


docker和bind mount

说明:本文分析所依据的内核版本是3.10。
前面的文章 提到,在Linux中,一个「文件系统」可以被挂载到多个「挂载点」,即bind mount。文件系统在内核中由 "super_block" 结构体描述,而「挂载」对应的数据结构则为 "mount" 。那这两者是怎么关联起来的呢?
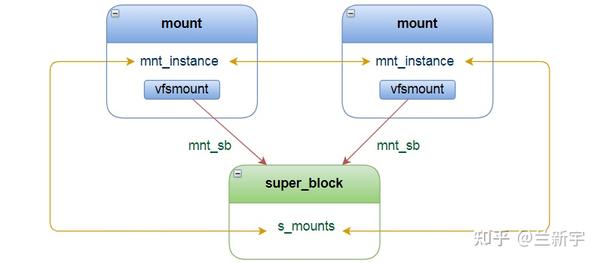

"s_mount"作为链表头,"mnt_instance"作为链表节点,将属于同一文件系统的挂载instance连接起来。而挂载instance通过内嵌的 "vfsmount" 中的"mnt_sb",指向了其所属的文件系统。
对于docker应用,若采用overlay2作为storage driver,则容器内部的根文件系统"/",和主机上的"/var/lib/docker/overlay2/<layer-id>/merged/"目录是bind mount的关系。那当我在内核里获取了一个容器内部文件的"dentry"或者"inode"信息,如果找到其在主机上对应的文件路径呢?
借助crash utility来做个实验。在同一文件系统内,inode号是文件的唯一标识,其在用户态也很容易查询到("ls -i"命令),但要想获得一个文件的inode指针,通过inode号是不行的,因为只有当文件被加载到内存,才拥有内存inode信息。
可以采用的方法是使用"files <pid>"命令,查看被一个进程打开的文件信息。不过对于运用了 PID namespace 的docker,其内部看到的PID号可不是主机上的crash工具能识别的。一个比较简单的方法是使用"docker top <container>"命令,获取容器内部进程在主机上真实的PID。


通过"inode"找到其所在的"super_block",验证了下其文件系统类型为 "overlay" ,确实没错。接下来就是遍历上面提到的链表了,crash工具为我们提供了 "list"工具 来专门干这种事。
在Linux内核的实现中, 双向链表 通常是内嵌在一个结构体中的,据此大致可分为两种类型:一种是链表节点所在的结构体,而其他节点所在的结构体是相同的,一种就是本文的这个案例,链表头和链表节点所在的结构体不同。
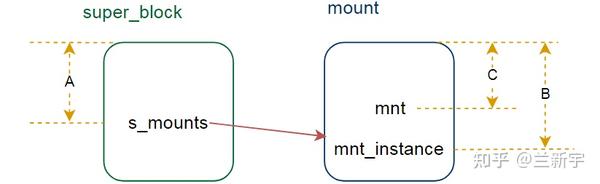
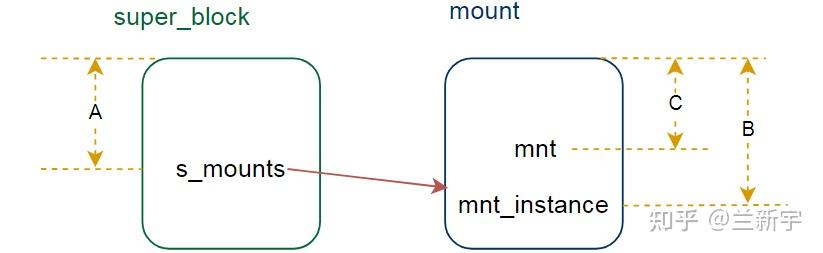
所以,一是要获取头节点的地址(A),二是要获取其他节点在其结构体中的偏移(B),如果要进一步获取其所在结构体中另一个元素的值(C),还需要知道这“另一个元素”在结构体中的偏移。
先来拿一下链表头的地址:


然后开始遍历,查询下"vfsmount"的信息:
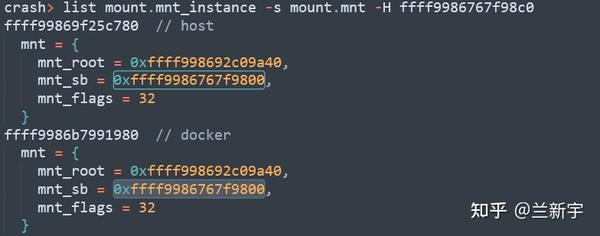
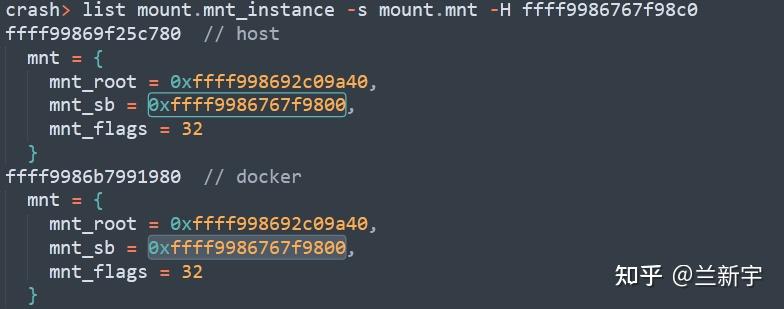
这里,"-H"是指明起始地址A,"mount.mnt_instance"是B的偏移,而"-s"后面跟的"mount.mnt"就是C的偏移。
可见,两个挂载instance,一个来自主机,一个来自docker内部(笔者这里有根据后面的分析提前标注),其内嵌的"vfsmount"都指向同一个"super_block",也就是第一回合已经找到的"0xffff9986767f9800"。
当然,这只是验证下有没有找错,我们的目标其实是"mnt_mountpoint"指向的"dentry"信息:
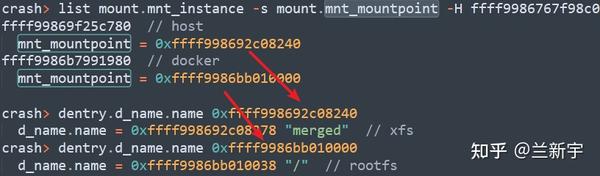
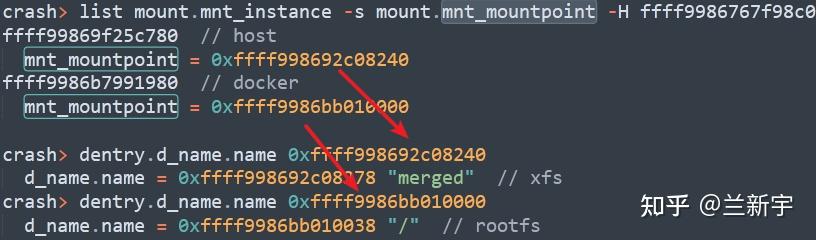
一个"dentry"的名称是"merged",所属文件系统类型是xfs,这无疑就是主机上的那个路径了,这个"dentry"的"parent"的名称,就是那常常的一串layer id。而另一个"dentry",指向的则是docker内部的根文件系统。
回到开始提的那个问题,当获得了容器内部文件的"dentry",可以通过其所在文件系统的"super_block",遍历所有挂载instance,找到这个bind mount的其他挂载路径(包括主机上的)。
追踪docker容器的启动
在docker内部查看"/proc/self/mountinfo",可以获得类似下图的信息:


这个"master:303"是啥呢?回到主机上,也用"/proc/self/mountinfo"看下(此"self"非彼"self"哈):


这其实是bind mount的其中一种形式,决定了参与bind mount的两个目录各自的修改是否对彼此可见(称为"propagate"),因此还有互不可见的"private"类型,单向可见的"slave"类型等,以及……这些类型的一些组合。
你会发现,除了这个docker内部根文件系统的bind mount,"mountinfo"还包含了其他很多的文件系统挂载信息。我们可以使用"strace"工具来追踪一个docker容器的启动过程,一探究竟。
不过,如果你直接使用下面这条命令,是不会有什么收获的:
strace docker run ...
至于原因嘛,还得从docker的架构说起。docker采用经典的的client-server模型,其中server可以在本地,也可以在远端。当在命令行输入"docker xxx"的命令时,其实是向作为server的docker engine发送了一个管理容器的请求。
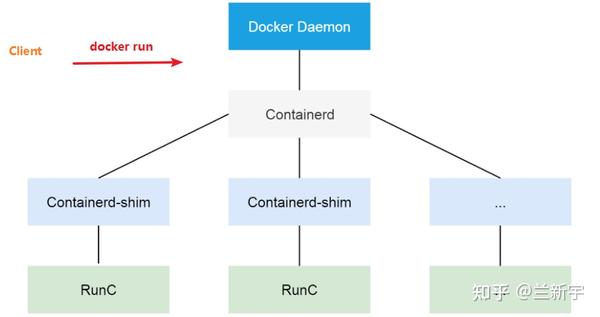
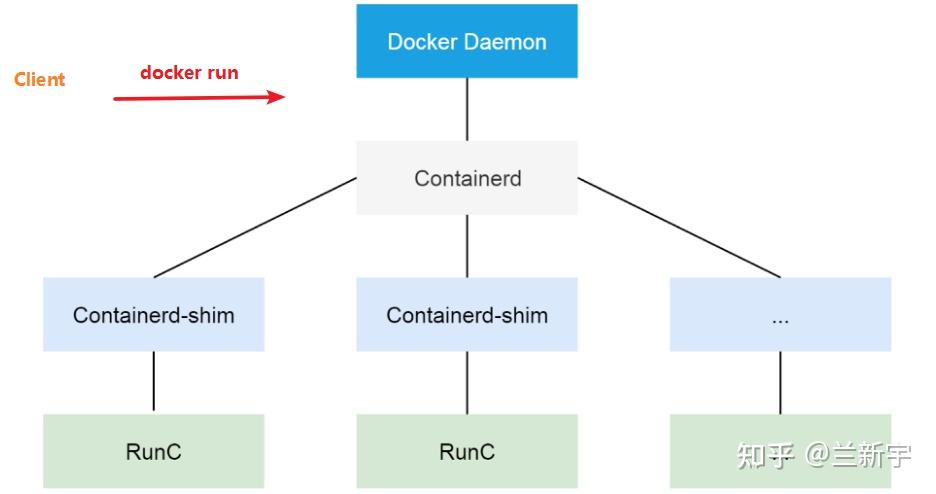
早期的的docker engine采用单体结构,后面逐渐将"containerd"和runtime分离出来,这样做的好处是:在docker daemon出现downtime的时候,底层运行的容器实例可以不受影响。要不然像docker这种版本发布比较频繁的,每次升级都会造成容器停止运行,多影响业务。
这里展现的架构上的树形结构,其实也对应了进程的树形继承关系。以Docker 19.03.0版本为例,使用"pstree"命令,可以看到类似这样的输出:


containerd才是真正负责容器创建的,所以正确的方式是在一个终端启动strace("-f"代表追踪子进程),然后另一个终端启动docker容器创建的命令。
strace -e trace=mount -f -p 977
其输出的内容基本就是容器启动后,内部可能挂载的文件系统列表了,可以看看这些"mount"系统调用里,哪些参数是含有 "MS_BIND" 的。
小结
在docker的文件系统实现里,大量运用了bind mount这项Linux中古老而又颇有特点的挂载方式,并且由于容器的namespace隔离属性,其bind mount的目录还是跨越mount namespace的。但实际上,bind mount是完全可以在同一个mount ns内单独使用的,只不过呢,配上mount ns,它才往往有更多的应用场景和实用价值。
参考:
原创文章,转载请注明出处。
