


从0开始学stata-1

本次数据来自money.dta文件:
1. 变量的统计特征输出
(1)summarize 部分统计特征指标
显示变量的样本容量(Obs)、平均值(Mean)、标准差(Std.Dev.)、最小值(Min)、最大值(Max)
summarize
# 输出所有变量的统计指标,"summarize"可以缩写为"su"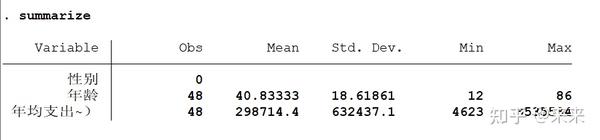

summarize 年均支出
# 输出变量名为"年均支出"的统计指标

summarize 年均支出 if 年均支出 >= 30000
# 输出满足"年均支出大于等于30000"条件的子样本的统计指标

summarize 年均支出,detail
# 新增统计指标百分位数(percentiles)、方差(variance)、偏度(skewness)与峰度(kurtosis)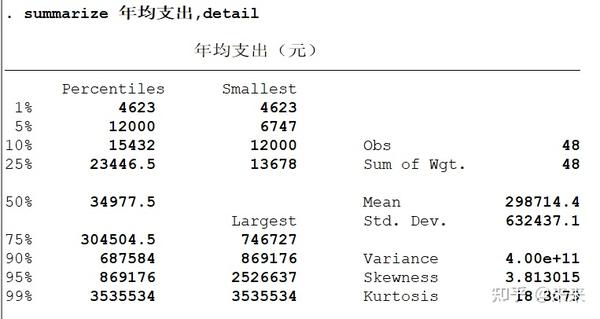

summarize,detail
# 显示所有变量的统计指标,包括百分位数(percentiles)、方差(variance)、偏度(skewness)与峰度(kurtosis)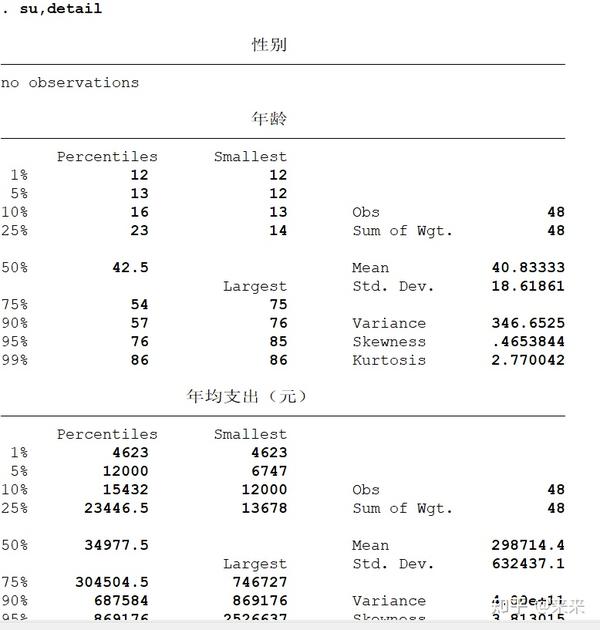

(2)tabulate 经验累积分布函数
tabulate 年均支出
# 显示变量名为"年均支出"的经验累积分布函数(empirical cumulative distribution function)
# "tabulate"可缩写为"ta"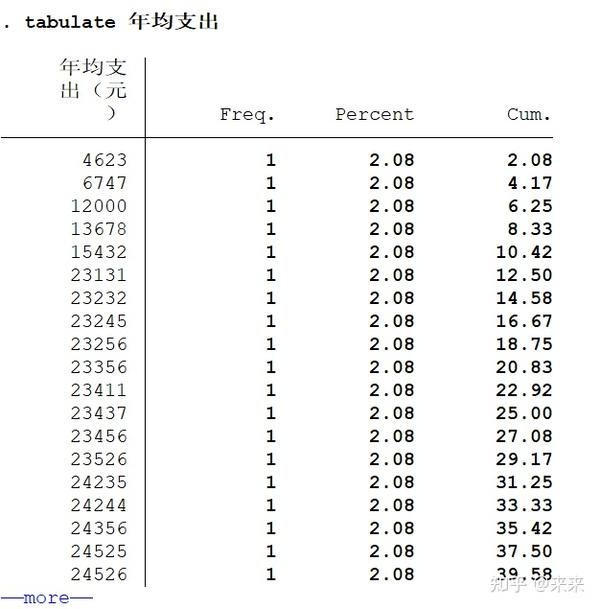

(3)pwcorr 变量间的相关系数
"pwcorr"表示"pairwise correlation"(两两相关),变量间的相关系数
pwcorr
# 显示所有变量间的相关系数,不可缩写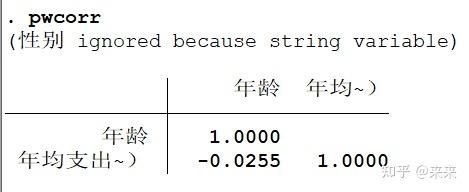

pwcorr 性别 年龄 年均支出,sig star(0.05)
# 选择项"sig"表示显示相关系数的显著性水平(即p值,列在相关系数的下方)
# 选择项"star(0.05)"表示给所有显著性水平小于或者等于5%的相关系数打上*号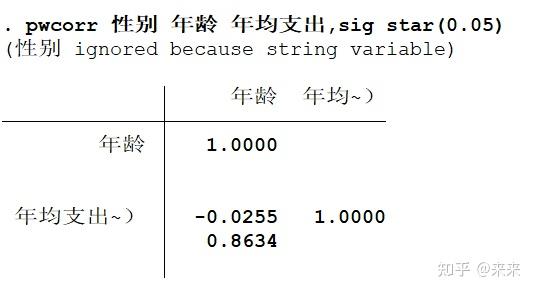

2. 画图
(1)histogram 直方图
histogram 年均支出,width(1000) frequency
# 显示变量名为"年均支出",组宽为1000的直方图,"histogram"可以缩写为"hist"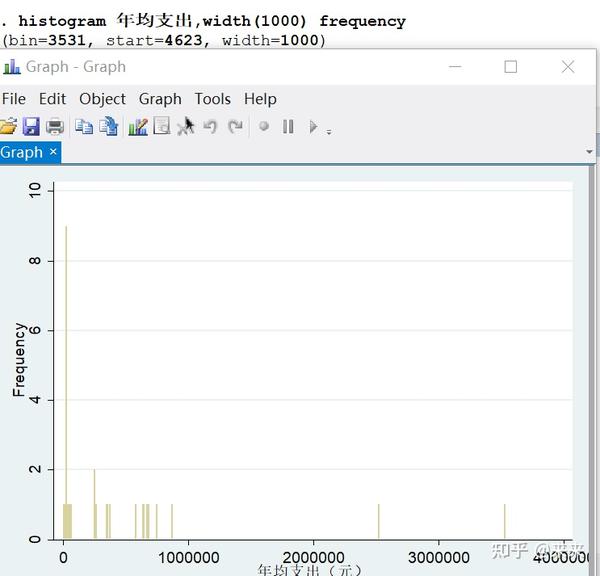

histogram 年均支出
# 不设定组宽长度,并且纵坐标默认为Density 频率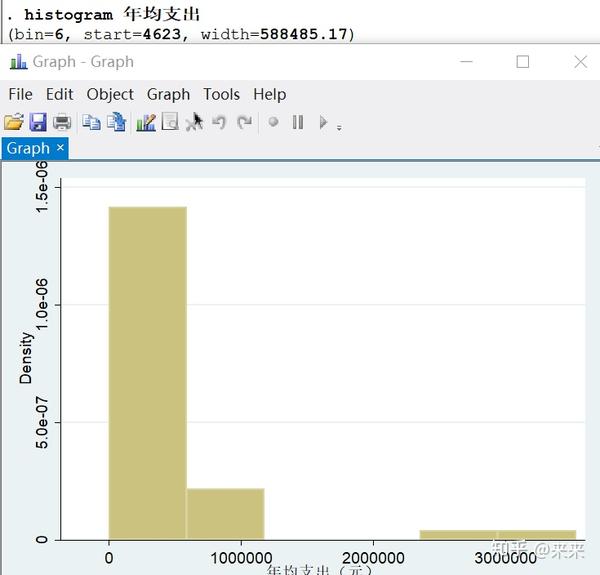

(2)kdensity 连续经验分布图
kdensity 年均支出
# 由于直方图不连续,显示连续的经验分布图,不可缩写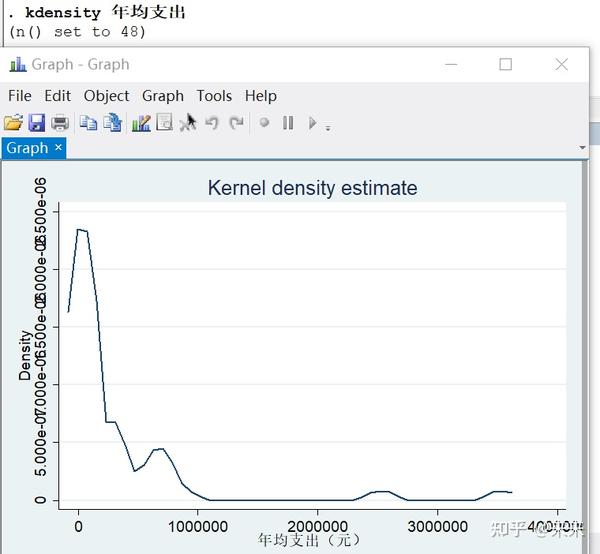

(3)scatter 散点图
scatter 年龄 年均支出
# 显示变量"年龄"与"年均支出"的散点图,"scatter"可缩写为"sc"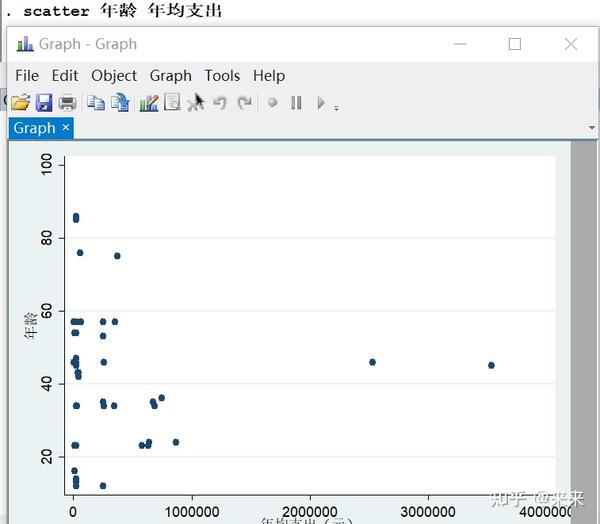

在上面的散点图中,我们无法知道每个点分别对应哪个观测值。为此,首先需要定义一个新变量"n"来表示第n个变量。
gen n=_n
scatter 年龄 年均支出,mlabel(n) mlabpos(6)
# "_n"表示第n个观测值
# 选择项"mlabel(n)"表示以变量"n"作为"mark label"(标签)
# 选择项"mlabpos(6)"(mark label position)表示将此标签放在散点正下方(6点钟方向),默认为散点的正右方(3点钟的位置)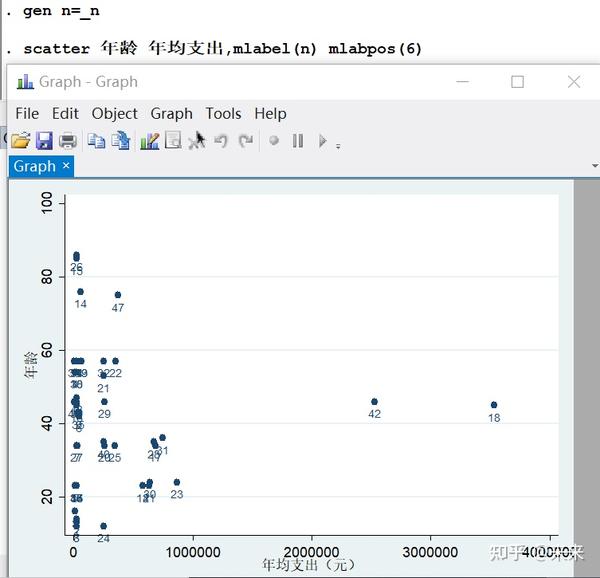

(4)twoway 散点图上的回归直线
想在散点图上画出回归线,可用如下命令:
twoway(scatter 年龄 年均支出)(lfit 年龄 年均支出)
#"lfit"表示"linear fit"(线性拟合)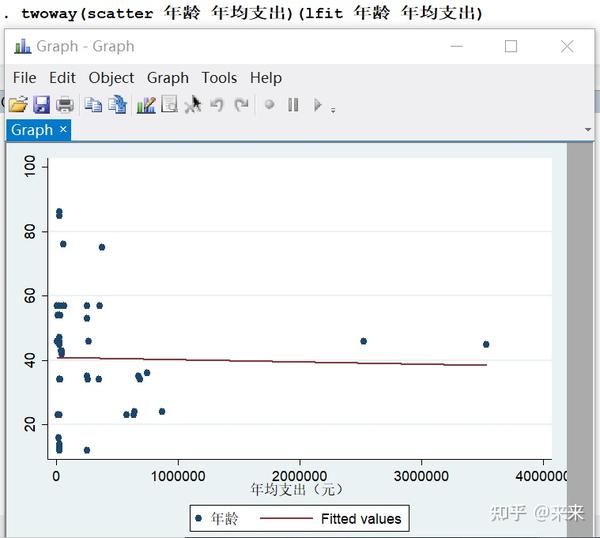

twoway(scatter 年龄 年均支出)(qfit 年龄 年均支出)