

Python(三)提取信息必学——正则表达式

正则表达式并不是Python的一部分。正则表达式是用于处理字符串的强大工具,拥有自己独特的语法以及一个独立的处理引擎,效率上可能不如str自带的方法,但功能十分强大。得益于这一点,在提供了正则表达式的语言里,正则表达式的语法都是一样的,区别只在于不同的编程语言实现支持的语法数量不同;但不用担心,不被支持的语法通常是不常用的部分。
转载自 Python正则表达式实例详解_程序员阿城的博客-CSDN博客_python正则表达式详解
阅读一字符解释、二语法解释、三习题部分即可,需要文字详细解释的请直接进入第四部分正文循序渐进哟。
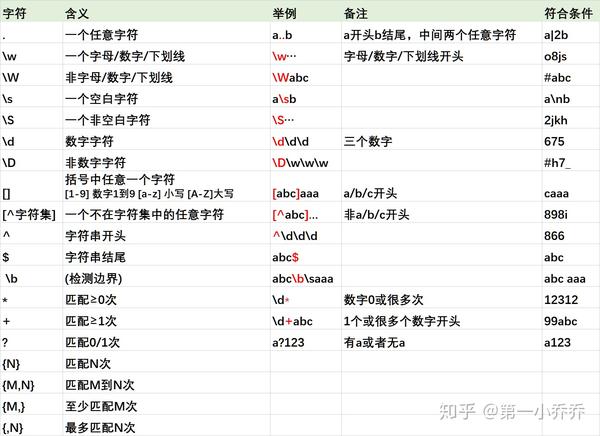
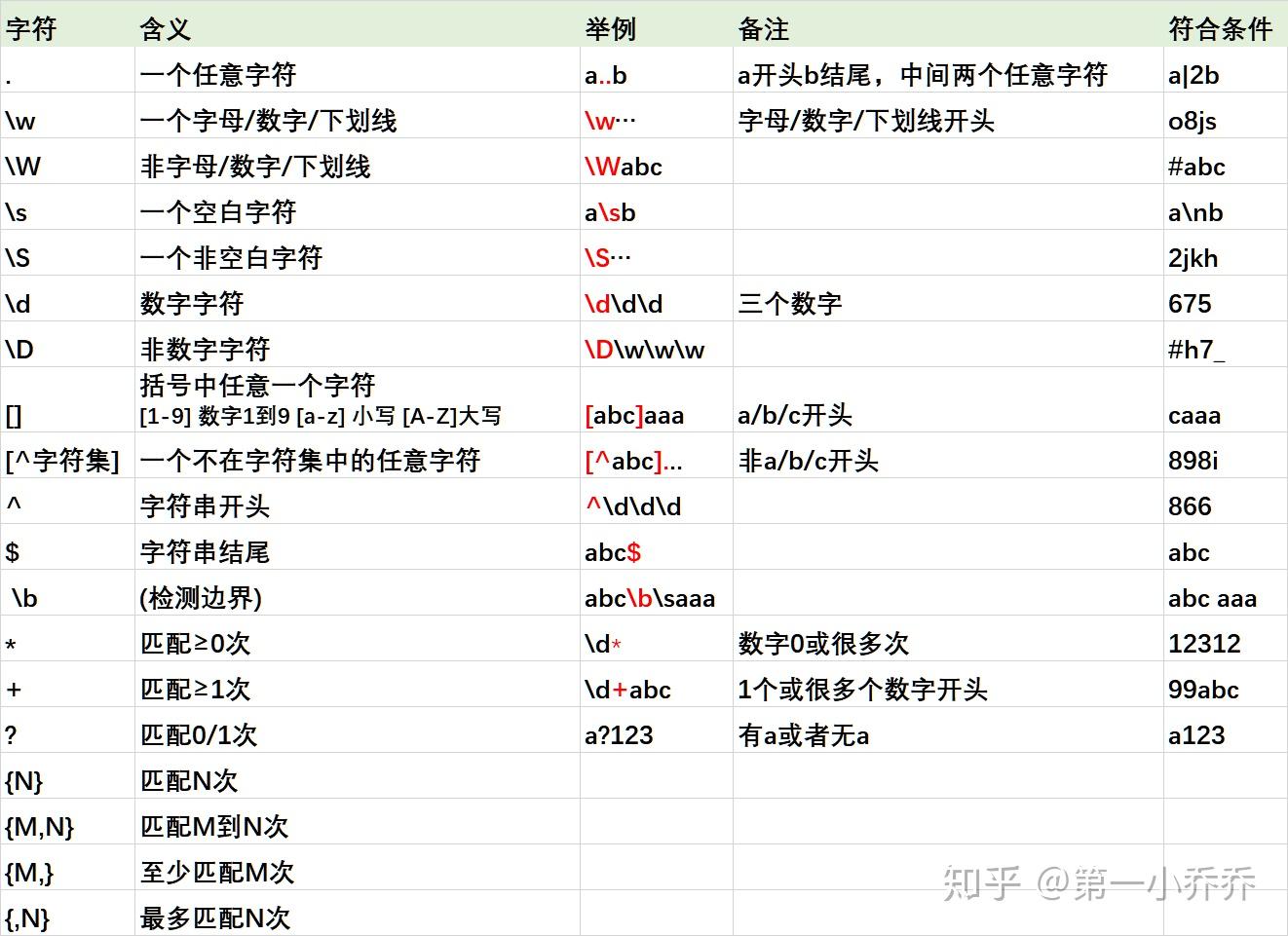
一、字符含义总结如下:
二、语法:
match()和search()都只匹配出一个符合条件的字符串,若想要所有,可以使用re.findall()


三、仔细研读上面的表格后,实战/习题部分:
# 用[]{}判断密码是否符合要求 :密码是由数字和字母组成,并且位数是6-16位
re_str = r'[\da-zA-Z]{6,16}'##用split按-或者空白格分割字段
str1 = 'ahsb1sssa8-jjhd7nhs+90nsjhf3-4hh h7+8kjj-sfav'
print(re.split(r'[-+\s]', str1))结果:['ahsb1sssa8', 'jjhd7nhs', '90nsjhf3', '4hh', 'h7', '8kjj', 'sfav']
#用sub替换符合条件的关键词, 试试马赛克脏话(想起农药不能痛骂队友的愤怒)
str1 = '智 障沙雕,你在干嘛?逼, 后视镜,妈的加扣扣上'
print( re.sub(r'傻\s*叉|逼|沙雕|fuck|妈的|智\s*障', '*', str1))
## 结果:**,你在干嘛?*, 后视镜,*加扣扣上##练练转义
re_str = r'\d{2}\=\d{2}'
