|
|
|


如何在python中使用正则表达式提取嵌套标签?
关注者
5
被浏览
9,916
登录后你可以
不限量看优质回答
私信答主深度交流
精彩内容一键收藏

这里基于python的requests库,结合re、xpath等模块和一些网络知识总结下爬虫基本内容,并结合大量可操作的案例,暂不深入爬虫框架。
实际上这些内容在早些时候就通过B站学习完了,只不过近期查看招聘JD,有几个岗位发现需要一些爬虫工作,就重新拿起来了,现总结下基础知识,再慢慢深入。
一、requests库
requests库是python基于urllib,采用apache2 licensed开源协议的第三方http库,专门发送http请求,比urllib更加简洁方便,节约大量的工作并满足大部分需求。
安装方式:pip install requests
相关方法和参数:
(1)post和get请求方法
requests进行http请求有post和get两种常用方式,实际具体的方法需要结合F12网页面板查看。两者有一些区别:
①get方法使用params参数赋值,post方法使用data参数赋值;
②get请求是从服务器上获得资源,post是向服务器提交数据;
③get方法将表单数据按照name=value形式添加到action所指向的url后面,两者用?连接,各个变量之间用&连接;post将表单数据放在http协议的请求信息头中,传递到action所指向url;
④get传输数据受到url长度显示,post可传输大量数据,上传文件通常用post方式;
⑤get参数会显示在地址栏上,数据不敏感可使用get;数据敏感则使用post。
(2)url参数:
是requests发起请求的地址。
(3)headers请求头
发送请求过程中请求的附件内容携带着某些必要的参数。
(4)cookies
本地字符串数据信息,各种字符串包括用户登录信息和反爬token(防止各种攻击和反爬)等。
(5)User_Agent
请求载体的身份标识,即用什么发送的请求。
(6)Referer
防盗链,防反爬。
(7)proxies
用来设置代理ip服务器。
(8)params和data
get方法使用params参数赋值,post方法使用data参数赋值。
(9)在实际操作中,一般要在爬取网页上通过F12打开网页工具,来辅助爬虫,包括查看上述的参数信息。
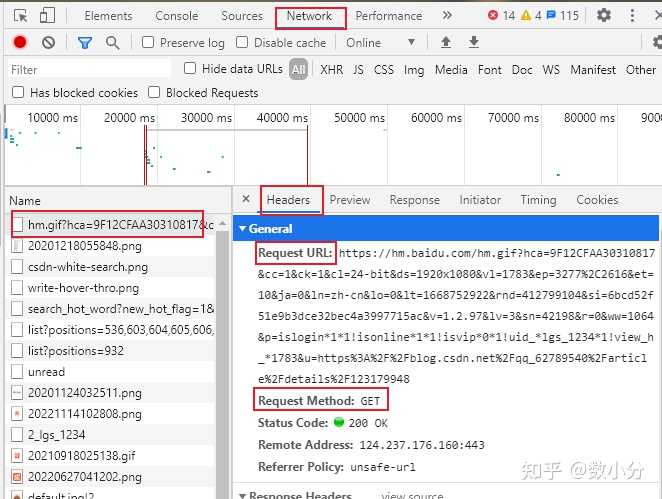
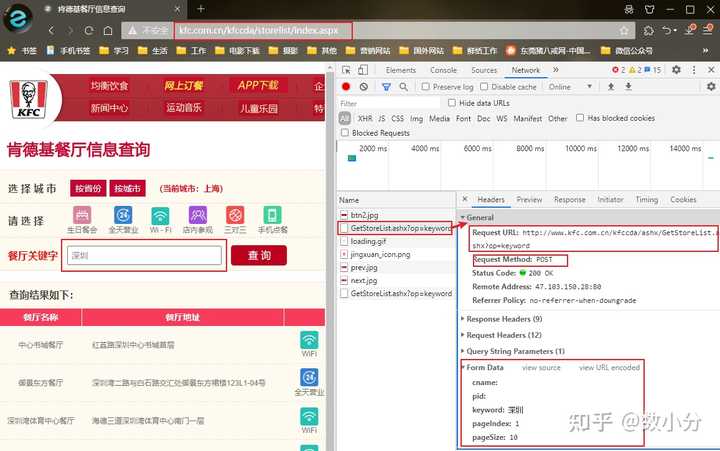
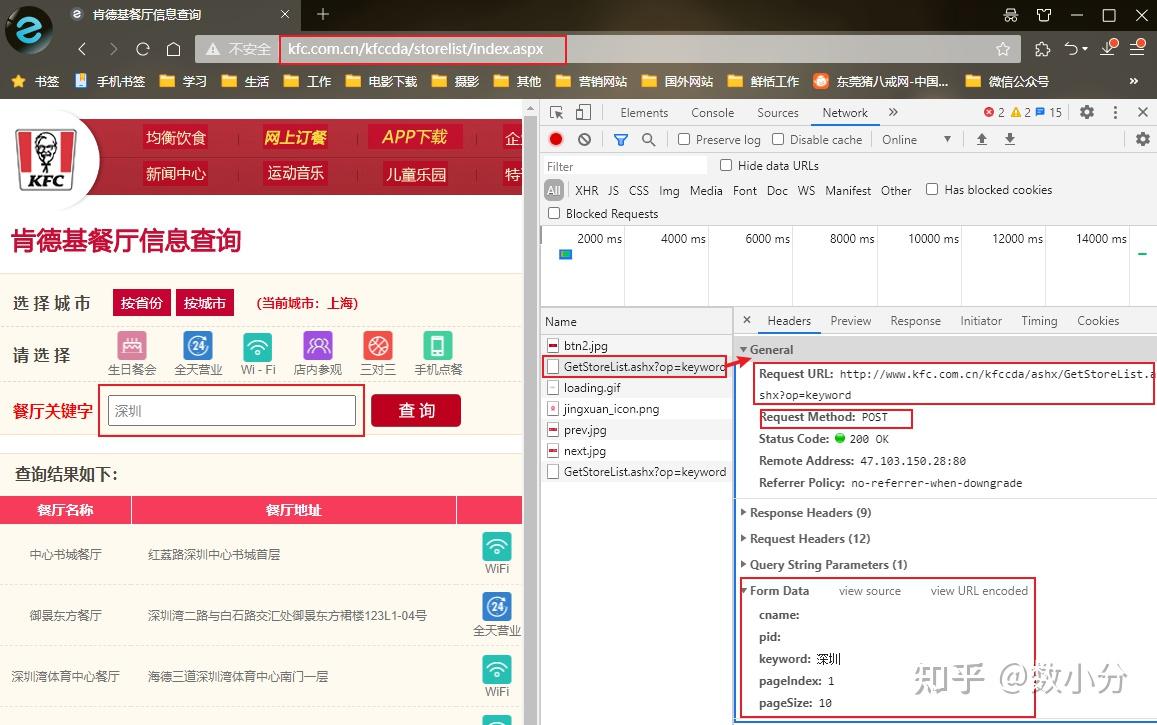
案例:爬取肯德基各地所有门店信息 http://www. kfc.com.cn/kfccda/store list/index.aspx
进入网页,查询“深圳”即可显示深圳地区的门店信息,通过F12调出工具,可以查看到URL,post请求方式,以及from data的参数,通过该部分参数可调出各个地区门店信息。
import requests
#人工输入城市名称
city=input("输入城市:")
#参数data和url
data={
"cname":"",
"pid":"",
"keyword":"深圳",
