

尝试使用Chinese-LLaMA-Alpaca-知识库篇

上周写完了 量化篇 ,基本上从模型精调到部署使用,我们已经讲完了如何利用现有的Chinese-LLaMA-Alpaca库训练自己的领域模型,实施部署,最终整合到业务系统里的整体流程。综合使用文章中的脚本和工具,完全可以实现模型自由。
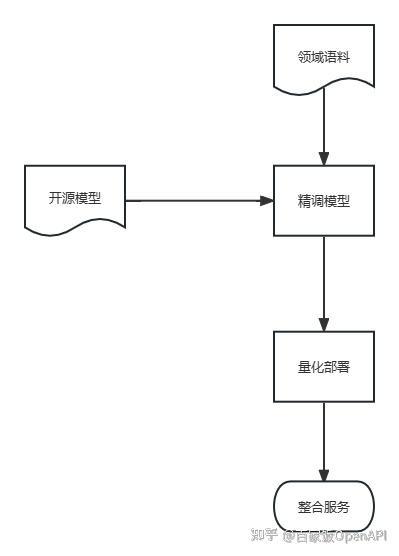
但是就像ChatGPT要引入插件机制一样,我们可以和AI聊天,但是单纯的聊天无法满足所有的需求,聊天中,AI也可能出现虚构信息,幻觉回答等问题,这时如果辅助一个知识库就可以很好的解决这个问题。也就是将整体框架补全成这样:
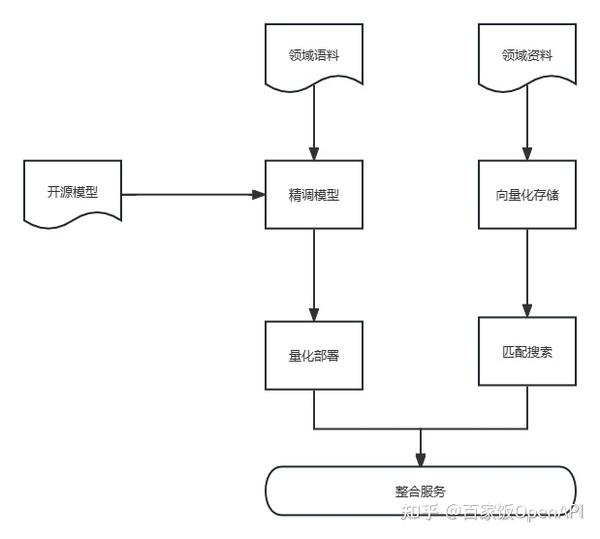
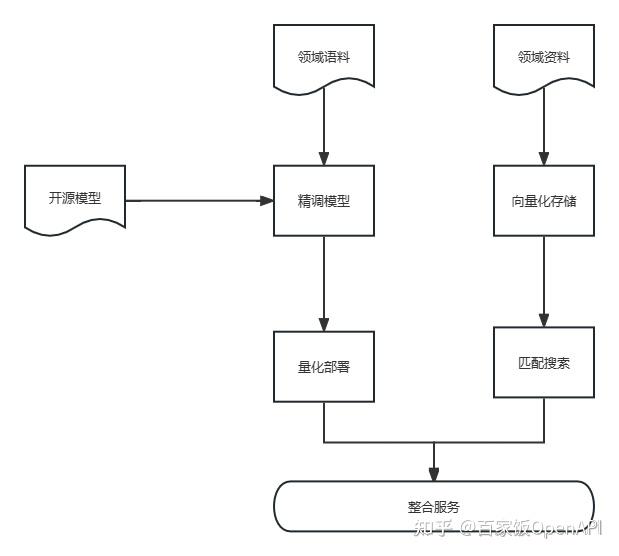
对于更为详细的领域资料,他们可能无法整合到对话里,我们需要把他们做成资料,资料进行向量化,存储到向量数据库中,再通过向量数据库的匹配搜索功能,和AI提供的对话结果进行整合,实现真正的领域服务。
今天要介绍我们使用Milvus向量数据库建设知识库的一些工作,仅介绍搭建和基础的使用,详细的优化工作目前我们还没开始。
几点介绍
什么是Milvus Vector DB?
Milvus 是一个用于向量(Vector)存储和检索的特殊数据库,由国内的创业公司 Zilliz 开发。
什么是向量数据库?
我们在用图片搜索图片,或者语音搜索语音的时候,在数据库中存储和对比的并不是图片和语音片段,而是通过DL等算法提取出来的“特征”,一般是256/512个float数组,可以用数学中的向量来表示。
向量数据库就是用来存储,检索,分析向量的数据库。
为什么做对话服务需要向量数据库?
