


Elasticsearch冷数据存储应用分布式存储(CurveFS)


Elasticsearch使用CurveFS的收益
CurveFS提供的成本优势
为了高可靠,ES如果使用本地盘的话一般会使用两副本,也就是说存储1PB数据需要2PB的物理空间。但是如果使用CurveFS,由于CurveFS的后端可以对接S3,所以可以利用对象存储提供的EC能力,既保证了可靠性,又可以减少副本数量,从而达到了降低成本的目的。
以网易对象存储这边当前主流的EC 20+4使用为例,该使用方式就相当于是1.2副本。所以如果以ES需要1PB使用空间为例,那么使用CurveFS+1.2副本对象存储只需要1.2PB空间, 相比本地盘2副本可以节省800TB左右的容量,成本优化效果非常显著 。
CurveFS提供的性能优势
以下文将要介绍的使用场景为例,对比ES原来使用S3插件做snapshot转存储的方式,由于每次操作的时候索引需要进行restore操作,以100G的日志索引为例,另外会有传输时间,如果restore的恢复速度为100M,那么也要300多秒。实际情况是在一个大量写入的集群, 这样的操作可能要几个小时 。
而使用CurveFS后的新模式下基本上只要对freeze的索引进行unfreeze,让对应节点的ES将对应的meta数据载入内存就可以执行索引, 大概耗时仅需30S左右 ,相比直接用S3存储冷数据有数量级的下降。
CurveFS提供的容量优势
本地盘的容量是有限的,而CurveFS的空间容量可以 在线无限扩展 。同时减少了本地存储的维护代价。
CurveFS提供的易运维优势
ES使用本地盘以及使用S3插件方式,当需要扩容或者节点异常恢复时,需要增加人力运维成本。CurveFS实现之初的一个目标就是易运维,所以CurveFS可以实现 数条命令的快速部署 以及故障自愈能力。
另外如果ES使用CurveFS,就实现了存算分离,进一步释放了ES使用者的运维负担。
ES使用背景
在生产环境有大量的场景会用到ES做文档、日志存储后端,因为ES优秀的全文检索能力在很多时候可以大大的简化相关系统设计的复杂度。比较常见的为日志存储,链路追踪,甚至是监控指标等场景都可以用ES来做。
网易ES选用CurveFS的原因
网易ES底层存储的使用经历了从本地盘到minio,再从minio到CurveFS这一过程。
本地盘到minio
为了符合国内的法律约束,线上系统需要按照要求存储6个月到1年不等的系统日志,主要是国内等保、金融合规等场景。按照内部管理的服务器数量,单纯syslog的日志存储空间每天就需要1T,按照当前手头有的5台12盘位4T硬盘的服务器,最多只能存储200多天的日子,无法满足日志存储1年的需求。
针对ES使用本地盘无法满足存储容量需求这一情况,网易ES底层存储之前单独引入过基于S3的存储方案来降低存储空间的消耗。如下图,ES配合minio做数据存储空间的压缩。举例来说100G的日志,到了ES里面因为可靠性需求,需要双副本,会使用200G的空间。ES针对索引分片时间,定期性转存储到minio仓库。


minio到CurveFS
这个方案从一定程度上缓解了存储空间的资源问题,但是实际使用的时候还会感觉非常不便利。
- 运维成本。ES节点升级的时候需要额外卸载安装S3插件,有一定的运维成本。
