


R语言数据分析与可视化(2)-以sofifa数据为例

1.写在前面
1.爬取五大联赛球员数据
2.数据版本为5月的,非最新的
3.只爬取了自己感兴趣的数据部分,获取数据不是最终目的
4.网站官网: http://www. sofifa.com
2.概述
2.1 网站概述
- 静态网站 ,看到的东西基本都能拿下,单纯的静态网页数据爬取是最简单的,没有什么难度;
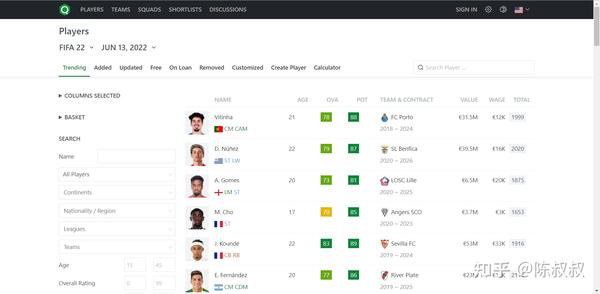
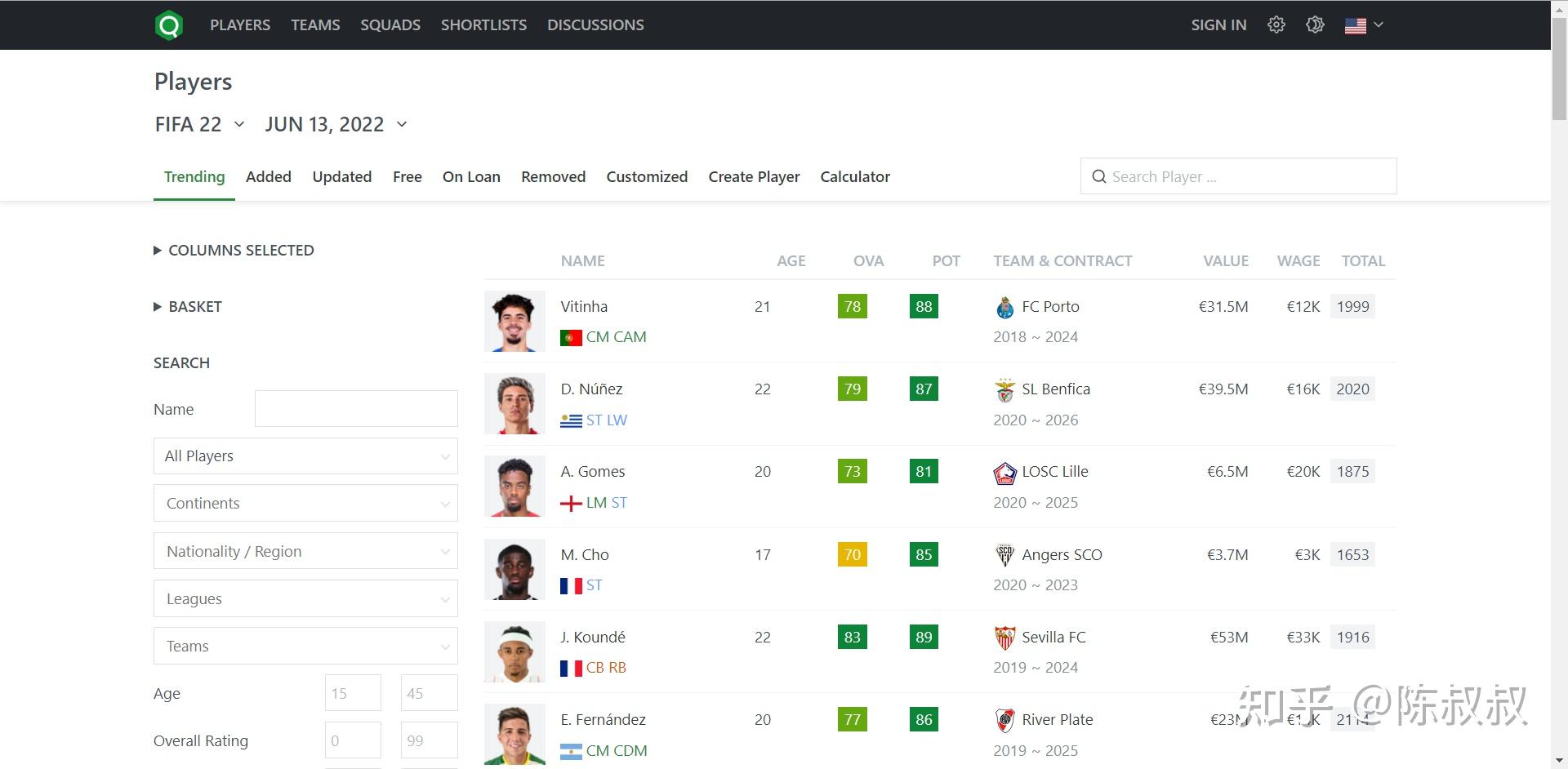
- 网站分球队,球员等板块,获取五大联赛球员数据,在球员板块部分搜索模块中选中五大联赛后获得对应网址,在这些网址下进行;
- 球员信息数据分两部分: 一部分是列表页信息,有球员的基本信息;一部分是详情页信息,通过二级入口进入,有球员的详细信息;本文也会分两大部分来进行,最后通过球员ID这个整合两部分数据到一个数据框中。
2.2 网页简单分析,确定爬取思路
网站分析及网页信息确定 (显示的页面和代码中爬取数据的页面不一样, 代码是5月份写的)
- 首页:
- 五大联赛搜索页:
- 翻页后网址: https:// sofifa.com/players? type=all&lg%5B0%5D=13&lg%5B1%5D=16&lg%5B2%5D=19&lg%5B3%5D=31&lg%5B4%5D=53&offset=60
- 再翻一页: https:// sofifa.com/players? type=all&lg%5B0%5D=13&lg%5B1%5D=16&lg%5B2%5D=19&lg%5B3%5D=31&lg%5B4%5D=53&offset=120
- 列表页url规律 ,offset参数值以60为单位步进,也就是可以理解为每页有60个球员;这样就很清楚了,这个数据不能过大,否则球员数据会有重复的,比如我们预计5大联赛大约3000名球员,那么这个页数应该在49-50页之间;当然,通过最后去重操作也能规避类似问题,但能在确定列表页url时就做到精准,是最高效的
- 详情页信息: 通过列表页各球员信息,可进入球员详情页,详情页网址也有规律,球员ID,姓名,版本等信息。如哈兰德的页面长这样:
开始获取数据,先获取列表页信息
2.3 列表页信息爬取
- 2.3.1 列表页网站下载
# 列表页网址基本信息单元分解 ####
list_url_base <- "https://sofifa.com/players?
