


文本比较算法——最小编辑距离、图的最短路以及最长公共子序列

文本比较算法是一个经常会被使用到的算法。当然,大部分时间都是作为版本控制系统的命令来使用,比如 git diff。无论是提交前的差异性检查,还是多人合作时的分支合并,git diff 都是很合适且很有用的命令。相对而言,工程上需要实现一个文本比较算法比较少见。于个人而言,似乎只有在 14 年左右,有一个项目需要造轮子实现一个文本比较算法的变种。不过该算法更常出现的场景,是在面试环节,毕竟很少有人不使用 git diff / svn diff / shell diff,那么希望面试者曾今思考过这些命令是如何实现的也就是一件自然而然的事情(当然,真没用过就算了)。
本文对文本比较算法进行基本介绍, 引入了一个基本模型对文本比较算法进行讨论,并将结合 git diff 的具体多个算法实现来介绍实践中文本比较算法。 目录结构如下
- 文本比较算法和最小编辑距离
- 最小编辑距离的一个模型,图的最短路和最长公共子序列
- git diff 的多种算法选择和底层实现介绍
- 结语
1 文本比较算法和最小编辑距离
文本比较,如果用比较直观简单的话来解释,对于两个文本 A 和 B ,我们希望能找出他们之间的不同,并用某种方法来衡量不同的程度。这里的某种方法,一般是指编辑距离 D ——可以使用 D 个动作施加在 A 上,将其转换为 B ,动作包括插入 (insert)和 删除 (delete)(注 1),比如
文本 A 文本 B
|------------------------------------|------------------------------------
1|#include <iostream> |#include <iostream>
2|using namespace std; |using namespace std;
3| |void hello() {
4|int main() { | cout << "hello world" << endl;
5| cout << "hello world" << endl; |}
6|} |
7| |int main() {
8|------------------------------------| hello();
9| |}
| |------------------------------------文本 A 有 7 行组成,文本 B 有 9 行组成,使用插入和删除可以有很多方式将 A 转换成 B 。比如,删除 A 的原本 7 行,然后插入 B 中的 9 行来完成转换,编辑距离为 7 + 9 = 16
编辑序列, - 代表删除 / + 代表插入(注意空行)
------------------------------------------
-|#include <iostream>
-|using namespace std;
-|int main() {
-| cout << "hello world" << endl;
+|#include <iostream>
+|using namespace std;
+|void hello() {
+| cout << "hello world" << endl;
+|int main() {
+| hello();
------------------------------------------ 事实上,任意文本都可以使用这种全删除 + 全插入的方式来完成转换。但是缺点显而易见,这种方式并没有体现出文本 A 和 文本 B 之间的差异,即使他们是一样的。我们更倾向于使用这样的动作序列
编辑序列, - 代表删除 / + 代表插入(注意空行)
------------------------------------------
|#include <iostream>
|using namespace std;
-|int main() {
+|void hello() {
| cout << "hello world" << endl;
+|int main() {
+| hello();
------------------------------------------ 编辑距离为 6,这也是 A 转换到 B 的最小编辑距离。如上所见,在本文中文本的最小单元的行,即所有编辑动作全部是以行为单元。实际上,也有以词,甚至以字母作为最小编辑单元。无论基本单元是什么,他们的基本原理都是一致(注 2)。一般我们说文本比较算法,是希望找出文本之间的最小差异, 也就是在基本单元的基础上求本文之间的最小编辑距离和对应的具体动作序列
2 最小编辑距离的一个模型,图的最短路和最长公共子序列
本节引入一个模型来表示文本 A 和 B 的最小编辑距离。我们先使用一些符号来表示文本 A 和 B 的所有行,以及编辑动作序列,这里我们继续这个例子
文本 A 文本 B
|------------------------------------|------------------------------------
1|#include <iostream> |#include <iostream>
2|using namespace std; |using namespace std;