print(re.fullmatch(re_str, '12=34'))## findall返回符合表达式的子串
re_str = r'\d+k[a-d]+'
str1 = 'abc34kshd8923kabcshd9lkkk890kaa'
result = re.findall(re_str, str1)
print(result) # ['8923kabc', '890kaa']
## 结果:['8923kabc', '890kaa']四、详细正文-----------
一、正则表达式语法
正则表达式是用匹配或者描述字符串的工具。
用处:
a.判断字符串是否满足某个条件---判断输入的字符串是否是邮箱/手机号码。是否是ip地址
b.提取满足条件的字符串
c.字符串替换
Python中通过re模块中相应的方法来支持正则表达式的匹配、查找和替换等功能
from re import fullmatchfullmatch(正则表达式字符串, 字符串) ---> 判断正则表达式和字符串是否完全匹配
正则表达式字符串: 就是一个字符串,字符串中是正则表达式语法。r'正则表达式'
正则表达式中包含两个部分,一个是正则语法对应的字符,二个是普通字符
1 .(点)(匹配任意字符)
一个.只匹配一个任意字符
# 匹配一个长度是3的字符串,第一个字符是'a', 第二个字符是任意字符,最后一个字符是b
re_str = r'a.b'
result = fullmatch(re_str, 'a|b')
print(result)
# 匹配一个长度是4,第一个字符和最后一个字符分别是a和b,中间两个字符是任意字符的字符串
re_str = r'a..b'
result = fullmatch(re_str, r'a\nb')
print(result)2 \w(匹配字母数字下划线)
一个\w匹配一个字符
# 匹配一个第一个字符是数字字母或者下划线,后面三个字符是任意字符的字符串
re_str = r'\w...'