- 性能瓶颈。自己私有化搭建的Minio随着bucket里面数据量的增长,数据存储和抽取都会成为一个很大的问题
- 稳定性问题。在内部搭建的Minio集群在做数据restore的时候,因为文件处理性能等因素,经常遇到访问超时等场景,所以一直在关注是否有相关的系统可以提供更好的读写稳定性。
由于S3协议经过多年的演化,已经成了对象存储的工业标准。很多人都有想过用fuse的方式使用S3的存储能力。事实上基于S3的文件系统有很多款,例如开源的s3fs-fuse、ossfs、RioFS、CurveFS等。
在通过实际调研以及大量的测试后,基于 Curve的性能(尤其是元数据方面,CurveFS是基于RAFT一致性协议自研的元数据引擎,与其他没有元数据引擎的S3文件系统(比如s3fs,ossfs)相比具备巨大的性能优势),易运维,稳定性,Curve可以同时提供块存储以及文件存储能力等能力以及Curve活跃的开源氛围,最终选用了CurveFS。
CurveFS结合ES的实践
CurveFS是什么
CurveFS是一个基于 Fuse实现的兼容POSIX 接口的分布式文件系统,架构如下图所示:
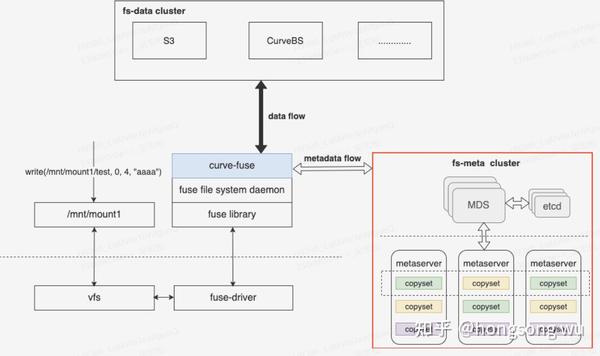
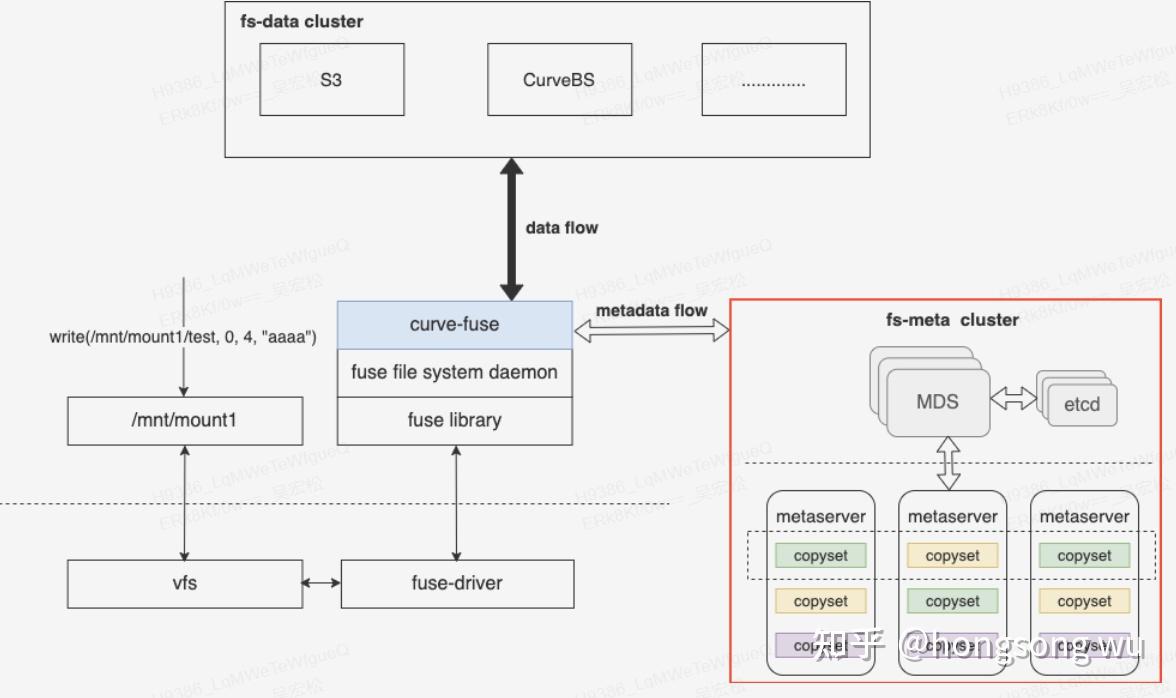
CurveFS由三个部分组成:
- 客户端curve-fuse,和元数据集群交互处理文件元数据增删改查请求,和数据集群交互处理文件数据的增删改查请求。
- 元数据集群metaserver cluster,用于接收和处理元数据(inode和dentry)的增删改查请求。metaserver cluster的架构和CurveBS类似,具有高可靠、高可用、高可扩的特点:MDS用于管理集群拓扑结构,资源调度。metaserver是数据节点,一个metaserver对应管理一个物理磁盘。CurveFS使用Raft保证元数据的可靠性和可用性,Raft复制组的基本单元是copyset。一个metaserver上包含多个copyset复制组。
- 数据集群data cluster,用于接收和处理文件数据的增删改查。data cluster目前支持两存储类型:支持S3接口的对象存储以及CurveBS(开发中)。
Curve除了既能支持文件存储,也能支持块存储之外, 从上述架构图我们还能看出Curve的一个重要优势 :就是CurveFS后端既可以支持S3,也可以支持Curve块存储。这样的特点可以使得用户可以选择性地把性能要求高的系统的数据存储在Curve块存储后端,而对成本要求较高的系统可以把数据存储在S3后端。
CurveFS结合ES的实践
- ES使用CurveFS
CurveFS定位于网易运维的云原生系统,所以其部署是简单快速的,通过CurveAdm工具,只需要几条命令边便可以部署起CurveFS的环境,具体部署见 https:// github.com/opencurve/cu rveadm/wiki/curvefs-cluster-deployment ; https:// github.com/opencurve/cu rveadm/wiki/curvefs-client-deployment , 部署后效果如下图:


在日志存储场景,改造是完全基于历史的服务器做的在线改造。下图是线上日志的一个存储架构示例,node0到node5可以认为是热存储节点,机器为12 * 4T,128G的存储机型,每个节点跑3个ES实例,每个实例32G内存,4块独立盘。node6到node8为12 * 8T的存储机型,3台服务器跑一个Minio集群,每台机器上的ES实例不做数据本地写。
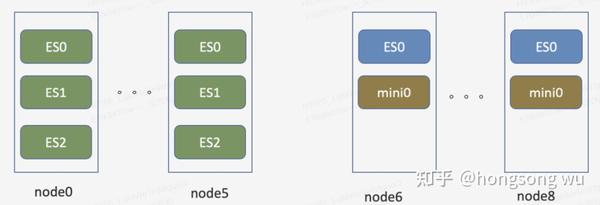
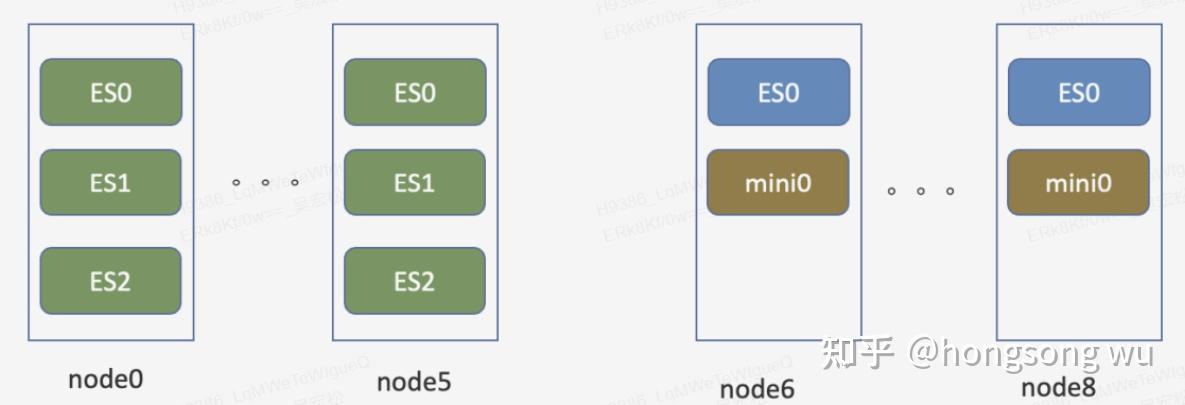
可以看到主要的改造重点是将node6到node8 3个节点进行ES的配置改造,其中以node6节点的配置为例:
cluster.name: ops-elk
node.name: ${HOSTNAME}
network.host: [_local_,_bond0_]
http.host: [_local_]
discovery.zen.minimum_master_nodes: 1
action.auto_create_index: true
transport.tcp.compress: true
indices.fielddata.cache.size: 20%
path.data: /home/nbs/elk/data1/data
path.logs: /home/nbs/elk/data1/logs
- /curvefs/mnt1
xpack.ml.enabled: false
xpack.monitoring.enabled: false
discovery.zen.ping.unicast.hosts: ["ops-elk1:9300","ops-elk7:9300","ops-elk
7:9300","ops-elk8.jdlt.163.org:9300"]
node.attr.box_type: cold如配置所示,主要的改造为调整ES的数据存储目录到CurveFS的fuse挂载目录,然后新增 node.attr.box_type 的设置。在node6到node8上分别配置为cold,node1到node5配置对应属性为hot,所有节点配置完成后进行一轮滚动重启。
- ES设置
除了底层配置外,很重要的一点就是调整index索引的设置。这块的设置难度不高,要点是:
- 对应索引设置数据分配依赖和aliases
- 设置对应的index Lifecycle policy
其实在新节点开放数据存储后,如果没有亲和性设置,集群马上会启动relocating操作。因此建议对存量的索引新增routing.alloction.require的设置来避免热数据分配到CurveFS存储节点。针对每天新增索引,建议加入以下这样的index template配置。
{
"template": {
"settings": {
"index": {
"lifecycle": {
"name": "syslog",
"rollover_alias": "syslog"
"routing": {
"allocation": {
"require": {
"box_type": "hot"
"number_of_shards": "10",
"translog": {
"durability": "async"