"pageIndex":"1",
"pageSize":"10"
url="http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=keyword"
#post方式请求数据
resp=requests.post(url,data=data)
#可通过resp.text查看返回的时候符合json格式,符合该格式则可用json()将字符串格式信息转化为字典信息,便于后续数据的收集
dict=resp.json()
#获取的是字典,只需要字典里“table1”对应的字典信息
dict1=dict["Table1"]
#循环输出字典信息
for i in dict1:
print(i)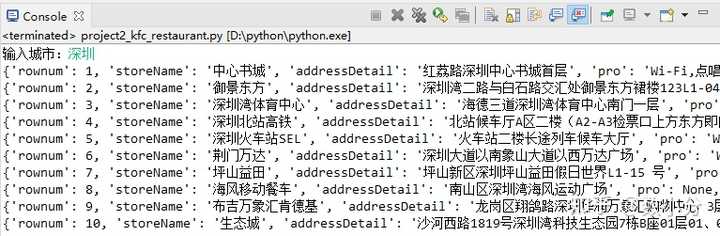
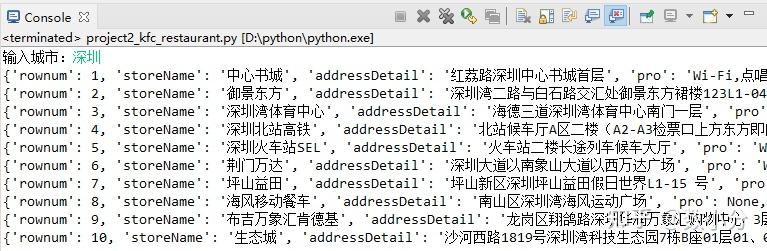
可通过一些变换将这些信息存放到csv文件或数据库中。
二、re模块和正则表达式
通过上面可以发现,对于json格式的内容,可以通过json()方法转换为字典类型,这样就很方便进行数据的收集保存;但如果不是json格式的内容,就要使用其他方法来从返回的信息中获取想要的内容,这部分就介绍下re模块和正则表达式来获取目标信息。
1、正则表达式
正则表达式是用来匹配字符串的一门表达式语言。可通过oschina网站( https:// tool.oschina.net/regex/ )进行正则表达式的测试。
正则表达式支持的匹配字符有几种:
①支持普通字符
②元字符,一个符号匹配一堆内容
\d能够匹配一个数字0~9
\w能够匹配数字、字母、下划线(0~9,a~z,A~Z,_)
\W除了数字、字母、下划线以外的内容
\D除了数字以外的内容
\s匹配任意的空白符
\n匹配一个换行符
\t匹配一个制表符
^匹配字符串的开始
$匹配字符串的结尾
a|b匹配a或b
[abc]匹配a,b,c(里面的-表示到)
[^abc]除了a,b,c
.除了换行符以外的其他所有内容都可被匹配
()匹配括号内的表达式,也表示一个组
③量词,控制前面的元字符出现的频次
+,前面元字符出现一次或多次(如\d+)
*,前面元字符出现0次或多次(文字算零次,数字则尽可能多的匹配出来,贪婪机制)
?,前面元字符出现0次或1次
{n}重复n次
{n,}重复n次或更多次
{n,m}重复n到m次
.*贪婪匹配
.*?惰性匹配
④惰性匹配.*?匹配到距离xxx最近的内容
玩儿吃鸡游戏,晚上一起上游戏,干嘛呢?打游戏啊
玩儿.*游戏,匹配到“玩儿吃鸡游戏,晚上一起上游戏,干嘛呢?打游戏”
玩儿.*?游戏,匹配到“玩儿吃鸡游戏”,这个就是惰性匹配
2、re模块
re模块是python的一个库,用于创建一个规则表达式,并借用各种匹配方法来验证和查找符合规则的文本,广泛用于各种搜索引擎、账目密码的验证等。
这里介绍下几个常见的匹配方法:
①search方法:在整个目标文本中进行匹配;
result=re.search(r"\d+","今天有100块,买了两个蛋糕") #只拿到第一个结果就返回
print(result.group())#不加group则返回match对象②findall方法:扫描整个目标文本,返回所有与规则匹配的子串组成的列表,如果没有则返回空列表;