type=all&lg%5B%5D=13&lg%5B%5D=16&lg%5B%5D=19&lg%5B%5D=31&lg%5B%5D=53&offset="
i <- 0:49 # 0-49 共50页,累计不超过3000名球员,覆盖了全部五大联赛球员,又没有重复的
list_url_num <- 60*i
# 确定列表页网址信息 ####
list_url <- str_c(list_url_base, list_url_num, sep = "")
# 1.3 下载列表页信息 ####
# 说明:为确保后续爬取速度,将列表页下载到本地(批量下载到本地,后续处理信息全在本地,看似笨拙,但非常方便)
# 既然要下载到本地,本地即需要有对应的文件及名字
list_url_name <- str_c("list", i, ".html", sep = "")
# 使用purrr包中walk2 函数进行循环批量下载
walk2( list_url, list_url_name,
~download.file(.x, .y, mode = "wb", quiet = FALSE))
- 2.3.1 爬取列表页信息
列表页已经下载到本地后,用rvest包来爬取相关想要的信息,主要动作分三步
- 构建函数
- 批量爬取
- 数据存档
# 获取列表页信息 #####
# 构建一个函数,来获取列表页基础信息,然后用循环函数获取每个列表页信息,形成数据框;
# 列表页信息包括一个基础信息列表,以及未直接单独显示的姓名,ID, 详情页link,球员国籍等信息;
# 1. 构建获取列表页信息函数 ####
get_list_info <- function(url){
# 每页一张表,用html_table 函数直接获取,稍做处理即可
list_baseinfo = read_html(url, encoding = 'UTF-8') %>%
html_table(fill = TRUE) %>%
as.data.frame() %>% # 转为数据框
.[,-1] # 第一列为无效信息,删除
# 在上表中,球员姓名和位置信息在一个字段中,需单独获取球员姓名信息
name = read_html(url, encoding = 'UTF-8') %>%
html_nodes("tbody.list tr td.col-name a div.ellipsis") %>%
html_text()
# 球员详情页网址链接信息
link = read_html(url, encoding = 'UTF-8') %>%
html_nodes(xpath="/html/body/div[1]/div/div[2]/div/table/tbody/tr/td[2]/a[1]") %>%
html_attr("href") %>%
str_c("https://sofifa.com", ., sep = "")
# 获取球员ID信息,作为每行观测唯一标识字段
ID =link %>% str_extract_all(
'(?<=player\\/)([0-9]{5,6})(?=\\/[a-z])') %>% unlist()
# ID 信息获取其实可以在外面(非函数内)执行;
# 使用正则表达式,提取球员ID 数字;
# ([0-9]{5,6}) 可以换成\\d+ 更合理,兼容任意数量数字的情形
# 国籍信息
country = read_html(url, encoding = "UTF-8") %>%
html_nodes(xpath="/html/body/div[1]/div/div[2]/div/table/tbody/tr/td[2]/img") %>%
html_attr("title")
# 把上述几个零散信息合并成一个dataframe
list_info <- data.frame(ID= ID,
name= name,
country= country,
link= link)
# 将上述datafram与baseinfo那个dataframe合并成一个list info dataframe,即为我们想要的输出。
list_df <- cbind(list_baseinfo, list_info)
# 增加一个进度显示
pb$tick()$print()
# 返回list info dataframe
return(list_df )
# 2 获取列表页基础信息 #####
# 进度条设置
pb <- dplyr::progress_estimated(length(list_url_name))
