意的是glucose与insulin、skin_thick与BMI有较强的正相关性。
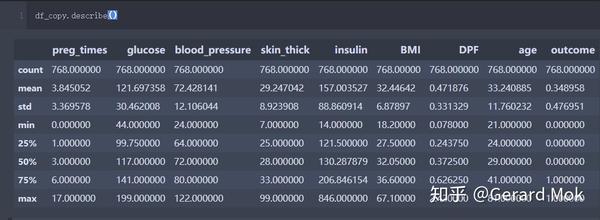
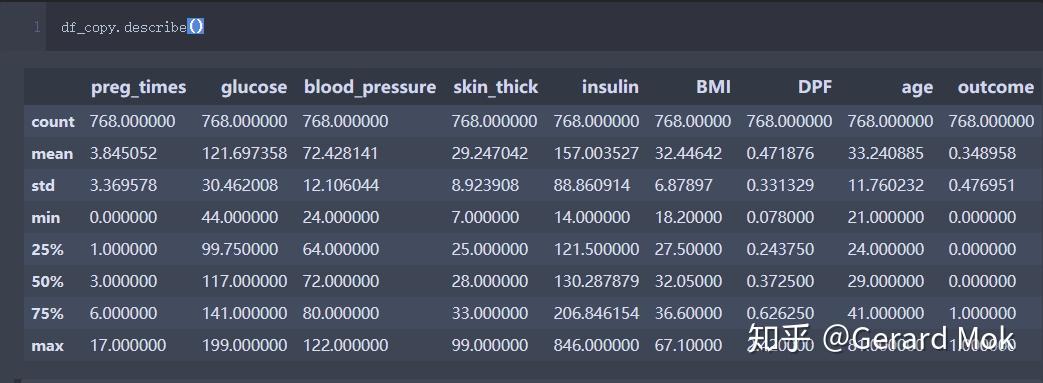
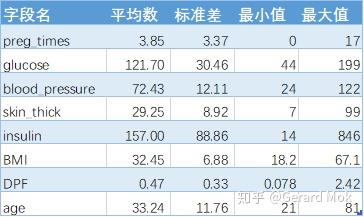
在数据标准化前查看一次整体数据描述统计信息。
查看没有患病组的描述统计信息。
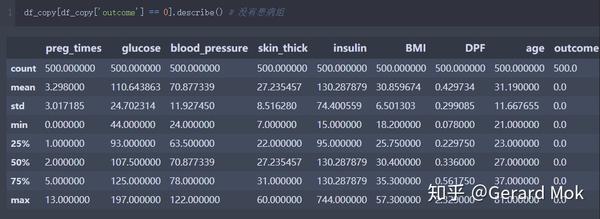
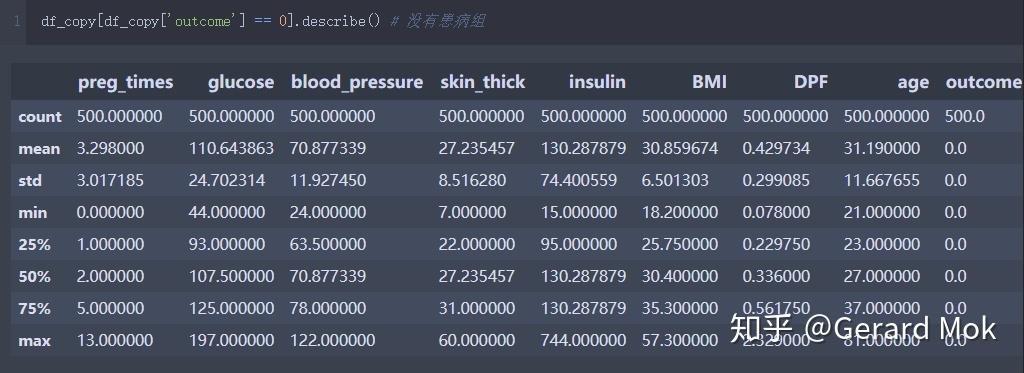
查看患糖尿病病组的描述统计信息。
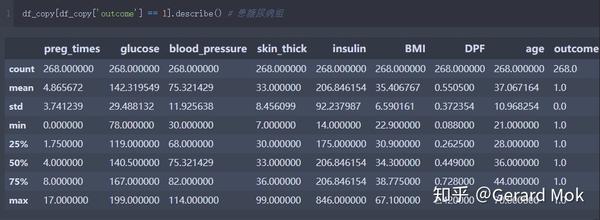
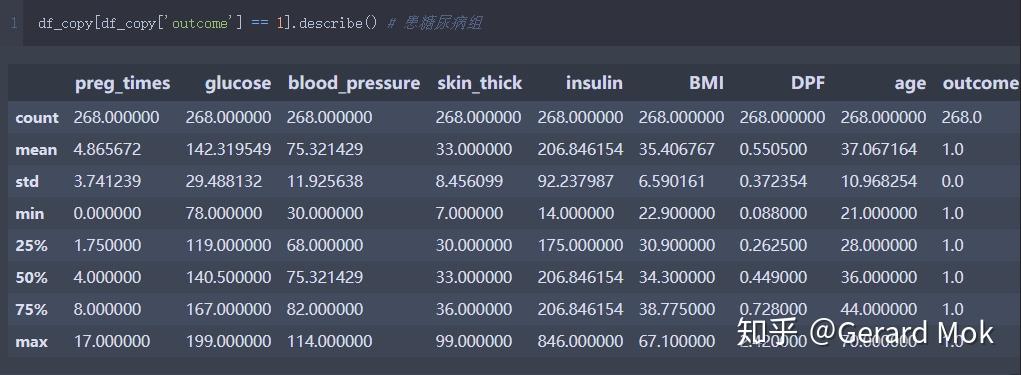
3.3 数据标准化
为了让数据有可比性,需进行数据标准化,以下使用StandardScaler模型进行标准化。标准化后的数据如下表。
4.构建模型