result=re.findall(r"\d+","今天有100块,买了两个蛋糕") #拿到列表list
print(result)③finditer方法:扫描整个目标文本,返回所有与规则匹配的子串组成的迭代器;
result=re.finditer(r"\d+","今天有100块,买了两个蛋糕") #把所有结果放到迭代器
for item in result:
print(item.group())#不加group则返回match对象,拿到数据则需要group()④sub方法:将与规则匹配的子串替换成其他文本;
⑤split方法:从与规则匹配的子串进行切割,返回切割后子串组成的列表;
⑥匹配对象的方法,即对匹配到的对象进行使用:
():分组字符,可为匹配到的内容分组,快速获取到分组中的数据;
group:用于查看指定分组匹配到的内容;
groups:返回一个元组,组内为所有匹配到的内容;
groupdict:返回一个字典,包含分组的键值对,需要为分组命名;
#如果只想返回关键字内容,可以给关键字加上括号再给它取组名(?P<组名>正则表达式)
obj=re.complie(r"<div><a href="(?P<1组>.*?)">(?P<2组>.*?)</a></div>")
result=obj.finditer(s)
for item in result:
url=item.group("1组")
txt=itme.group("2组")
print(url,txt)
#可以直接print(item.groupdict())返回一个字典⑦re.compile(r"xxx"):预加载,编译正则表达式模式,返回一个对象。可把常用的正则表达式编译成正则表达式对象,方便后续调用及提高效率;
obj=re.compile(r"\d+")
result=obj.findall("今天有100块,买了两个蛋糕")
result=obj.search("今天有100块,买了两个蛋糕")
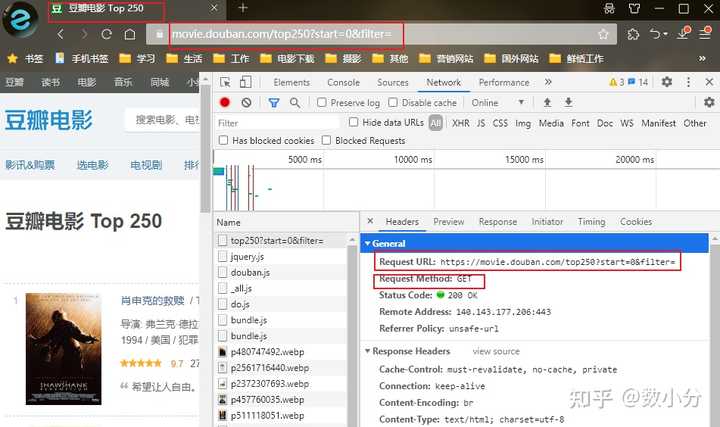
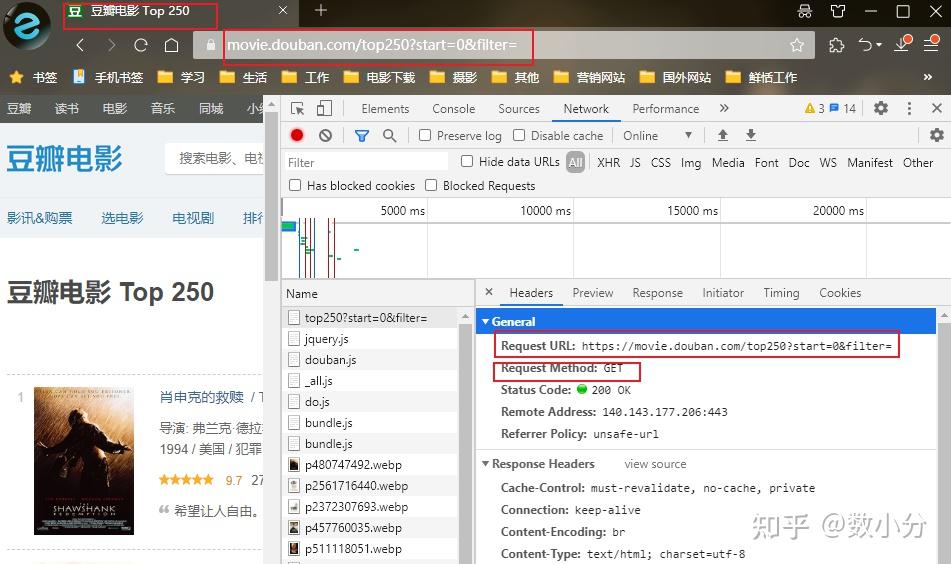
result=obj.finditer("今天有100块,买了两个蛋糕")案例:获取豆瓣 https:// movie.douban.com/ 网页下的top250电影信息。
通过F12网页工具可以知道:
①网页url,可通过该url来获取信息,实际上,内容是多页的,点击其它页时,url中的start参数会发生0,25,50……的变化,可根据该信息通过遍历获取全部的电影信息。
②请求方式是get。
③头文件headers中user_agent信息也可知道。
上述只获得了每一页的链接,要想获取每一页的电影信息,可页面右键点击“查看页面源代码”,找到关键信息;这里查找“肖申克的救赎”;可以发现每一部电影的信息展示格式都是固定的,就可以通过正则表达式来提取分组获取,这里我们可以使用如下的正则表达式:
#正则表达式是一组的,这里为了方便查看,分成了4组
#.*?用来匹配过滤掉无用的内容,防止篇幅过大;其次对获取的信息进行了分组命名,如(?P<name>.*?)
