|
|
|


Elasticsearch机器学习是一种利用机器学习技术对Elasticsearch数据进行智能检测和预测的工具,可以自动识别数据模式和数据异常,生成新的特征和聚合结果,为数据分析和应用提供支持。Elasticsearch机器学习可以提高数据的可用性和价值,还可以为用户提供更加智能和高效的数据分析和应用解决方案。本文通过两个示例介绍无监督机器学习和监督机器学习的实践。
背景 信息
Elasticsearch机器学习分为无监督机器学习Unsupervised和监督机器学习Supervised两类:
-
无监督机器学习包括Single metric和Populartion等场景,对数据进行异常检测。该模式不需要训练机器学习什么是异常,机器学习算法将自动检测数据中的异常或异常模式。
-
监督机器学习包括Regression和Classification等场景,使用分类和回归算法解决非常复杂的问题。该模式需要一定的数据训练预测模型,然后使用训练出来的模型来对未来的数据进行分类、预测。
|
场景大类 |
场景 |
类别 |
说明 |
|
异常检测Anomaly Detection |
单一指标检测Single metric |
unsupervised |
检测单个时序中的异常,数据分析仅在一个索引字段上执行。 |
|
多指标检测Mutil metric |
unsupervised |
使用一个或多个指标检测异常,并根据需要拆分分析,数据分析在多个索引字段上执行。 |
|
|
填充Populartion |
unsupervised |
通过与Population中的行为进行比较,检测不寻常的行为。 Population是指某一研究领域内所有可能被研究的个体、事物或现象的总体。 |
|
|
高级用法和功能 Advanced |
unsupervised |
提供了更多的选项和设置,以便用户可以更好地定制和优化机器学习模型,以适应不同的应用场景和数据类型,用于更高级用例的机器学习。 |
|
|
归类Categorization |
unsupervised |
识别和分析日志消息中的特征和模式,将日志消息分为不同的组别,并检测其中的异常情况。 |
|
|
数据分析Data Frame Analytics |
离群值检测Outlier detection |
unsupervised |
聚类分析和异常检测算法来训练模型,用于快速检测数据中的异常点或异常行为。 |
|
回归Regression |
supervised |
回归预测数据集中的数值。 |
|
|
分类Classification |
supervised |
分类预测数据集中数据点的类别。 |
准备工作
-
创建阿里云Elasticsearch实例,本文使用8.5版本Elasticsearch实例。具体操作,请参见 创建阿里云Elasticsearch实例 。
说明不同版本Elasticsearch机器学习的使用可能存在差异性。更多信息,请参见 Machine learning官方文档 。
-
登录Kibana控制台。具体操作,请参见 登录Kibana控制台 。
-
添加样例数据。
-
在Kibana主页, 通过添加集成开始使用 区域单击 试用样例数据 。
-
在 样例数据 页签,单击 其他样例数据集 。
-
分别单击 Sample flight data 和 Sample web logs 数据集下的 添加数据 。
待 添加数据 变为 查看数据 时,表示该数据集已添加完成。添加样例数据后,Kibana会自动创建kibana_sample_data_flights索引和kibana_sample_data_logs索引。
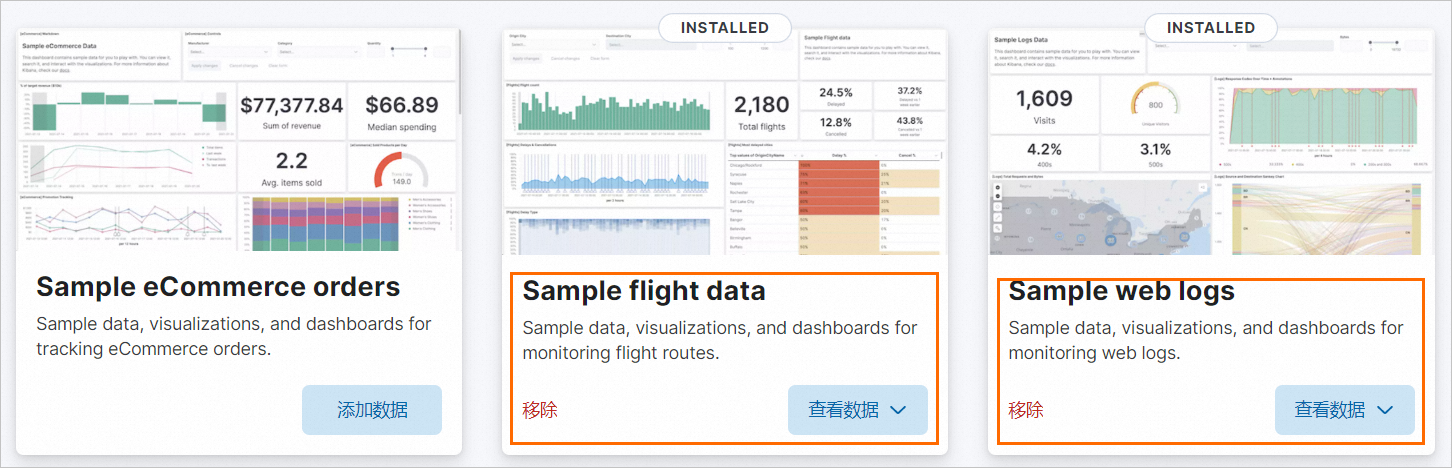
-
创建机器学习模型
本文通过以下两个示例介绍无监督机器学习和监督机器学习的实践。
创建单指标机器学习模型
本操作通过单指标检测构建一个无监督机器学习模型,使用Kibana自带的样例数据Sample web logs,该数据集为访问Web服务器的模拟数据,通过分析样例数据了解用户的访问行为、优化网站性能和检测异常访问等。
下面是数据集Sample web logs中的一条数据信息。
{
"_index": "kibana_sample_data_logs",
"_type": "_doc",
"_id": "n6GHI4gBmNQSVxOwNnPn",
"_version": 1,
"_score": null,
"_source": {
"agent": "Mozilla/5.0 (X11; Linux i686) AppleWebKit/534.24 (KHTML, like Gecko) Chrome/11.0.696.50 Safari/534.24",
"bytes": 847,
"clientip": "122.62.233.59",
"extension": "",
"geo": {
"srcdest": "CN:CO",
"src": "CN",
"dest": "CO",
"coordinates": {
"lat": 31.24905556,
"lon": -82.39530556
"host": "www.elastic.co",
"index": "kibana_sample_data_logs",
"ip": "122.62.233.59",
"machine": {
"ram": 4294967296,
"os": "win xp"
"memory": null,
"message": "122.62.233.59 - - [2018-08-21T02:34:54.901Z] \"GET /logging HTTP/1.1\" 200 847 \"-\" \"Mozilla/5.0 (X11; Linux i686) AppleWebKit/534.24 (KHTML, like Gecko) Chrome/11.0.696.50 Safari/534.24\"",
"phpmemory": null,
"referer": "http://twitter.com/success/paul-w-richards",
"request": "/logging",
"response": 200,
"tags": [
"success",
"info"
"timestamp": "2023-06-06T02:34:54.901Z",
"url": "https://www.elastic.co/solutions/logging",
"utc_time": "2023-06-06T02:34:54.901Z",
"event": {
"dataset": "sample_web_logs"
"fields": {
"@timestamp": [
"2023-06-06T02:34:54.901Z"
"utc_time": [
"2023-06-06T02:34:54.901Z"
"hour_of_day": [
"timestamp": [
"2023-06-06T02:34:54.901Z"
"sort": [
1686018894901
}
说明
您还可以通过Transforms对导入的数据进行聚合,将原始数据聚合为更高级别的指标或统计数据,并将聚合结果存储到新的索引中,提高查询性能和响应时间,并为后续的分析和机器学习提供基础数据。
-
单击Kibana页面左上角的
 图标,选择
Kibana
>
Machine Learning
。
图标,选择
Kibana
>
Machine Learning
。
-
在左侧菜单栏,单击 。
-
在 异常检测作业 页面,单击 创建作业 。
-
选择 kibana_sample_data_logs 索引。
-
在 从 数据视图 Kibana Sample Data Logs 创建作业 页面的 使用向导 区域,单击 单一指标 ,创建单指标任务。
-
配置单指标任务。
-
时间范围选择 使用完整的数据 ,单击 下一步 。
说明样例数据集里数据较少,所以选择使用完整的kibana_sample_data_logs数据。
-
选取字段 Count(Event rate) ,配置存储桶跨度和稀疏数据后,单击 下一步 。
说明Count(Event rate) 作为单指标视图的指标可以很好地反映出服务器在每秒内响应请求的次数,可以作为异常检测的目标。
-
存储桶跨度:用于将时间序列数据分成不同的块,以便进行分析和预测。该参数定义了每个时间段的持续时间,您可以根据业务需求进行调整。
-
稀疏数据:选择是否将字段中的空值视为异常。在机器学习中,数据的稀疏性是指数据中存在大量的空值(缺失值)。
-
-
输入 作业ID 和 作业描述 ,单击 下一步 。
-
时间范围和模型内存限制的验证没问题后,单击 下一步 。
-
-
在页面底部,单击 创建作业 。
Elasticsearch按照时序播放这些数据,并对数据进行分析学习建立模型,同时对后面的数据进行评估。
说明创建作业需要时间进行验证,花费的时间受索引数据的大小影响。
-
作业创建完成后,在页面左下角单击 查看结果 。
-
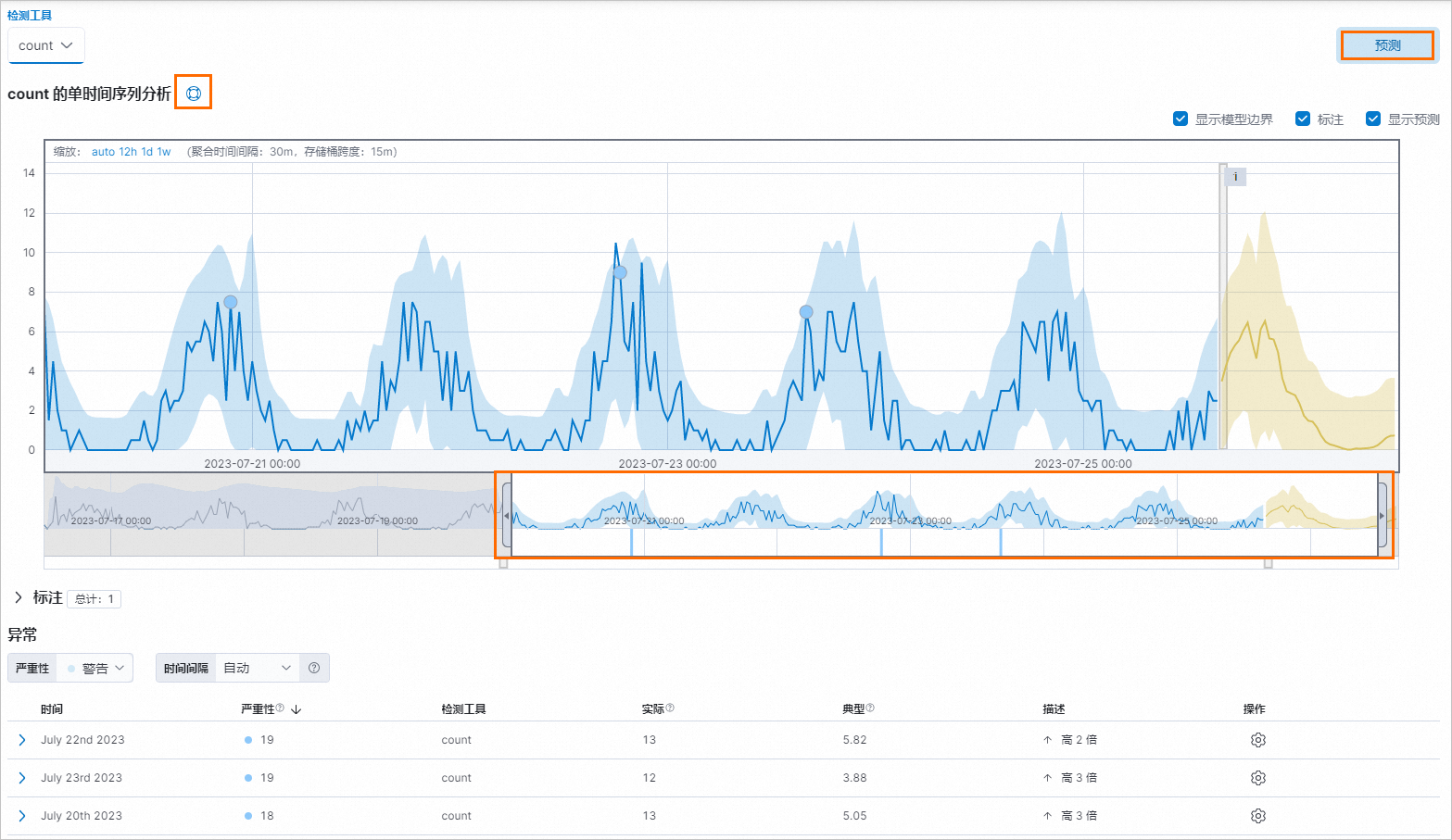
单击 count 的单时间序列分析 右侧的
 图标,查看单时间序列分析说明
。
图标,查看单时间序列分析说明
。
-
用鼠标左键拖动时间控制条的左右边缘或移动时间控制条,选择需要进行异常检测的时间段。
-
在页面右侧单击 预测 ,对未来进行预测。
-
创建推理机器学习模型
训练航班延误预测模型
本操作通过回归算法训练一个监督机器学习模型,使用Kibana自带的样例数据Sample flight data,该数据集为虚构的航班数据,通过回归算法根据历史数据训练航班延误时间的模型。预测模型可以为航空公司和旅客提供重要的参考信息,帮助旅客更好地规划行程和航班安排。
下面是Sample flight data数据集中的一条数据信息。
{
"_index": "kibana_sample_data_flights",
"_type": "_doc",
"_id": "7b0aeogBmNQSVxOwslB_",
"_version": 1,
"_score": null,
"_source": {
"FlightNum": "QYX9S3I",
"DestCountry": "CH",
"OriginWeather": "Cloudy",
"OriginCityName": "Chicago",
"AvgTicketPrice": 824.8516378170061,
"DistanceMiles": 4442.909325899777,
"FlightDelay": false,
"DestWeather": "Thunder & Lightning",
"Dest": "Zurich Airport",
"FlightDelayType": "No Delay",
"OriginCountry": "US",
"dayOfWeek": 4,
"DistanceKilometers": 7150.1694661808515,
"timestamp": "2023-06-02T07:28:15",
"DestLocation": {
"lat": "47.464699",
"lon": "8.54917"
"DestAirportID": "ZRH",
"Carrier": "Logstash Airways",
"Cancelled": false,
"FlightTimeMin": 420.59820389299125,
"Origin": "Chicago O'Hare International Airport",
"OriginLocation": {
"lat": "41.97859955",
"lon": "-87.90480042"
"DestRegion": "CH-ZH",
"OriginAirportID": "ORD",
"OriginRegion": "US-IL",
"DestCityName": "Zurich",
"FlightTimeHour": 7.009970064883188,
"FlightDelayMin": 0
}-
单击Kibana页面左上角的
 图标,选择
Kibana
>
Machine Learning
。
图标,选择
Kibana
>
Machine Learning
。
-
在左侧菜单栏,单击 。
-
在 数据帧分析作业 页面,单击 创建作业 。
-
选择 kibana_sample_data_flights 索引。
-
在 创建作业 的 配置 区域,配置作业基本参数。
-
选中 回归 模型。
-
因变量选择 FlightDelayMin ,因变量即要预测的目标变量。
-
在已包括字段中,取消选中Cancelled、FlightDelay和FlightDelayType字段。
Cancelled、FlightDelay和FlightDelayType字段对预测航班延误时间没有影响,排除多余字段可避免模型受到不必要的影响,提升预测准确性。
-
拖动圆点,调整训练百分比。
您可以根据业务实际情况,调整参加训练的数据量百分比,本文设置训练百分比为90%。
说明如果数据量比较大,还需要考虑训练的时间问题,训练时间会随着数据量的增加而增加。数据量比较大时建议选择较小的比例进行训练,例如50%或者更低的比例,然后不断地进行矫正,直到得到合适的正确率。
-
-
单击 继续 ,配置 其他选项 。
-
设置 功能重要性值 为5。计算5个对于预测结果重要的特征,以便我们了解哪些特征对于预测结果的贡献最大,有助于进行特征选择和模型优化。
-
设置 预测字段名称 为FlightDelayMin_prediction。指定要预测的目标变量的名称。
-
取消选中 使用估计的模型内存限制 ,设置 模型内存限制 为500MB。指定机器学习模型可以使用的内存上限。如果数据集比较大,模型较为复杂,可能会消耗大量内存,如果超出了限制,可能会导致模型训练失败或者性能下降,因此需要根据数据集的大小和模型的复杂度来设置适当的内存上限。
-
设置 最大线程数 为1。用于指定训练模型的最大线程数,如果设置的线程数过多,可能会导致内存不足或者系统崩溃 。
-
单击 继续 ,设置作业ID为flightdelaymin_job。
-
单击 继续 ,自动对模型进行验证。
-
验证通过后,单击 继续 。
-
在 创建 区域,单击 创建 ,创建任务。
生成任务需要时间,具体耗时由训练的数据量大小决定。
-
-
任务创建完毕后,单击 查看结果 ,查看分析作业的结果。
在 模型评估 区域,查看模型的可靠性。
-
泛化误差:衡量模型在新数据上表现的能力,反映了模型的泛化能力。泛化误差越小,表示模型具有更好的泛化能力,能够更准确地对未知数据进行预测。
-
训练误差:指模型在训练数据集上的表现能力,反映了模型在学习过程中所做的误差。训练误差越小,表示模型在训练数据集上的表现越好。
-
评估指标说明:
-
均方误差:评估回归模型性能的重要指标,数值越小表示模型的预测结果越精确。通过计算真实值与回归模型预测值之间的差值的平均平方和获得。
-
R平方:评估回归模型性能的重要指标,数值越接近1表示模型的拟合程度越好。一般认为超过0.8的模型拟合优度比较高。
-
均方根对数误差:数值越小,表示模型的预测效果越好。通过对预测值和真实值取对数后计算误差平方和的平均值获得。
说明比较多个回归模型时,需要同时考虑均方误差和R平方,以找到最佳平衡模型或适合特定数据集的模型。
-
均方误差为0或R平方值为1通常是不可能的,因为模型的预测结果受到多种因素的影响,而这些因素无法全部考虑到并完全消除误差。
-
均方根对数误差为NaN表示模型预测的结果或真实结果存在非正数或零的情况。
更多详细信息请参见 回归评估 。
-
-
使用航班延误预测模型
通过Kibana中的推理处理器使用上面训练的航班延误预测模型。
-
单击Kibana页面左上角的
图标,选择
Management
>
开发工具
。
-
在Kibana 控制台 中,执行以下命令查看并记录model_id值。
GET _ml/inference/flightdelaymin_job*?human=true此命令表示查询名为flightdelaymin_job的所有推理分析结果,并将结果以人类可读的格式进行输出。命令中flightdelaymin_job为 创建回归推理模型中定义的作业ID 。
-
基于上面创建的回归推理模型,创建一个基于推理处理器的pipeline管道。
说明将代码中的model_id值替换为您获取到的model_id值。
PUT _ingest/pipeline/flight_flightDelayMin_predict "description": "Predict the number of minutes of delay for each flight", "processors": [ "inference": { "model_id": "flightDelayMin_job-168609891****", "inference_config": { "regression": {} "field_map": {}, "tag": "flightDelayMin_prediction" } -
使用kibana_sample_data_flights索引中的数据,以航班延误时间FlightDelayMin为目标变量,进行数据分析和预测。
POST _ingest/pipeline/flight_flightDelayMin_predict/_simulate "docs": [ "_source": { "FlightNum": "EDGSV3T", "DestCountry": "CN", "OriginWeather": "Damaging Wind", "OriginCityName": "Durban", "AvgTicketPrice": 1065.7037805199147, "DistanceMiles": 7273.460817641552, "FlightDelay": true, "DestWeather": "Rain", "Dest": "Shanghai Pudong International Airport", "FlightDelayType": "Carrier Delay", "OriginCountry": "ZA", "dayOfWeek": 5, "DistanceKilometers": 11705.500526106527, "timestamp": "2023-06-03T09:34:00", "DestLocation": { "lat": "31.14340019", "lon": "121.8050003" "DestAirportID": "PVG", "Carrier": "Kibana Airlines", "Cancelled": false, "FlightTimeMin": 881.1071804361806, "Origin": "King Shaka International Airport", "OriginLocation": { "lat": "-29.61444444", "lon": "31.11972222" "DestRegion": "SE-BD", "OriginAirportID": "DUR", "OriginRegion": "SE-BD", "DestCityName": "Shanghai", "FlightTimeHour": 14.685119673936343, "FlightDelayMin": 45 }得到的结果,如图所示。
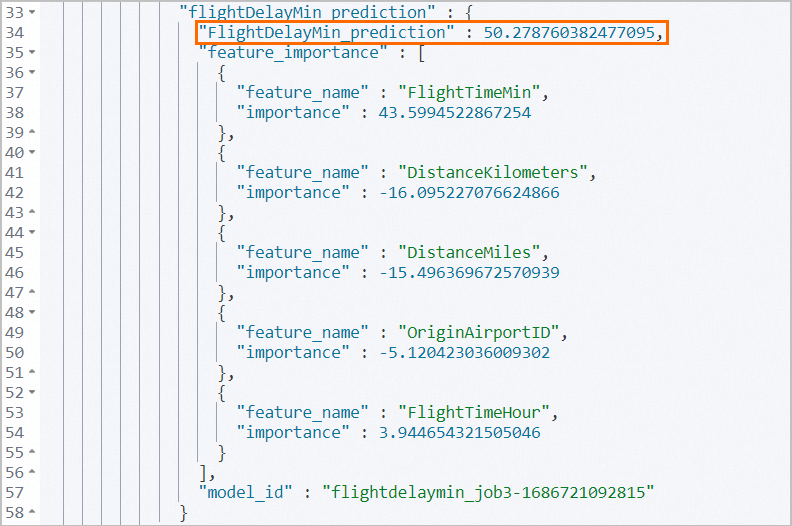
实际的航班延误时间FlightDelayMin为45min,预测得到的航班延误时间FlightDelayMin_prediction为50.28min,与实际相差不大。
feature_importance里显示了对估算航班延误时间贡献最大的5个影响因素:FlightTimeMin,DistanceKilometers,DistanceMiles,OriginAirportID和FlightTimeHour。您可以通过调整5个影响因素的值来调整模型预测结果,从而更为精确地估计未来每个航班的延误时间。