# 使用map函数进行批量获取,因为网址信息已在本地,获取速度非常快。这个函数比写for循环高效快捷
list_df <- map_df(list_url_name, ~get_list_info(.x),pb= pb)
# 2.3 将信息保存到本地 #####
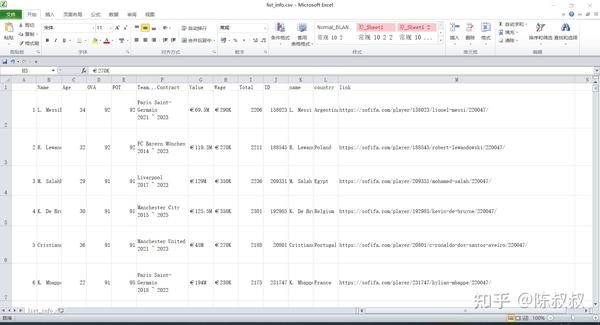
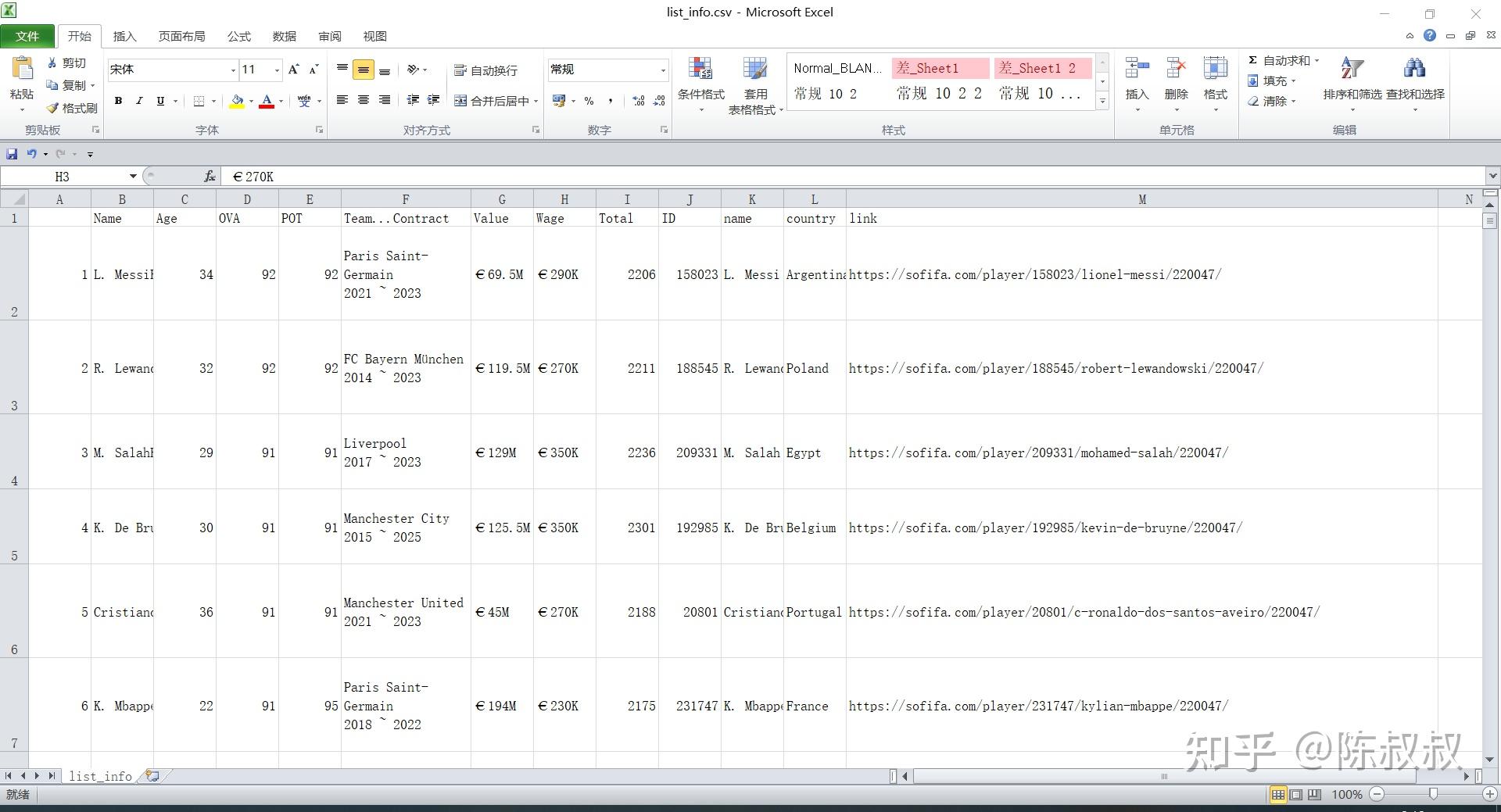
write.csv(list_df, 'list_info.csv')
至此,列表页信息基本获取完毕,当然有部分信息,如球员头像链接等没有在此获取。
整个过程非常丝滑,效率很高。
当然,现在获取的信息还是一个raw material,需要在后续的是数据分析清理环节来进行清洗处理。
- 2.3.2 爬取详情页信息
完成列表页信息获取后,对球员详情页信息进行获取。
根据列表页信息中的详情页网址链接,获取球员详情信息,这个步骤很漫长;主要步骤也分三步:
- 把详情页下载到本地,几千个网页,占本地空间,但后续处理全在本地,很方便;
- 编写数据爬取函数,把详情页各版块信息分类别爬取;
- 爬取数据,简单整理后,数据保存到本地。
主要工作量在第二步。
第一步,下载网页信息到本地
# 球员详情页网址
detail_url <- list_df$link
# 球员详情页网址名称,以球员ID命名
detail_url_name <- str_c(list_df$ID, ".html")
# 球员详情页网址下载
walk2(detail_url, detail_url_name,
~download.file(.x, .y, mode = "wb", quiet = FALSE))- 第二步,详情页信息获取函数
# 详情页信息获取
# 详情页信息较多,先对信息进行分区块大类处理,然后再通过函数进行批量操作
# 详情页信息总体分五大部分:
## 1 基础信息:球员的基础信息,部分内容与列表页信息重复;
## 2 球员的profile信息
## 3 球员的俱乐部和国家队属性信息
## 4 球员的属性信息
## 5 球员其他信息(这部分信息作为备选,如最佳位置,以及其他比较详实的各位置得分信息等)
# 创建详情页信息获取函数
至此,爬取球员详情数据函数构建完成,下来就是处理批量获取,然后做些简单的数据补充了
- 第三步,爬取详情页数据,简单补充整理后,保存到本地
在这个环节,网页下载到本地的优势就体现出来,先前进行过N次在线爬取,基本不能正常完成,使用了各种方式,均不能有效规避网络连接中断,反爬措施等带来的干扰。
# 爬取球员详情数据
get_detail_info <- function(url){
# 1.1base info get
baseinfo<- '/html/body/div[2]/div/div[2]/div[1]'
base_info <- read_html(url, encoding = 'UTF-8') %>%
html_nodes(xpath= baseinfo) %>%
html_text() %>%
str_split_fixed("\n", n = 6) %>%
as.data.frame() %>%
select(2,3,5)
names(base_info) <- c("name","personalinfo","playerinfo")
df_baseinfo<- base_info %>%
separate_wider_regex(personalinfo, c(position = ".+(?=\\d{2,}y\\.o\\.)",
age = "\\d+(?=y\\.o\\.)",
".+",
birthday = "(?<=\\().+?(?=\\))",
".\\s",
height_cm = "\\d+(?=cm)",
".+\\s",
weight_kg = "\\d+(?=kg)",
".+")) %>%
separate_wider_regex(playerinfo, c(overall = "\\d+",
".+",
potential = "(?<=rating)\\d+",
".+",
value = "(?<=Potential).+?(?=Value)",
".+",
wage = "(?<=Value).+?(?=Wage)",
".+"))
## 原代码失效。
# 基础信息部分内容与列表页内容基本一致,补充上述代码,记录使用seperate_wider_regex()函数进行数据清洗的实践。
# 2.1 profile 部分nodes 字段
profile <- '/html/body/div[2]/div/div[2]/div[2]/div'