r'<div class="item">.*?<span class="title">(?P<name>.*?)</span>.*?'
r'(?P<year>.*?) .*?'
r'<span class="rating_num" property="v:average">(?P<store>.*?)</span>.*?'
r'<span>(?P<num>.*?)人评价</span>'

借助这些信息,完成豆瓣top250电影信息的爬取。
import requests
import re,json
#url="https://movie.douban.com/top250" #但这里只是第一页的数据信息,需要打印所有页的信息,要进行循环
for i in range(1,11):
page=(i-1)*25
url="https://movie.douban.com/top250?start={page}&filter="#加上页码要加上{}
header={
#UA,服务器对当前的网络设备进行检测
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36 SLBrowser/7.0.0.12151 SLBChan/8"
resp=requests.get(url,headers=header) #处理了一个反爬
resp.encoding='utf-8'
#print(resp.request.headers)
#查看头文件,发现豆瓣设置一个反扒,显示浏览器信息,看是人工还是自动化获取数据;而requests请求时都默认有一个请求头python_requests…,跟本身电脑名和浏览器不一致。
obj=re.compile(r'<div class="item">.*?<span class="title">(?P<name>.*?)</span>.*?'
(?P<year>.*?) .*?'
r'<span class="rating_num" property="v:average">(?P<store>.*?)</span>.*?'
r'<span>(?P<num>.*?)人评价</span>',re.S)
#re.S可以让re匹配到换行符
result=obj.finditer(resp.text)
#这里使用a模式追加,因为是通过循环获取电影信息,如果设置为w则只会保存到一页的电影信息
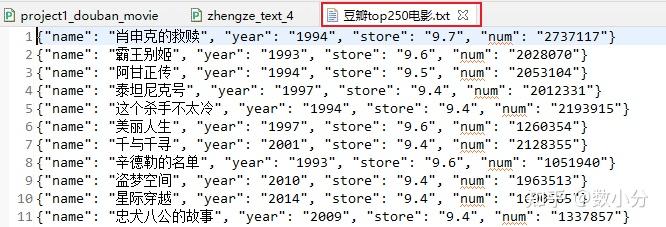
with open('豆瓣top250电影.txt',mode='a',encoding='utf-8') as f:
for item in result:
dic=item.groupdict()
dic['year']=dic['year'].strip() #去掉年份左右两端的空白(空格、换行符、制表符)
#json.dumps()将字典dict类型转换成str类型
f.write(json.dumps(dic,ensure_ascii=False)+'\n')#写入每条数据后,换行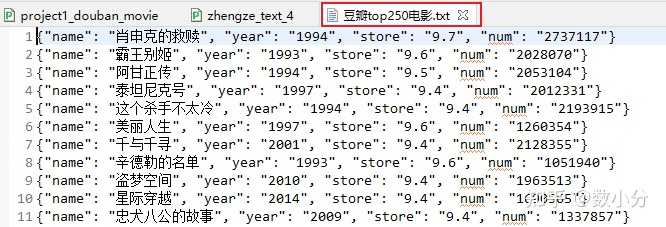
三、xpath解析器
xpath即XML路径语言,是用来确定XML文档中某部分位置的语言;是基于XML的树状结构,提供在数据结构中寻找节点的能力。因为html是xml的子集,所以也可以解析html。
需要安装lxml才能使用xpath:pip install lxml
常见的路径表达式:①/表示从根节点选取;②//从匹配选择的当前节点选择文档中的节点,而不考虑他们的位置;③.表示选取当前节点;④..表示选取当前节点的父节点;⑤@表示选取属性。
from lxml import etree