result = fullmatch(re_str, 'o8js')
print(result)3 \s(匹配任意空白字符)
空白字符: 空格、制表符(\t)、回车(换行\n)等,都输入空白字符
一个\s匹配一个空白字符
# 匹配一个第一个字符是a,第二个字符是空白,最后一个字符b的字符串
re_str = r'a\sb'
result = fullmatch(re_str, 'a\nb')
print(result)4 \d(匹配数字字符)
re_str = r'\d\d\d'
result = fullmatch(re_str, '282')
print(result)5 \b(检测边界)
一个\b不会去匹配一个字符,而是单纯的检测\b出现的位置是否是单词边界
单词边界: 字符串开始和结尾、空格、换行、标点符号等,可以将两个单词隔开的字符都单词边界
re_str = r'\babc'
re_str = r'abc\b\saaa' # 匹配一个字符串前三位是abc,第四位是空白字符,后面是aaa。并且要求c后面是单词边界
result = fullmatch(re_str, 'abc aaa')
print(result)6 ^(检测是否是字符串开头)
re_str = r'^\d\d\d' # 判断一个字符串是否是三个数字开头
result = fullmatch(re_str, '123')
print(result)7 $(检测是否是字符串结尾)
re_str = r'abc$'
result = fullmatch(re_str, 'abc')
print(result)8 \W(匹配非字母、数字下划线)
re_str = r'\Wabc'
result = fullmatch(re_str, '#abc')
print(result)9 \S(匹配非空白字符)
re_str = r'\S...'
result = fullmatch(re_str, '2jkh')
print(result)10 \D(匹配非数字字符)
re_str = r'\D\w\w\w'
result = fullmatch(re_str, '#h7_')
print(result)11 \B(检测是否不是单词边界)
re_str = r'and\BYou'
result = fullmatch(re_str, 'andYou')
print(result)12 [] (匹配中括号中出现的任意一个字符)
一个[]匹配一个字符
[字符集] --> 匹配一个字符,这字符是字符集中的任意一个字符
例如:[abc], [\d+]
[字符1-字符2] --> 匹配一个字符,这个字符是Unicode编码值在字符1到字符2中的任意一个字符;要求字符1的编码值要小于字符2
例如:[1-9] --> 数字1到9 [a-z] --> 小写字母 [A-Z] --> 大写字母
[\u0031-\u0039] --> 数字1到9
[\u4E00-\u9fa5] --> 匹配所有的汉字
注意:-在中括号中,如果放在两个字符之间表示范围。
"""匹配一个字符串第一个字符是a或者b或c,后边三个a"""
re_str = r'[abc]aaa'
result = fullmatch(re_str, 'caaa')
print(result)
re_str = r'[1-4]\d\d\d'
result = fullmatch(re_str, '1989')
print(result)
re_str = r'[\u0031-\u0039][a-z]'
result = fullmatch(re_str, '1h')
print(result)
re_str = r'[\u4E00-\u9fa5][\u4E00-\u9fa5][\u4E00-\u9fa5]'
result = fullmatch(re_str, '就深刻')
print(result)
re_str = r'[91-]'
result = fullmatch(re_str, '-')
print(result)
# 匹配一个字符,是字母数字下划线或者是空白
re_str = r'[\w\s]'
result = fullmatch(re_str, 'u')
print(result)13 [^字符集] (匹配一个不在字符集中的任意字符)
注意:^必须放在中括号中的最前面才有效
"""匹配一个四位的字符串,第一位不是abc中的任意一个,后面三位是任意字符"""
re_str = r'[^abc]...'
re_str = r'[^1-9]...'