profile_info <- '/html/body/div[2]/div/div[2]/div[2]/div/ul/li'
profile_label <- '/html/body/div[2]/div/div[2]/div[2]/div/ul/li/label'
# 2.2 profile 部分信息字段
p_name <- c("Preferred_Foot","Weak_food","Skill_Moves","International_Reputation","Work_Rate",
"Body_Type","Real_Face","Release_Clause","ID")
#信息标签
profilelabel <- read_html(url, encoding = 'UTF-8') %>%
html_nodes(xpath= profile_label) %>%
html_text()
# 2.3 信息内容
profileinfo <- read_html(url, encoding = 'UTF-8') %>%
html_nodes(xpath= profile_info) %>%
html_text() %>%
str_remove(profilelabel) %>%
str_trim(side = 'right') # 去除空白部分内容
# 2.4 异常情况处置
# 对于租借球员,无解约金信息,需控制,调整顺序如下
newinfo <- c(profileinfo[1:7], "NA", profileinfo[8])
# if else 语句简单实现当为租借球员时信息内容
p_info <- if(length(profileinfo)== 9) {
profileinfo} else {newinfo}
# 2.5 信息写进dataframe 数据框
# p_name 为数据框p_df 的列名--变量
# p_info 为数据框p_df 的行数据--观测
names(p_df) <- p_name
p_df[1,]<- p_info
##########################################################################
# 3.详情页俱乐部和国家队信息获取
# 信息较为复杂,有球员无国家队信息,有部分球员国家队和俱乐部位置放反,
# 所以需要考虑不同情况,确保输出信息一次做正确,准确。
# 3.1 node 字段设置
club <- '/html/body/div[2]/div/div[2]/div[4]/div'
club_name <- '/html/body/div[2]/div/div[2]/div[4]/div/h5'
c_n_name <- "/html/body/div[2]/div/div[2]/div/div/h5/a"
club_repu <- '/html/body/div[2]/div/div[2]/div[4]/div/ul/li[1]/span'
club_label<- '/html/body/div[2]/div/div[2]/div[4]/div/ul/li/label'
club_info<- '/html/body/div[2]/div/div[2]/div[4]/div/ul/li'
nteam_info<- '/html/body/div[2]/div/div[2]/div[5]/div/ul/li'
nation_info<- '/html/body/div[2]/div/div[2]/div[5]/div/ul/li'
nteam <- '/html/body/div[2]/div/div[2]/div[5]/div'
nteam_name <- '/html/body/div[2]/div/div[2]/div[5]/div/h5'
nteam_repu <- '/html/body/div[2]/div/div[2]/div[5]/div/ul/li[1]/span'
nteam_label<- '/html/body/div[2]/div/div[2]/div[5]/div/ul/li/label'
nteam_info<- '/html/body/div[2]/div/div[2]/div[5]/div/ul/li'
nteam_position<- '/html/body/div[2]/div/div[2]/div[5]/div/ul/li/span'
nteam_kitnum<- '/html/body/div[2]/div/div[2]/div[5]/div/ul/li[3]/text()'
# 3.2 俱乐部及国家队名称
## 俱乐部及国家队名称, 用以求length 判断
cnname <- read_html(url, encoding = 'UTF-8') %>%
html_nodes(xpath= c_n_name) %>%
html_text
## 3.3 俱乐部
## 俱乐部名称,用于放入最终info 清单
clubname <- read_html(url, encoding = 'UTF-8') %>%
html_nodes(xpath= c_n_name) %>%
html_text %>%
## 俱乐部信息总表,用于求length 判断
cluball <- read_html(url, encoding = 'UTF-8') %>%
html_nodes(xpath= club_info) %>%
html_text
## 俱乐部声誉信息,用于总表俱乐部数据
clubrepu <- read_html(url, encoding = 'UTF-8') %>%
html_nodes(xpath= club_info) %>%
html_text %>%
## 俱乐部信息标签,用于总表列名
clublabel <- read_html(url, encoding = 'UTF-8') %>%
html_nodes(xpath= club_label) %>%
html_text()
## 俱乐部信息内容,用于总表俱乐部数据
clubinfo <- read_html(url, encoding = 'UTF-8') %>%
html_nodes(xpath= club_info) %>%
html_text() %>%
.[-1]%>%
str_remove_all(clublabel) %>%
unlist()
# 3.4 国家队
## 国家队名称,用于放入最终info 清单
nationname <- read_html(url, encoding = 'UTF-8') %>%
html_nodes(xpath= c_n_name) %>%
html_text %>%
### 判断无国家队信息时的处置方式
nationname <- if(length(nationname)==0) {NA}
else {nationname}
## 国家队信息总表,用于求length 判断
nationall <- read_html(url, encoding = 'UTF-8') %>%
html_nodes(xpath= nation_info) %>%
html_text
nationall <- if(length(nationall )==0) {NA}
else {nationall}
## 国家队声誉信息,用于国家队总表数据
nationrepu <- nationall[1]
nationrepu <- if(length(nationrepu )==0) {NA}
else {nationrepu}
## 国家队信息标签,用于总表列名
nationlabel <- read_html(url, encoding = 'UTF-8') %>%
html_nodes(xpath= nteam_label) %>%
html_text()
# if(length(nationlabel)==0) {nationlabel <- c(NA, NA)}
# else{nationlabel <- nationlabel}
nationlabel <- as.character(
if(length(nationlabel)==0) {c(NA, NA)}
else{nationlabel})
## 国家队信息内容,用于总表俱乐部数据
nationinfo <- read_html(url, encoding = 'UTF-8') %>%
html_nodes(xpath= nteam_info) %>%
html_text() %>%
.[-1]
nationinfo <- as.character(
if(length(nationinfo)==0) {c(NA, NA)}
else{nationinfo%>%
str_remove_all(as.character(nationlabel)%>%
unlist())})