#若环境有问题不能导入额tree,则可以:
#from lxml import html
#etree=html.etree
#需要加载准备解析的数据
f=open("test.html",mode="r",encoding="utf-8")
pagesource=f.read()
#加载数据,返回element对象
et=etree.HTML(pagesource)
#xpath的语法
#result=et.xpath("/HTML") #/HTML表示根节点,返回的也是element元素
#result=et.xpath("/html/body") #表达式中间的/表示一层html节点
#result=et.xpath("/html/body/span/text()") #text()表示提取标签中的文本信息
#<li><a href="http://www.baidu.com">百度</a></li>,</a>前面的文字时展示在页面上的,href是当文字被点击触发的url链接地址
#获取文字
#result=et.xpath("/html/body/*/li/a/text()") #*任意的,通配符
#获取链接地址
#result=et.xpath("/html/body/*/li/a/@href") #@表示属性,@href表示a标签下的href属性获取
#result=et.xpath("//li/a/@href") #//表示任意位置
#result=et.xpath("//div[@class="job"]/a/@href") # [@class="job"]表示属性的限定
#带循环的
result=et.xpath("/html/body/ul/li")
for item in result:
href=item.xpath("./a/@href")[0] #./表示当前这个路径,想对查找
text=item.xpath("./a/text()")[0]
print(href,text)案例:获取动漫壁纸 https:// desk.zol.com.cn/dongman /
通过F12调出工具可以查看到“动漫”类型图片网页的URL和post请求方式,以及User-Agent;
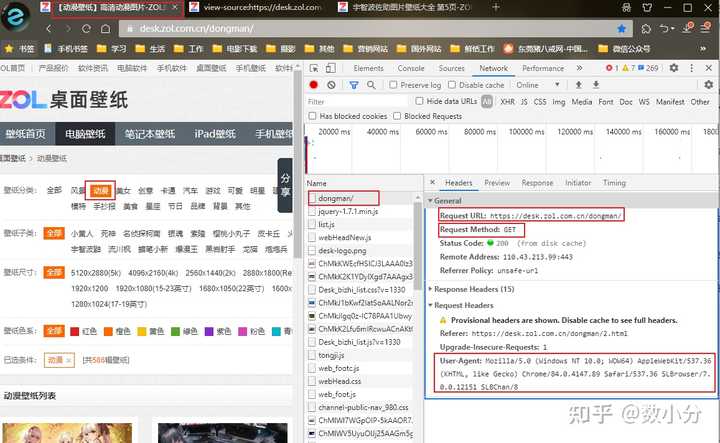
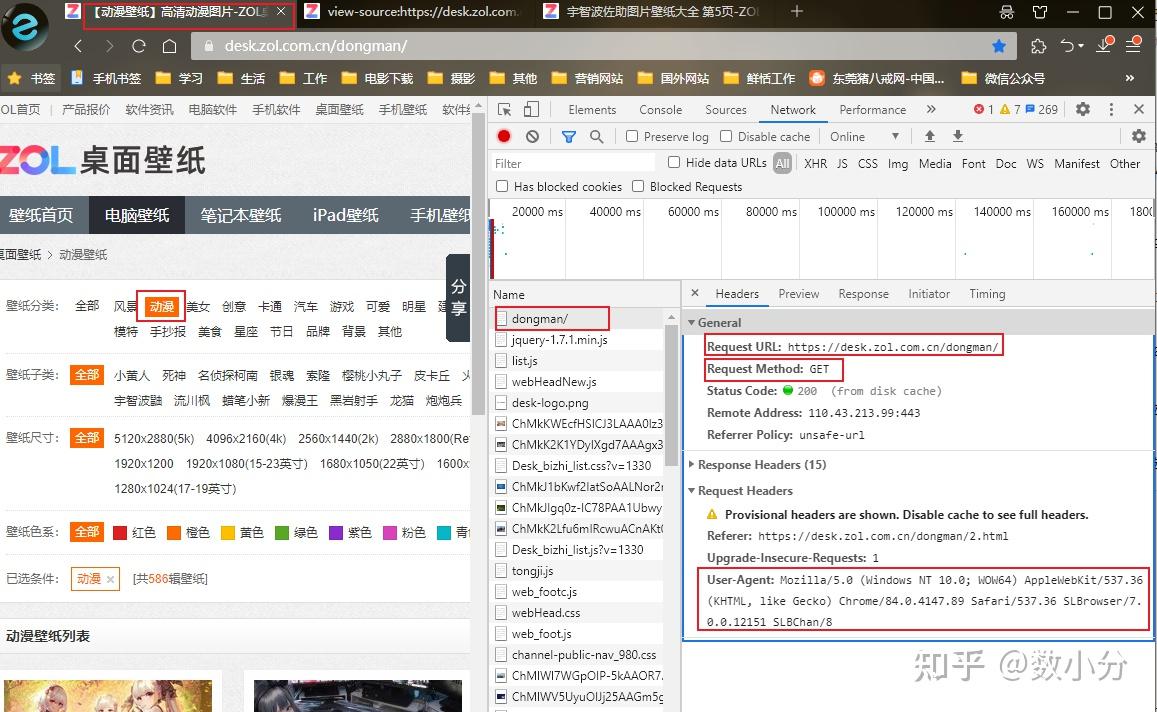
右键点击“查看网页源代码”,可以知道这里只有“动漫”类型图片的每组图片的链接;
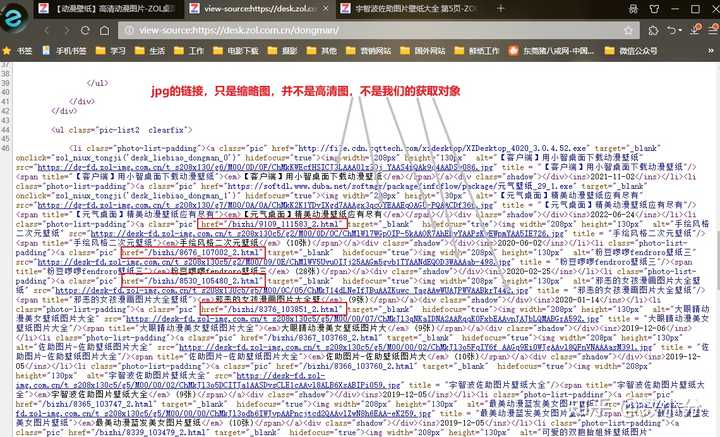
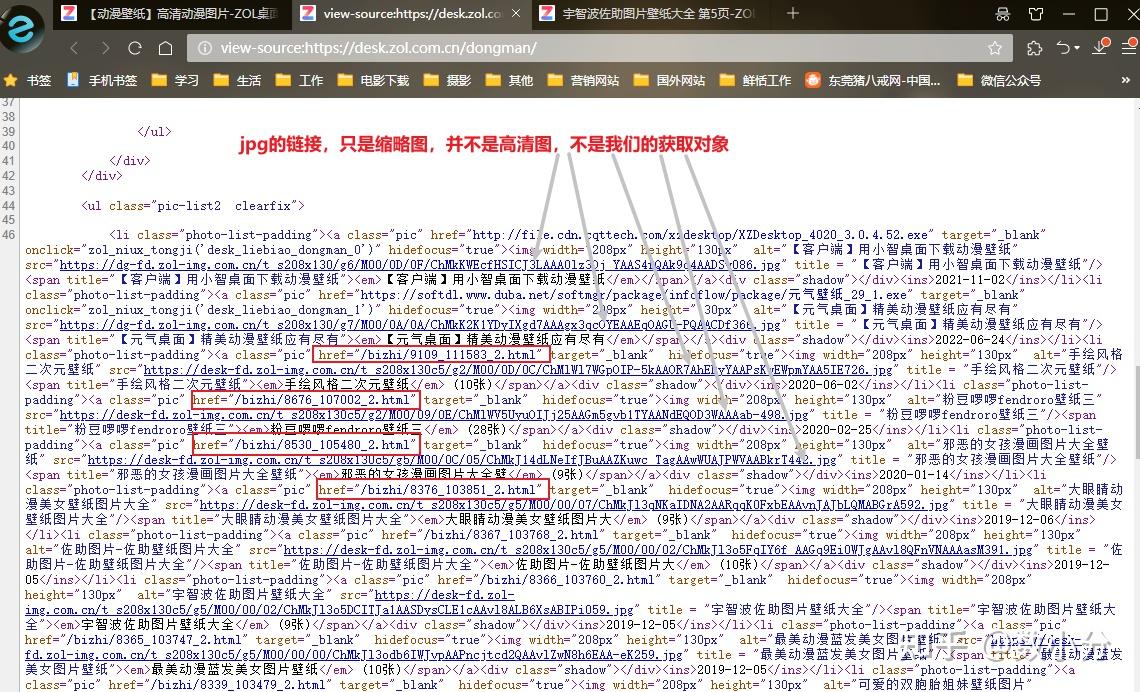
实际上,点击其中一个连接,如 /bizhi/8676_107002_2.html ,就会进入到一个高清图集网页,右键点击“查看页面源代码”;可以看到一个字典集合,包含了改组所有jpg图片和像素代码,在通过re模块就可以提取出来了。
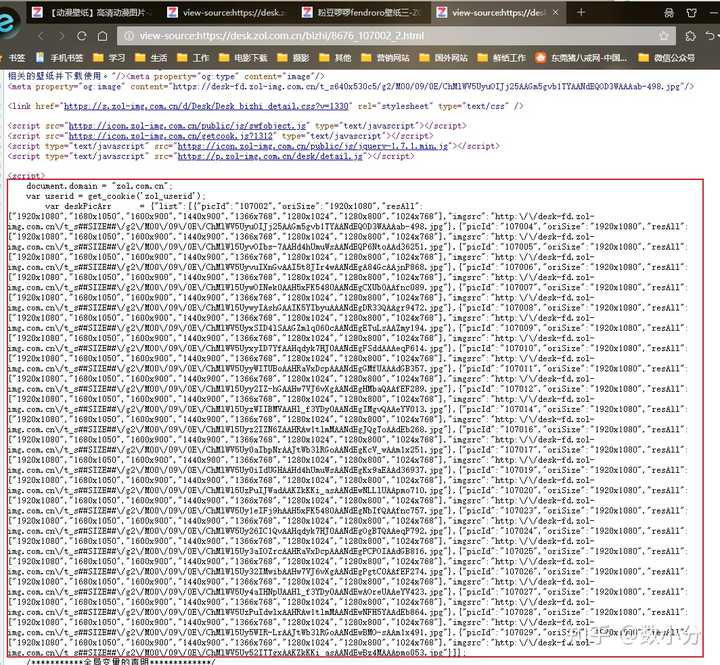
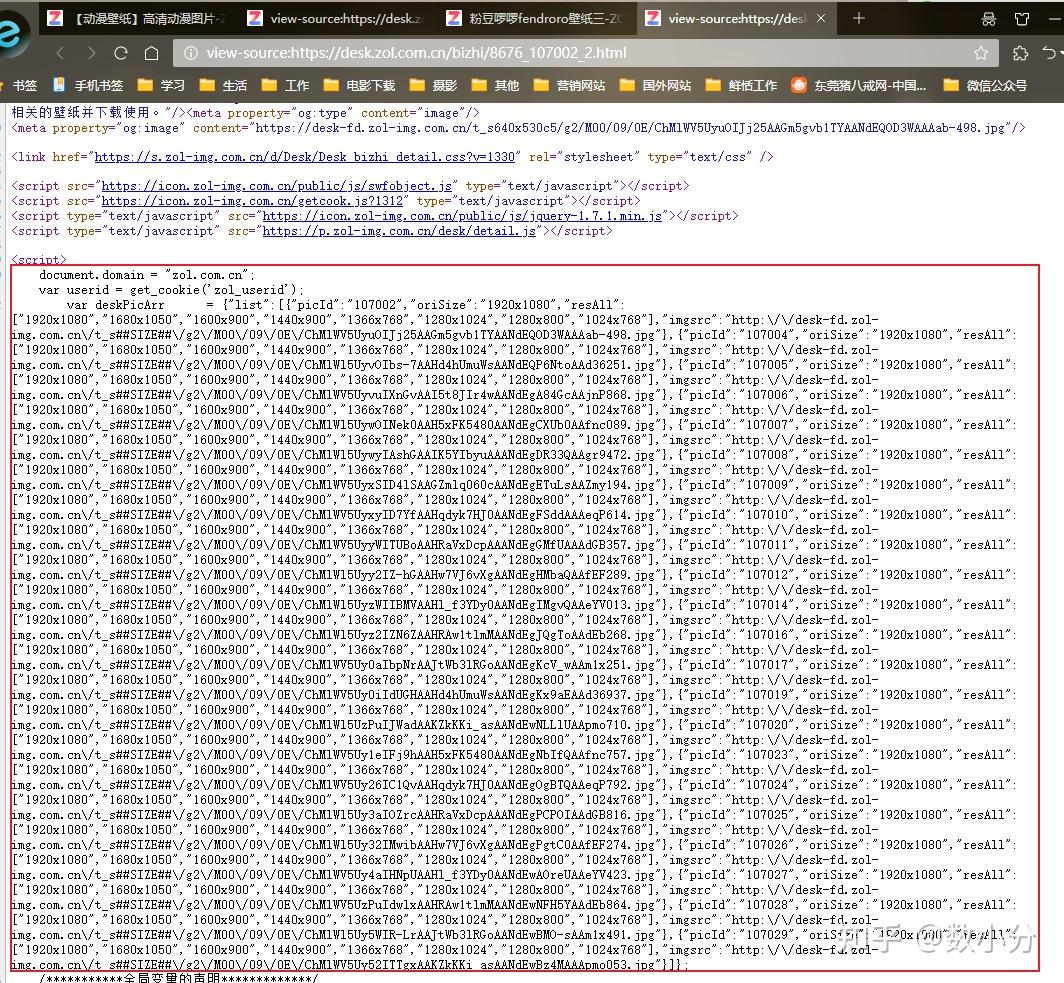
注意,通过上图可以看到,每个图片都有一个链接和一组像素,需要提取最大像素并添加到链接里;通过自行测试可以发现,链接里的“ ##SIZE##”部分就是要用像素替代掉的,这部分操作在代码里面有体现。
#获取某网页每个类别前四页的壁纸连接
import requests
from lxml import etree
import re,json
#获取网站地址
url="https://desk.zol.com.cn"
headers={"user-agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36 SLBrowser/7.0.0.12151 SLBChan/8"}
