


根据数据字典自动生成sql建表语句

大数据开发工程师 | 一个金融转行的SQL Boy
在工作中,每次用EXCEL做完数仓建模,生成数据字典以后,还要一个个编写hive的建表语句,如果表比较少还行,但是如果是成百上千张表,手动建表就比较繁琐了。
之前有学过python,很久没用了,所以顺便就捡起来,写了一个自动化通过EXCEL生成sql建表语句的python脚本,请教了一个项目上以前做爬虫的同事,所以比较快的完成了。这里做一个记录分享。
EXCEL样式
为了方便演示,这里展示的是一个demo版的数据字典,内容比较简单,一个目录页,两个表单详情页
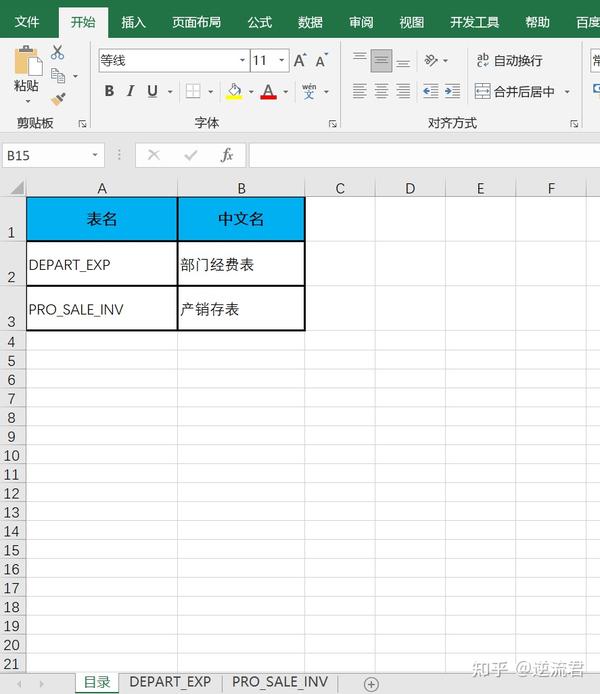

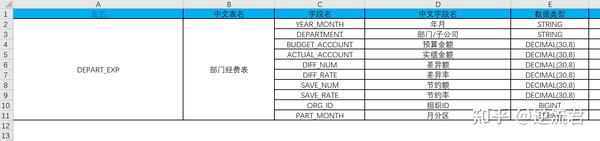
每个表单里,第一列第二行是表名,第二列第二行是表的中文备注,第三列是字段名,第四列是字段备注,第五列是数据类型,字段的最后一行如果有分区字段,则说明是分区表。

Python代码
下面直接上代码和详细的备注,复制到代码编辑器中更方便观看。
import xlrd #操作Excel的库
#Excel文件路径
file_name = input('请输入Excel文件路径:')
jb_name = input("输入脚本存放路径:")
#读取Excel文件
excel = xlrd.open_workbook(r'%s'% file_name) #输入绝对路径要加^,同目录下则直接输入,r识别转义符/,%s引用%后面的变量
#开始遍历sheet
for i in range(excel.nsheets): #.nsheets获取excel的sheet数量,确定循环次数
#跳过第一个sheet目录
if i != 0:
#构建建表sql头,第一个%s定义表中文备注,第二个%s定义表名
sql = '''\n\n--%s
CREATE TABLE IF NOT EXISTSC %s
sheet = excel.sheet_by_index(i) #.sheet_by_index()通过索引查找,定位到此时遍历的是哪一张sheet
table_name = sheet.row_values(1)[0] #表名等于sheet的第2行,第1列(顺序是从0开始),.row_values定位到行
table_comment = sheet.row_values(1)[1] #表备注等于sheet的第2行,第2列
sql = sql % (table_comment,table_name) #给sql头变量填充值
row_num = sheet.nrows #获取当前表单总行数
if ('PART_' in sheet.row_values(row_num-1)[2] or 'part_' in sheet.row_values(row_num-1)[2]) and '分区' in sheet.row_values(row_num-1)[3]:
row_num = row_num -1 #有分区就过滤最后一行,算出总行数
for m in range(row_num): #确定需要循环的字段行数
if m > 0: # 过滤掉第一行表头
col_name = sheet.row_values(m)[2] #获取第m行,第3列的值作为字段名称
col_type = sheet.row_values(m)[4] #获取第m行,第5列的值作为字段的数据类型
col_comment = sheet.row_values(m)[3] #获取第m行,第4列的值作为字段备注
if m == row_num -1:#当遍历到最后一行时
col_sql = " %s %s COMMENT '%s'\n)\n" % (col_name,col_type,col_comment) #最后一行结尾带括号并换行
else:
col_sql = " %s %s COMMENT '%s',\n" % (col_name,col_type,col_comment) #每一行结尾带,号并换行
sql = sql + col_sql
sql = sql + " COMMENT '%s'\n" % table_comment #给表添加备注
#判断该表是否分区,分区表分区格式为parquet,非分区表为textfile
if ('PART_' in sheet.row_values(sheet.nrows - 1)[2] or 'part_' in sheet.row_values(sheet.nrows - 1)[2]) and '分区' in sheet.row_values(sheet.nrows - 1)[3]:
sql = sql + " PARTITIONED BY (%s STRING COMMENT '%s')\n" % (sheet.row_values(sheet.nrows - 1)[2], sheet.row_values(sheet.nrows - 1)[3])
sql = sql + " ROW FORMAT DELIMITED FIELDS TERMINATED BY '\\036'\n"
sql = sql + ' STORED AS PARQUET;\n\n'