3| |void hello() {
4|int main() { | cout << "hello world" << endl;
5| cout << "hello world" << endl; |}
6|} |
7| |int main() {
8|------------------------------------| hello();
9| |}
| |------------------------------------文本 A 一共有 N = 7 行,令 A = a_1a_2a_3...a_N ,其中元素 a_i 代表 A 第 i 行;同样文本 B 有 M = 9 行,令 B = b_1b_2b_3...b_M ,其中元素 b_j 代表 B 第 j 行。
对于编辑动作序列, a_x \space D 表示删除 A 中的 a_x ,其中 x\in[1, N] ; a_x\space I\space b_ib_{i+1}..b_j 在 A 中的 a_x 后插入 B 的 b_ib_{i+1}...b_{j} ,其中 x \in[0, N] , i < j \space and \space i \geq 1 \space and \space j \leq M (当 x 等于 0 时,代表在文本 A 第 1 行开始插入)。这里的所有序号,代表任何动作未发生前,文本原本的行位置。如第一节那样,其中一个满足最小编辑距离的动作序列是(未必唯一,注 3)
编辑序列, - 代表删除 / + 代表插入(注意空行,序号分别对应在 A / B 行号
------------------------------------------
A|B|--------------------------------------
1|1| |#include <iostream>
2|2| |using namespace std;
3| |-|
4| |-|int main() {
|3|+|void hello() {
5|4| cout << "hello world" << endl;
6|5|}
|7|+|int main() {
|8|+| hello();
|9|+|}
------------------------------------------ 使用上述标记表示,即
\{ a_3 D、a_4D、a_4Ib_3、a_7Ib_7b_8b_9 \}
其编辑距离为 6,2 次删除,2 次插入(其中一次同时插入 3 行 )。同时,既然编辑动作中,无论 a 还是 b 的下标都是最初的序号,那么这些编辑动作发生的顺序无关紧要,将其作为一个集合。再将文本和编辑动作符号化后,接下来再来看一个被为『编辑图』的『二维网格』,或者说一个『有向无环图』
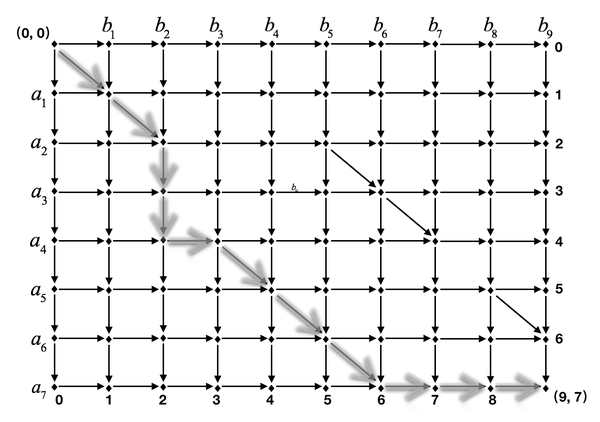

这个『二维网格』的横坐标 x \in [0, M] ,其中 M 是文本 B 的长度;纵坐标 y \in[0, N] ,其中 N 是文本 A 的长度。对于所有 (x, y) ,若没超过边界,都有一条垂直有向边 (x, y) \rightarrow (x, y + 1) 和一条水平有向边 (x, y) \rightarrow(x + 1, y) ;若对于文本 A 和 B 存在 a_i = b_j ,则存在一条对角有向边 (i - 1, j - 1) \rightarrow (i, j) 。
在上图中,画出了一条从 (0, 0) -> (M, N) 的路径,它对应着一个满足最小编辑距离的动作序列。其垂直段 (i, j) \rightarrow (i, j + 1) 对应 a_{j+1}D ;其中连续水平段 (i, j)\rightarrow(i + k, j) , k \geq 1 对应 a_jIb_ib_{i+1}...b_{i + k} 。事实上,我们可以证明从 (0, 0) \rightarrow (M, N) 的所有路径和所有编辑动作序列是一一对应的。
1) 转换 (0, 0) \rightarrow (M, N) 的某一路径 S 到某一个编辑动作序列
设 (x_1, y_1) (x_2, y_2) ...(x_L, y_L) 是其顺序途径的对角有向边结束点的排列,比如上例中这个顺序排列为 (1, 1)(2, 2)(4, 5)(5, 6)(6, 7) 。由图中对边的定义,只有 a_i = b_j ,才存在一条对角有向边 (i - 1, j - 1) \rightarrow (i, j) , 对于文本 B 和 A 有 b_{x_1} = a_{y_1} \space and\space b_{x_2} = a_{y_2} ... and \space b_{x_L} = a_{y_L} ;且除了对角有向边,图中只有向右和向下的有向边,很容易发现对于 (x_1, y_1) (x_2, y_2) ...(x_l, y_l) ,满足 x_1 < x_2 < ... < x_l 且 y_1 < y_2 < ... < y_l ,则 (x_1, y_1) (x_2, y_2) ...(x_l, y_l) 对应着文本 B 和 A 的公共子序列 (注 4),比如上列中这个公共子序列就是 b_1b_2b_4b_5b_6 = a_1a_2a_5a_6a_7 。