## 原代码存在bug,进行修改,避免nationinfo为空但nationlabel被赋值(NA,NA)后无法执行remove的bug.
baselabel <- c("club_name",
'national_teamname',
'club_repu',
'national_teamrepu',
'national_position',
'national_num')
##不同情况处置, 共有四种情况
# 1. 一切正常,增加一个'租借自字段',共11 个字段
label1 <- c(baselabel,clublabel,'On_loan_from')
# 2. 俱乐部信息栏,正常状态,
## 但球员为租借,第9个字段为入队时间要手工加入,
label2 <- c(baselabel,clublabel[1:2],
'join_time',
clublabel[4:3])
# 3. 国家队与俱乐部信息倒换,但非租借情形,
## 用国家队label 信息填充,增加一个'租借自字段',共11 个字段
label3 <- c(baselabel,
nationlabel,
'On_loan_from')
# 4. 国家队与俱乐部信息倒换,且存在租借情形,
## 用国家队label信息填充,第9个字段为入队时间要手工加入
label4 <- c(baselabel,nationlabel[1:2],
'join_time',
nationlabel[4:3])
# 3.6 数据内容设置部分 info
## 也有四种情形
# 1. 一切正常,增加租借自信息NA
info1 <-c(clubname,
nationname,
clubrepu,
nationrepu,
nationinfo,
clubinfo,
# 2. 一切正常,但球员为租借,
info2 <-c(clubname,
nationname,
clubrepu,
nationrepu,
nationinfo,
clubinfo[1:2],
clubinfo[4:3])
# 3. 国家队信息与俱乐部信息调换,但非租借情形
info3 <-c(nationname,
clubname,
nationrepu,
clubrepu,
clubinfo,
nationinfo,
# 4. 国家队信息与俱乐部信息调换,且为租借情形
info4 <-c(nationname,
clubname,
nationrepu,
clubrepu,
clubinfo,
nationinfo[1:2],
nationinfo[4:3])
# 3.7 编写逻辑判断,匹配上述四种情形,并形成data.frame
# 1.各种情形下数据字段设置
cn_label <- if(length(clubinfo)==4) {
if(clublabel[3]=='Joined') {label1} else{label2}}
else{if(nationlabel[3]=='Joined') {label3}
else{label4}}
# 2. 各种情形下数据内容信息设置
cn_info <- if(length(clubinfo)==4) {
if(clublabel[3]=='Joined') {info1} else{info2}}
else{ if(nationlabel[3]=='Joined') {info3}
else{info4}}
# 3. 数据信息写入数据框
names(cn_df) <- cn_label
cn_df[1,]<- cn_info
################################################################
# 4.详情页球员属性信息获取
# 4.1 球员属性部分 nodes 字段设置
# 总共7 个大项34 小项属性,即球员属性字段,或者说变量
# 另加2项非数值型变量,特征(triat)及特长(spec)
attr_label <- '/html/body/div[3]/div/div[2]/div/div/h5'
attr_label_son <- '/html/body/div[3]/div/div[2]/div/div/ul/li/span'
attr_info_son <- '/html/body/div[3]/div/div[2]/div/div/ul/li/span[1]'
trait_info <- '/html/body/div[3]/div/div[2]/div[10]/div'
spec <- '/html/body/div[2]/div/div[2]/div[3]/div'
spec_label <- '/html/body/div[2]/div/div[2]/div[3]/div/h5'
spec_info <- '/html/body/div[2]/div/div[2]/div[3]/div/ul'
# 4.2 球员属性信息获取
attrinfo <- read_html(url, encoding = 'UTF-8') %>%
html_nodes(xpath= attr_info_son) %>%
html_text() %>%
.[1:34]