首先查看数据集中糖尿病患者人数,768人中,有268人患病,500人不患病,患病率为34.90%。
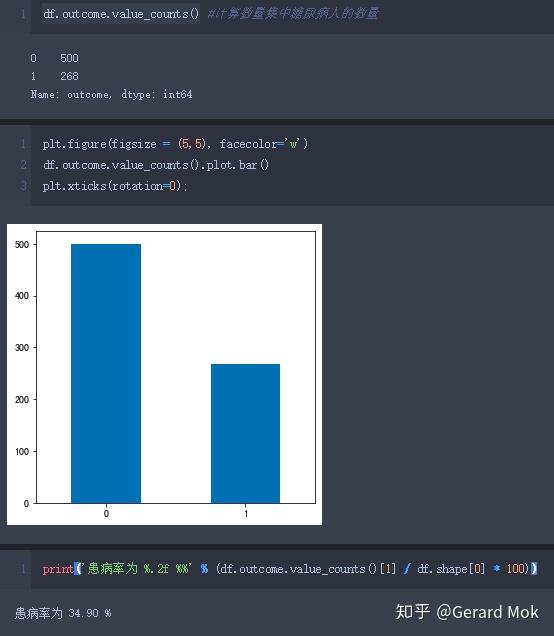
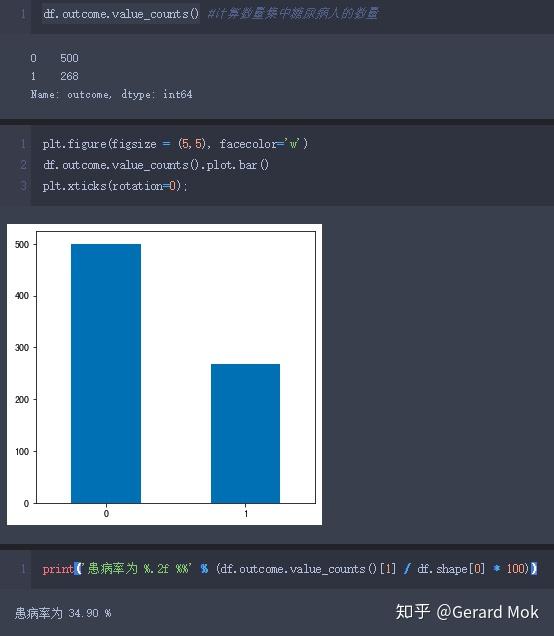
4.1 构建预测模型
将数据集拆分为80%的训练集和20%的测试集。训练集有614条数据,用于训练模型。测试集有154条数据,用于模型结果预测。
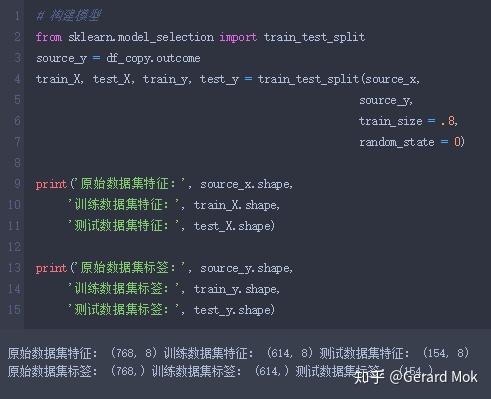
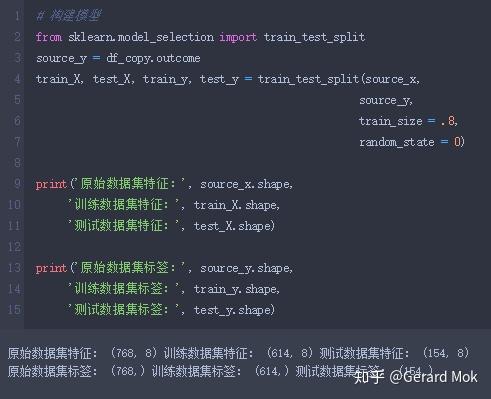
4.2 训练模型
选用逻辑回归算法训练模型。
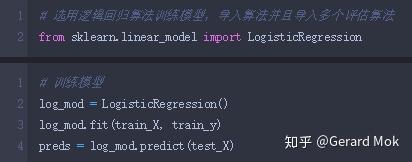
5.评估模型
使用2种方式评估该模型。


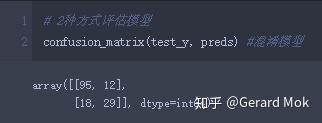
1.混淆模型
在混淆矩阵中可知,154名皮马印第安女性中,被正确识别为未患糖尿病的正常人数量为95名, 被正确识别为患糖尿病的糖尿病患者数量为29名,被识别为未患糖尿病的糖尿病患者为12名,被识别为糖尿病的正常人为18名。
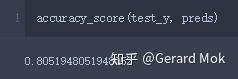
2.准确率
表示模型预测皮马印第安人是否患糖尿病的准确程度。
最终计算结果为80.52%
。
三、项目总结
描述性分析结论:
- 768人中,有268人患病,500人不患病,患病率为34.90%;
- 糖尿病患者的平均葡萄糖浓度、平均舒张压、平均皮褶厚度、平均血清胰岛素、平均体重指数、平均糖尿病谱系功能都比正常人高。患病者一般在27~47岁之间,怀孕次数在1~8次之间。
推断性分析结论:
- 与糖尿病相关性较强的参数为glucose、insulin、BMI、skin_thick,
- 在被预测的154名皮马印第安女性中,共124人被准确预测,预测准确率为80.5%。
四、后续改进
本次预测准确率为80.52%,为提高预测准确率,可进行以下措施:
1.数据收集,补充21岁以下人群及男性的数据,进一步扩大各年龄段的人数;
2.进行特征工程对模型参数进行改进,如提取各参数的的组合效果对outcome的影响。
编辑于 2019-08-21