resp=requests.get(url,headers=headers)
resp.encoding='gbk'
#加载页面源代码信息
et=etree.HTML(resp.text)
###获取到所有的类别标签
result0=et.xpath("//dl[@class='filter-item first clearfix']/dd/a/@href")
result=[]
result=append(result0[1])
for i in result:
#获取到每个类别的链接
url1=url+i
for page in range(1,2):#获取一页的壁纸
#url2="https://desk.zol.com.cn/dongman/{}.html".format(page) #通过format()代入页面
###每个类别的一个页面链接
url2=url1+"{}.html".format(page)
#读取每一页链接
resp1=requests.get(url2,headers=headers)
resp1.encoding="gbk"
#加载页面源代码信息
et1=etree.HTML(resp1.text)
#获取到壁纸连接集合
result1=et1.xpath("//ul[@class='pic-list2 clearfix']/li/a/@href")
###将壁纸链接输出显示
for item in result1:
url3=url+item
#有些链接是没用的,需要过滤掉
if url3.endswith("html"):
###获取到壁纸链接后,就提取每个壁纸的全套高清图
#图片链接和大小比例在<script>的json脚本中
#是字典-列表-字典-键值的嵌套形式,用re比较合适
resp2=requests.get(url3,headers=headers)
#单独获取包含了图片信息的字符串,用于后续处理
obj=re.compile(r"var deskPicArr.*?=(?P<deskpicarr>.*?);",re.S)
result2=obj.search(resp2.text) #返回match对象
deskpicstr=result2.group("deskpicarr") #使用group拿到具有组名的字符串
#上述获取的是字典字符串,通过json转成字典
#json.loads()用来读取字符串,将str类型数据转换成dict类型
deskpic=json.loads(deskpicstr)
#该类型是deskPic字典下有list列表,list列表下有多个字典
#deskPic['list']表示出自己集合,get方法通过字典里的'键',获取'值'
for item in deskpic['list']:
orisize=item.get("oriSize") #获取到高清图的像素大小
imgsrc=item.get("imgsrc") #获取到图片地址
imgsrc=imgsrc.replace("##SIZE##",orisize)#将像素大小值代入连接地址值中,获取完全的地址
#print(imgsrc)
###下载图片
#发送网络请求
resp_img=requests.get(imgsrc)
#resp.text是获取文本,而此时是图片
#截取图片名称最后一部分作为下载图片的名称
name=imgsrc.split("/")[-1]
#resp.content拿到图片的字节,所以使用wb
with open(f'E:\爬虫\获取壁纸\{name}',mode='wb') as f:
f.write(resp_img.content)