attrlabel <- read_html(url, encoding = 'UTF-8') %>%
html_nodes(xpath= attr_label_son) %>%
html_text() %>%
str_remove_all('(\\+[0-9]{1,2})|(\\-[0-9]{1,2})') %>%
str_extract_all('(\\D{1,})') %>% unlist()
# 抓取到的数据有球员属性值上升或下降的标注信息
# 以‘+3’‘-5’样式存在,需去除
traitlabel <- read_html(url, encoding = 'UTF-8') %>%
html_nodes(xpath= attr_label) %>%
html_text() %>%
traitinfo <- read_html(url, encoding = 'UTF-8') %>%
html_nodes(xpath= trait_info) %>%
html_text() %>%
str_remove(traitlabel)%>%
ifelse(length(.)==0,NA, .)
# 要考虑抓取内容为空的情形,确保各观测间长度相同
specinfo <- read_html(url, encoding = 'UTF-8') %>%
html_nodes(xpath= spec_info) %>%
html_text()
# 4.3 确定这部分数据框变量及观测值内容和顺序
a_info <- c(attrinfo,traitinfo,specinfo)
a_label <- c(attrlabel[1:34],"traits","Specialities")
########################################################################################
# 增加处理进度
# pb$tick()$print()
# 4.4 信息写入数据框
a_df [1,] <- a_info
names(a_df) <- a_label
#####################################################################################
# 5 将上述四部分信息整合成一个数据框
df <- cbind(df_baseinfo, p_df, cn_df,a_df)
return(df)
# 状态进度监控
pb <- dplyr::progress_estimated(length(detail_url_name))
# 初始化数据框
cn_df <- data.frame(matrix(ncol = 11,nrow = 0))
p_df <- data.frame(matrix(ncol = 9,nrow = 0))
a_df <-data.frame(matrix(ncol = 36,nrow = 0))
# 获取详情页数据
detail_info <- map_df(detail_url_name, ~get_detail_info(.x), pb=pb)
# 至此,2983名球员72项详细信息就下载完成,这些信息现在还比较粗糙,需要后续步骤进行清洗。
接下来,对数据进行查漏补缺和合并整理,保存到本地,即完成球员详情数据整理。
# 合并列表页和详情页表格
final_df <- merge(list_df,detail_info,by = "ID")
# 补充最佳位置信息及其他 发现未将这部分信息纳入前面的函数中,进行一次补充操作
get_bestposition <- function(url){
bp_df = read_html(url, encoding = "UTF-8") %>%
html_nodes(xpath=
"/html/body/div[3]/div/div[1]/ul/li[1]/span") %>%
html_text() %>%
return()
bestposition <- map_chr(detail_url_name,~get_bestposition(.x))
# 最佳位置信息装入总表中
final_df$bestposition <- bestposition
# 总表转为tibble 格式
final_df <- final_df %>% as_tibble()
# 对总表列名进行初步处理,去除空格和“.”,空格用“_”代替。
names <- names(final_df) %>%
str_replace_all(" ", "_") %>%
str_replace_all("\\.", "")
# 前期爬取的俱乐部信息 增补到总表中
team_info <- team_list[,c(8,9)] # 选择俱乐部名称和联赛名称两个字段
final_df$club_name<- final_df$club_name %>%
str_trim(side = 'right') # 去除字符串中空白部分
team_info$club_name<- team_info$club_name %>%
str_trim(side = 'right') # 去除字符串中空白部分