这段是我自己的理解了,AI生成模型,目前看还是有很多的问题,我们可以看到人提到ChatGPT“撒谎”的问题,愿意在于生成模型只能做语言层面的思考,生成结果是思考得到的结论,而结论是否确实和现实情况一致,还需要进一步的和资料进行验证,这种验证就是靠在向量数据库中查找相似内容,并完成最佳匹配进行的。
Milvus安装
参考 主页面 教程,下载docker-compose.yml文件,使用docker-compose启动即可在本机部署一个单机版本。单机版本内存要求较高,需要16G以上的内存,加之其单独无法服务,还需要额外的服务,因此对机器性能要求还是比较高的。
需要注意的是,官方指引是使用下面的命令启动,如果你启动之后,发现无法访问通信端口,请尝试去掉最后的“-d”让他前台执行,以便发现错误。
sudo docker-compose up -d我们遇到的问题
我们在执行中出现了因为系统http代理造成milvus和依赖的etcd服务无法通信的问题,后来解决办法是修改了docker配置文件中的http proxy选项才得以顺利完成。
Milvus使用
创建数据库
如果正常完成和数据库的连接,我们就可以开始规划我们的数据库了,和普通数据库一样,我们需要规划表结构,
创建可以参考官方文档:
官方文档的一些没有说明的问题,这里我补充一下:
1)String对应的是Varchar,需要指定一个最大长度。
2)每个表对应有一个主键,用PrimaryKey:true参数指定(GO,其他语言略有不同),如果该主键没有指定值的话,可以另行指定AutoID:true来指定自动生成ID
3)这是所有支持的字段类型:
// Match schema definition
const (
// FieldTypeNone zero value place holder
FieldTypeNone FieldType = 0 // zero value place holder
// FieldTypeBool field type boolean
FieldTypeBool FieldType = 1
// FieldTypeInt8 field type int8
FieldTypeInt8 FieldType = 2
// FieldTypeInt16 field type int16
FieldTypeInt16 FieldType = 3
// FieldTypeInt32 field type int32
FieldTypeInt32 FieldType = 4
// FieldTypeInt64 field type int64
FieldTypeInt64 FieldType = 5
// FieldTypeFloat field type float
FieldTypeFloat FieldType = 10
// FieldTypeDouble field type double
FieldTypeDouble FieldType = 11
// FieldTypeString field type string
FieldTypeString FieldType = 20
// FieldTypeVarChar field type varchar
FieldTypeVarChar FieldType = 21 // variable-length strings with a specified maximum length
// FieldTypeBinaryVector field type binary vector
FieldTypeBinaryVector FieldType = 100
// FieldTypeFloatVector field type float vector
FieldTypeFloatVector FieldType = 101
注意,如果要用向量相似搜索,对应的向量字段要用最下面两类
4)每个表至多有一个向量类型
5)Vector字段需要有一个dim参数,例子中是2,实际使用中看你用哪个embedding,我们用llama的embedding,维度是4096。(embedding是什么?下一章讲)
6)有一点需要提醒的是,vector字段是处理后的向量数据,无法表征原始数据,如果一个字段既用来搜索,又需要显示,需要创建一个vector字段和一个原始字段。
7)记得创建一个索引,索引是和vector字段配套的相似度计算方法,不同的索引适合不同的数据类型和不同的搜索需求,这里搜到一篇比较文章:
我们暂时是用的基础的IvfFlat,深入的性能比较还没完成,有做过的小伙伴记得说一声,和大语言模型配套哪个合适。
添加和搜索数据
添加数据没有特别可以讲的,参考官方文档即可: Insert Entities Milvus documentation ,只是其中vector字段的构建,我们放到最后一起讲。
搜索讲一下他支持的搜索方式,前面我们讲到字段分为两类,一类是原始数据,一个是vector向量数据,对应的搜索方式有query和search
query对应原始数据搜索,这个类比普通数据库的搜索,具体条件通过一个表达式传递,官方文档见 这里 ,和一般sql仍有差距。
search对应向量搜索,会根据匹配算法搜索最相似的数据。每个返回结果有一个相似度打分,分数越小,表示越相近。
返回结果这块官方文档讲的少,是个比较大的槽点。
返回结果首先是一个数组,但是数组的内容并不是一条数据,而是按列存储的多条返回结果,目前暂不清楚第一级的数组到底表示什么意思,我们的单机版第一级数量一直是1,分享一下我们处理结果的代码
//返回的结果数组一直都是1长度
fmt.Println("searchResult:", len(searchResult))
for _, sr := range searchResult {
briefs = make([]Brief, sr.ResultCount)
//每个result包含多个Scores,对应这个结果里多个具体结果的分数
fmt.Println(sr.Scores)
//每个resuult又包含多个Fields,对应搜索时要求返回的每一个字段
for _, field := range sr.Fields {
//需要按名称对应到结果的每一个字段里
switch field.Name() {
case "command_name":
for k, v := range field.FieldData().GetScalars().GetStringData().Data {