#f'xxxx'把字符串格式化,使得可以在字符串中直接使用变量
#r'xxxx'把字符串转变为非转义的原始字符串
#u'xxxx'对字符串unicode编码
#b'xxxx'把字符串变成bytes格式
#f.close()就可以获取到图片啦:


四、多线程和多进程在爬虫中的使用
通过上述代码可知,在获取动漫图片时,是每获取一个链接,就用该链接下载图片,下载完成后再继续下一张图片下载,不断循环;在图片比较多时,下载速度就会很慢。就会思考,能否先获取到所有图片的链接,然后通过多线程来下载这些图片,这样下载速度就很快了。
线程是执行单位,进程是资源单位,每一个进程至少要有一个线程;关于多线程的详细和深入内容不详谈哈。
1、多线程
多线程:让程序能够同时执行多个任务
多线程创建步骤:
(1)导包 from threading import Thread
(2)创建任务 def func()
(3)创建线程 t=Thread(target=func,args=(xxxx,))
(4)启动线程 t.start()
from threading import Thread
def fun():
print(123)
if __name__=='__main__': #主线程
t=Thread(target=func) #创建一个子线程,并给线程安排任务
t.start() #启动一个线程,多线程状态为可以开始工作状态,具体执行时间由CPU决定
print(123)
#线程其他写法
class mythread(Thread):
def run(self):#当该线程被执行时,运行的就是run()
for i in range(1000):
print("子线程",i)
if __name__=="__main__":
t=mythread()
t.start()
for i in range(1000):
print("主线程",i)线程池: 一次性开辟一些线程,用户直接给线程池提交任务,线程任务的调度交给线程池来完成
from concurrent.futures import ThreadPoolExecutor
def func(name):
for i in range(1000):
print(name,i)
if __name=='__main__':
#创建线程池,这里表示线程池里开辟了20个线程,取决于CPU运算能力
with ThreadPoolExecutor(20) as t:
#submit把任务提交给线程池,这里表示有1000个任务
for i in range(1000):
t.submit(func,name=f"任务{i}")
#等待线程池中的任务全部执行完毕,才继续执行2、多进程
from multiprocessing import Process
def func():
for i in range(1000):
print("子进程",i)
if __name__="__main__":
p=Process(target=func)
p.start()
for i in range(1000):
print("主进程",i)案例:借用多线程来获取动漫壁纸 https:// desk.zol.com.cn/dongman /
这里思路跟第三部分差不多,只不过是改进了代码,加入了多线程,加快了下载速度,这里直接放入代码参考。
"""项目:获取车模第一页的所有照片"""
import requests
from lxml import etree
import re
import json
from concurrent.futures import ThreadPoolExecutor
domain="https://desk.zol.com.cn/"
details_url=[] #装有所有图片详情页路径的列表