A|B|--------------------------------------
1|1| |#include <iostream>
2|2| |using namespace std;
5|4| cout << "hello world" << endl;
6|5|}
------------------------------------------ 对 (0, 0) \rightarrow(M, N) 的路径 S ,其在 y 的增长只能由对角有向边和向下有向边贡献,则路径 S 中必然存在边 (x_c, y) \rightarrow (x_c, y+1) ,其中 y \notin \{y_1y_2...y_l\} 且 y \in [1, N] ,对应编辑动作中的 a_yD ,其会删除文本 A 中的一些行然后得到公共子序列 a_{y_1}a_{y_2}...a_{y_L} ;同样,路径 S 在 x 的增长只能由对角有向边和向右有向边贡献,则路径 S 中必然存在边 (x, y_c) \rightarrow (x + 1, y_c) ,其中 x \notin \{x_1x_2...x_l\} 且 x \in [1, M] ,对应编辑动作中的 a_{y_c}Ib_x (同样的 a_{y_c} 可以进行合并,比如 a_{y_c}Ib_{x_i} 、 a_{y_c}Ib_{x_{i + 1}} 可以合并为 a_{y_c}Ib_{x_i}b_{x_{i + 1}} ),其会在合适的位置在文本 A 中插入一些来自文本 B 中行。这里可以反向思考将其当成删除动作,其会删除文本 B 中的一些行得到公共子序列 b_{x_1}b_{x_2}...b_{x_L} ,这个操作反转也就是将 a_{y_1}a_{y_2}...a_{y_L} = b_{x_1}b_{x_2}...b_{x_L} 扩展成 B 。最后转换出的动作序列的编辑距离 D = N + M - 2L
2) 转换某一个编辑动作序列 到 (0, 0) \rightarrow (M, N) 的某一路径 S
将编辑动作集合中的动作 a_yD 和 a_yIb_xb_{x+1}...b_k 按照 a_y 下标从小到大排序,然后依次转换,设当前坐标为 (x_{cur}, y_{cur}) ,初始 x_{cur} = 0 y_{cur} = 0 。如果当前编辑动作是 a_yD ,则沿着对角边前进 y - y_{cur} - 1 步,再沿向下边前进一步,设当前坐标为 (x_{cur} + y - y_{cur} - 1, y) ;如果当前编辑动作是 a_yIb_xb_{x+1}...b_{x + k} ,则沿着对角边前进 x - x_{cur} 步,再沿向右边前进 k 步,设当前坐标为 (x + k, y_{cur} + x - x_{cur}) ;在遍历转换所有编辑动作后,如果 x_{cur} \ne M 或 y_{cur} \ne N ,则继续沿对角线前进直到 (M, N) ,此时可得到一条 (0, 0) \rightarrow (M, N) 的路径,且其对角边的长度为 L = \frac{N + M - D}{2} 。转换过程中的正确性参考 1)很容易得到,略
从上面 1)2)中不仅可以得知文本 A 和 B 的编辑动作序列可以一一对应到相应编辑图上从 (0, 0) \rightarrow (M, N) 的路径,且可以知道编辑距离 D = N + M - 2L 。比较直观的,可以通过以下 3 种方式来求解最小编辑距离问题
- 直接穷举所有 (0, 0) \rightarrow (M, N) 可能路径,找出 D_{min} = min(M + N - 2L) ,渐进时间为指数级
- M 和 N 已知,找到 L_{max} = max(L) 即可得 D_{min} = M + N - 2L_{max} , L 为文本 A 和 B 对应行的公共子序列长度。可将问题转化为寻找最长公共子序列问题,该问题在『算法导论』的『15.4 最长公共子序列』有一个朴素的动态规划解法,时间复杂度为 O(MN)
- 从 (0, 0) \rightarrow (M, N) 的路径长度为 S = N + M - L \Rightarrow D = 2S - M - N 。可以使用图的单源最短路算法来求解该问题,如 Dijkstra’s algorithm,在此问题中其渐进时间可以认为是 O(MN) 。更多图的单源最短路算法参考 『算法导论』的 『第24章 单源最短路径』
不过在实践中,以上 3 种方法都不会被使用,更常见的算法被称为 Myers Diff Algorithm,它也是 git diff 的默认文本比较算法
3 git diff 的多种算法选择和底层实现介绍
如果看下关于 git diff 的文档说明,会发现 git diff 使用的文本比较算法有 4 个选项
--diff-algorithm={patience|minimal|histogram|myers}- myers。即 Myers Diff Algorithm,其是在第 2 节中的『编辑图』上衍生出的算法,时间复杂度为 O((M + N)D) ,其中 D 是最小编辑距离。对于差异相对较小的文本表现非常良好,且只需要 O(M + N) 的空间,它是 git diff 的默认实现。这有两个链接,一个是关于算法的论文, 一个是关于算法的 Python 实现和计算在线演示
- minimal。它也是 Myers Diff Algorithm,只是 git diff 在使用默认或者 myers 选项时,出于效率的考虑,做了一些简化。比如当有连续多个对角边时,并满足一个关于迭代次数的函数时,就不继续搜索了,这样虽然找到不一定满足最小编辑距离的文本差异,但是表现也足够良好。minimal 选项关闭所有的简化,严格按照 Myers Diff Algorithm 搜索最小编辑距离。这里有一个链接,是 git 的源码,minial 的具体实现通过一个参数的 0 / 1 值来开关。当然也有其他 3 种的,都在 xdiff 目录下,就是基本无注释
- patience。这个算法的输出可读性更高,其不像 Myers Diff Algorithm 采用『编辑图』模型,而是直接求最长公共子序列。但这个算法一般找不到最小编辑距离,因为其在匹配最长公共子序列的时候,先过滤了一些输入文本,只考虑在文本 A 和 B 同时出现且各自只出现一次的行,对于一个代码文件,空行或者大括号大概率出现多次从而被直接过滤。下面是一个例子,对比 myers 和 patience 的区别
文本 A 文本 B
|------------------------------------|------------------------------------
1|.foo1 { |.bar {
2| margin: 0; | margin: 0;
3|} |}
4| |
5|.bar { |.foo1 {
6| margin: 0; | margin: 0;
7|} | color: green;
8|------------------------------------|}
|------------------------------------
//git diff --diff-algorithm=myers 输出
-.foo1 {
+.bar {
margin: 0;
-.bar {
+.foo1 {
margin: 0;
+ color: green;
//git diff --diff-algorithm=patience 输出
-.foo1 {
- margin: 0;
.bar {
margin: 0;
+.foo1 {
+ margin: 0;
+ color: green;
+}- 虽然 patience 选项没有得到最小编辑距离,但其可读性更强,结果一目了然。另外值得一提的是,patience diff 在过滤输入文本后,求解最长公共子序列并没有使用『算法导论』中描述的算法。而是利用输入文本出现在双方各一次的特性,使用基于 patience sort 排序的贪心算法,时间复杂度是 O(NlogL) ,其中 N 是过滤后的文本单元个数, L 是最长公共子序列长度。这有 4 个链接,一个关于 patience diff 的简述,两个是关于 patience sort 和最长公共子序列的算法描述,一个是 patience diff 的作者关于该算法的一些介绍
- histogram。该算法是在 patience 上进行的改进。比如在 patience 算法,最长子序列匹配只考虑在两个文件各出现一次的基本单元,histogram 适当的放开了这个限制。这个链接是指向 jgit 的,其有很详细关于 histogram 的描述。当然,git 本身源码也有 histogram 实现,就是缺乏注释
4 结语
这篇文章写着写着,越写越多,本来是想把提及的算法和证明过程都详细写出来,后来发现还是直接看论文最靠谱,于是把删了一堆。最后只留了基本模型描述,其是最朴素的想法,很适合作为基础知识。至于 git diff 的底层实现算法,有兴趣仔细研究下,没兴趣大概了解下即可,相关链接有一个在线演示,对理解 myers 算法很有帮助。另外不得不说,patience diff 的实现非常有趣,而且实现起来也比较简单,其内在算法应用还挺广泛的,有兴趣可以多了解下
如有疏漏,欢迎指正
注 1:编辑动作本身可以扩展,比如增加新的动作;或者对不同动作赋予不同权值,编辑距离 D = \Sigma d_i , d_i 是不同动作的权值。一般认为 d_{delete} = d_{insert} = 1
注 2:单元的不同大小,可以简单理解成单元的值集合大小和分割符的不同。比如,如果基本单元是单字母,其取值集合为 \{a, b, c .. z\} ,分隔符为空;如果基本单元是词,其取值集合为所有字母序列,分隔符为空格,如果加上标点,更为复杂;文中的基本单元是行,其分隔符是换行,取值集合是一行上所有可能序列;对于不同的单元大小,算法实现对特定细节有不同实现
注 3:下面动作序列也满足最小编辑距离
编辑序列, - 代表删除 / + 代表插入(注意空行)
------------------------------------------
|#include <iostream>
|using namespace std;
+|void hello() {
+| cout << "hello world" << endl;