result = fullmatch(re_str, '898i')
print(result)二、正则表达式次数相关符号
from re import fullmatch
1. *(匹配0次或者多次)
字符* --> 字符出现0次或者多次
# 匹配0位或者多位的数字字符串
re_str = r'\d*'
print(fullmatch(re_str, '123'))
# 用一个正则表达式来检测一个标识符是否符合要求:数字字母下划线组成,数字不开头(位数至少1位)
re_str = r'[a-zA-Z_]\w*'
print(fullmatch(re_str, 'A'))2. +(匹配一次或者多次)
匹配abc前面有一个或者多个数字的字符串
re_str = r'\d+abc'
print(fullmatch(re_str, '9abc'))3. ?(匹配0次或者1一次)
re_str = r'a?123'
print(fullmatch(re_str, 'a123'))练习:写一个正则表达式,匹配所有的整数(123, -2334, +9...可以匹配的,012, -023,+0122不能匹配)
re_str = r'[-+]?[1-9]\d*'
print(fullmatch(re_str, '1234'))4. {}(指定次数)
{N} --> 匹配N次
{M,N} --> 匹配M到N次
{M,} --> 至少匹配M次
{,N} --> 最多匹配N次
re_str = r'\d{3}'
print(fullmatch(re_str, '123'))
re_str = r'\d{3,}'
print(fullmatch(re_str, '1234'))
re_str = r'\d{,3}'
print(fullmatch(re_str, '23'))
re_str = r'[a-z]{2,5}'
print(fullmatch(re_str, 'aajk'))
# 判断密码是否符合要求:密码是由数字和字母组成,并且位数是6-16位
re_str = r'[\da-zA-Z]{6,16}'三、分之和分组
import re
1. |(分之)
条件1|条件2 --> 先用条件1去匹配,如果匹配成功就匹配成功。如果条件1匹配失败,用条件2去匹配。
注意:如果条件1匹配成功就不会用条件2再去匹配
re_str = r'[a-z]{3}|[A-Z]{3}'
print(re.fullmatch(re_str, 'AHD'))能匹配成功时abc,d和aaa
re_str = r'abc|d|aaa'
print(re.fullmatch(re_str, 'aaa'))'abc'+W/H/Y
re_str = r'abc(W|H|Y)'
print(re.fullmatch(re_str, 'abcY'))2. ()(分组)
a.组合(将括号中的内容作为一个整体进行操作)
b.捕获 -- 使用带括号的正则表达式匹配成功后,只获取括号中的内容
c.重复 -- 在正则表达式中可以通过\数字来重复前面()中匹配到的结果。数字代表前第几个分组
a.组合
匹配一个字符串,以数字字母的组合出现3次
re_str = r'(\d[a-zA-Z]){3}'
print(re.fullmatch(re_str, '2h8h7j'))b.捕获
re_str = r'(\d{3})abc'
print(re.fullmatch(re_str, '773abc'))
print(re.findall(re_str, 'euhasdhf873abcssjsja235abcu-03s834432abcjjsks'))c.重复
re_str = r'([a-z]{3})-(\d{2})\2'
print(re.fullmatch(re_str, 'hsn-2323'))3.转义符号
正则表达式中可以通过在特殊的符号前加\,来让特殊的符号没有意义
. --> 任意字符 . --> 字符.
- --> 匹配一次或者多次 + --> 字符+
注意:在中括号有特殊功能的符号,只代表符号本身
\不管在哪儿都需要转义
-在[]外面没有特殊功能,在[]中要表示-本身,就不要放在两个字符之间
()需要转义
re_str = r'\d{2}\.\d{2}'
print(re.fullmatch(re_str, '12=34'))
re_str = r'\d\+\d'
print(re.fullmatch(re_str, '3+7'))
re_str = r'\(\\'
print(re.fullmatch(re_str, '(\\'))
re_str = r'(\d{3})\1([a-z]{2})\2\1'
print(re.fullmatch(re_str, '123123bbbb123'))四、re模块中的函数
import re
1. compile
compile(正则表达式字符串) --> 将正则表达式字符串转换成正则表达式对象
re_objct = re.compile(r'\d+')
print(re_objct)
print(re_objct.fullmatch('23738'))2. fullmatch和match
fullmatch(正则表达式字符串, 字符串)
--> 用正则表达式去完全匹配字符串(匹配整个字符串),返回匹配对象(SRE_Match)或者None
match(正则表达式字符串, 字符串)
--> 匹配字符串开头,返回匹配对象或者None
result = re.fullmatch(r'\d([a-zA-Z]+)123', '2hjdh123')
print(result)1.span(group=0) --> 获取匹配成功的区间(左闭右开区间)
print(result.span(0))
print(result.start(1)) # 获取匹配到的开始下标
print(result.end(1)) # 获取匹配到的结束下标后的下标
2.group(group = 0) --> 获取匹配结果
group()/group(0) --> 获取正则表达式完全匹配的结果
group(index>0) --> 获取正则表达式中第group个分组匹配到的结果
print('0:',result.group())
print('1:',result.group(1))3.string --> 获取被匹配的原字符串
print(result.string)
result = re.match(r'\d([a-zA-Z]+)123', '2hjdh123ABC')
print('match:',result)3.search
search(正则表达式, 字符串)
--> 查找字符串中满足正则表达式的第一个字符串。返回值是匹配对象或者None
result = re.search(r'(\d)[a-zA-Z]+', 'uhsh2hdje+984nf')
print(result.group(0))
print(result.group(1))
print(result.string)练习:使用search匹配出一个字符串中所有的数字字符串'abc34jshd8923jkshd9lkkk890k' --> 34,8923,9,890
re_str = r'\d+'
str1 = 'abc34jshd8923jkshd9lkkk890k'
result = re.search(re_str, str1)
while result:
print(result)
str1 = str1[result.end():]
result = re.search(re_str, str1)4.findall
findall(正则表达式, 字符串) --> 获取字符串中满足正则表达式的所有的子串,返回一个列表
注意:如果正在表达式中有分组,取值的时候只取分组中匹配到的结果;
如果有多个分组,会将每个分组匹配到的结果作为一个元祖的元素
re_str = r'(\d+)k([a-d]+)'
str1 = 'abc34kshd8923kabcshd9lkkk890kaa'
result = re.findall(re_str, str1)
print(result) # [('8923', 'abc'), ('890', 'aa')]
re_str = r'(\d+)k[a-d]+'
str1 = 'abc34kshd8923kabcshd9lkkk890kaa'
result = re.findall(re_str, str1)
print(result) # ['8923', '890']
re_str = r'\d+k[a-d]+'
str1 = 'abc34kshd8923kabcshd9lkkk890kaa'
result = re.findall(re_str, str1)
print(result) # ['8923kabc', '890kaa']5.finditer
finditer(正则表达式, 字符串)
--> 查找所有满足正则条件的子串,返回值是迭代器,迭代器中的元素是匹配对象
re_str = r'\d+'
str1 = 'abc34kshd8923kabcshd9lkkk890kaa'
result = re.finditer(re_str, str1)
print(result)
for item in result:
print(item)6. split
split(正则表达式,字符串) --> 将字符串按照满足正则表达式条件的子串进行分割
"""
str1 = 'ahsb1sssa8-jjhd7nhs+90nsjhf3-4hhh7+8kjj-'
result = re.split(r'[-+]', str1)
print(result)
7.sub
sub(正则表达式,repl,字符串) --> 将字符串中满足正则表达式条件的子串替换成repl。返回替换后的字符串
str1 = 'hsj8jskfh98ssjj8hshh'
result = re.sub(r'\d+','*', str1)
print(result)
str1 = '智 障,你在干嘛?逼, 后视镜,妈的加扣扣上'
result = re.sub(r'傻\s*叉|逼|fuck|妈的|智\s*障', '*', str1)
print(result)
with open('./data', 'r', encoding='utf-8') as f:
content = f.read()
# "name": "搞笑精选汇"
result = re.findall(r'"name":"(.+?)"', content)
print(result)作业
1. 写一个正则表达式判断一个字符串是否是ip地址
规则:一个ip地址由4个数字组成,每个数字之间用.连接。每个数字的大小是0-255 例如:255.189.10.37 正确 256.189.89.9 错误
import re
re_str = r'((\d|[1-9]\d|1\d{2}|2[0-4]\d|25[0-5])\.){3}(\d|[1-9]\d|1\d{2}|2[0-4]\d|25[0-5])'
result = re.fullmatch(re_str,'255.183.10.37')
print(result)2. 计算一个字符串中所有的数字的和
例如:字符串是:‘hello90abc 78sjh12.5’ 结果是90+78+12.5 = 180.5
str1 = 'hello90abc 78sjh12.5'
result = re.findall(r'[^a-z]+',str1)
print(result)
sum1 = 0
for item in result:
sum1 += float(item)
print(sum1)3. 验证输入的内容只能是汉字
re_str = r'[\u4E00-\u9fa5]+'