def get_details_url(url):
""""获取第一个的所有图片的详情页的路径"""
resp=requests.get(url) #请求连接
resp.encoding='gbk'
et=etree.HTML(resp.text) #使用xpath处理html内容
details=et.xpath(r"//ul[@class='pic-list2 clearfix']/li/a/@href")
#循环获取各个详情页路径,并完善域名
for detail in details:
if detail.endswith("html"):#过滤掉无用的路径
detail_url=domain+detail
details_url.append(detail_url)
return details_url
img_src=[] #装载一个详情页图片的所有高清图的路径
def get_img_url(detail):
"""获取到每一个详情页下图片的所有高清图的路径"""
resp=requests.get(detail)
resp.encoding='gbk'
obj=re.compile(r"var deskPicArr.*?=(?P<deskstr>.*?);",re.S)
imgstr=obj.search(resp.text) #返回match对象,要拿到组名所在需用group()
img=imgstr.group("deskstr")
img_dict=json.loads(img) #将字符串类型转换字典类型
#处理形成完整高清图的路径
for img in img_dict["list"]:
orisize=img.get("oriSize")
imgsrc=img.get("imgsrc")
imgsrc=imgsrc.replace("##SIZE##",orisize)
img_src.append(imgsrc)
return img_src
def img_download(img):
"""下载图片"""
name=img.split("/")[-1] #截取路径最后一部分作为图片名称
print(f"{name}开始下载")
resp=requests.get(img)
with open(f"E:\爬虫\获取壁纸\{name}",mode='wb') as f:
f.write(resp.content)
print(f"{name}下载完成")
def main():
url="https://desk.zol.com.cn/meinv/"
#获取第一个的所有图片的详情页的路径
print("获取第一页的所有图片的详情页的路径……")
total_details_url=get_details_url(url)
print("获取第一页的所有图片的详情页的路径……完成!")
print(total_details_url)
print("获取到每一个详情页下图片的所有高清图的路径……")
total_imgs_url=[] #这里装载的所有详情页图片的所有高清图的路径
#获取到每一个详情页下图片的所有高清图的路径
for total_detail_url in total_details_url:
imgs_url=get_img_url(total_detail_url)
#这里循环,先获取到所有详情页图片的所有高清图的路径
for img_url in imgs_url:
total_imgs_url.append(img_url)
print("获取到每一个详情页下图片的所有高清图的路径……完成!")
#这里先让程序获取到所有的路径后,在通过线程池来同时下载图片
#下载图片
with ThreadPoolExecutor(10) as f: